Evento del proyecto especial del equipo de OCS Soft: "PROdemo: Laboratorio de soluciones de software". En él participan Alexander Kalinin, preventa de copias de seguridad en OCS, y Alexander Savostyanov, experto técnico de OCS, quien hará una revisión de la arquitectura, hablará sobre los escenarios de uso del producto y también demostrará los elementos principales de la interfaz de gestión, el funcionamiento del almacenamiento de datos definido por software y el subsistema de virtualización.

Hoy van a hablar sobre ciberinfraestructura. ¿Recientemente actualizamos nuestro diseño corporativo? Además, hemos actualizado nuestro sitio de demostración. Aquí se pueden ver los stands de demostración que tenemos en diferentes áreas. Todos ellos están implementados en base a nuestro centro de datos.

Tres sitios, 65 servidores, 14 TB de memoria operativa y buenas redes, almacenamiento normal de datos, tenemos tarjetas gráficas. Y a estos stands damos acceso remoto a través de la tecnología VDI.

Para nuestros socios ofrecemos una serie de actividades como el análisis de requisitos técnicos, demostración de soluciones, selección de soluciones, pilotos e implementación. Realizamos diversos seminarios, cursos de formación, webinars. Aquí hay stands para el estudio independiente. A veces preparamos stands individuales según los requisitos del cliente y proporcionamos equipos de demostración.
Dos grandes secciones: virtualización y seguridad de la información. Y aquí hay una gran cantidad de plataformas diferentes. Lo principal es que en este stand se puede pulsar el botón "Más información", ver algunas capturas de pantalla de la consola de gestión, ver qué escenarios de demostración hay, de qué consta el stand, y también se puede pulsar el botón "Reservar". A nuestro Telegram llegará su deseo, y nos pondremos en contacto con usted y aclararemos qué es lo que quiere probar concretamente, qué plazos le convienen, etc.
Luego tomó la palabra Alexander Savostyanov. Primero realizó una pequeña presentación sobre el producto.

La ciberinfraestructura es una infraestructura en la que los recursos informáticos de los servidores y los dispositivos de almacenamiento se combinan a nivel de software. Con este método de presentación, como plataforma de hardware se utilizan únicamente servidores de arquitectura estándar, lo que permite crear una infraestructura de cualquier escala para resolver un mayor número de tareas de TI.
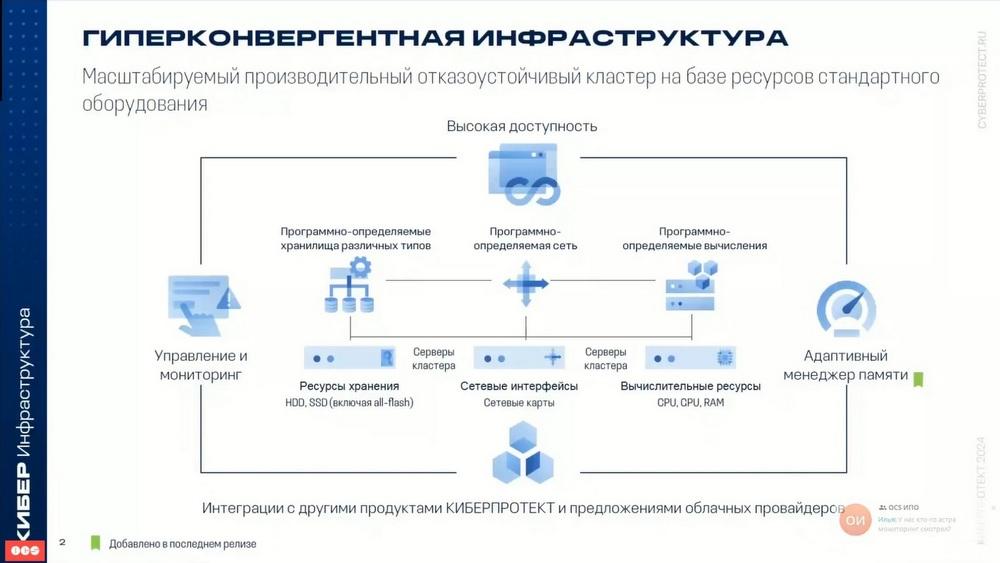
En la base de la ciberinfraestructura se encuentra una idea muy simple. Se toman servidores, que pueden ser de diferentes fabricantes y de diferente configuración. Estos servidores se unen mediante interfaces de red, se conectan a la red externa e interna. La red interna se utiliza para la interacción entre los nodos y para la interconexión del clúster, y se utiliza para el almacenamiento de datos. En el "hardware desnudo" se instala un software que une estos servidores en un clúster fiable, productivo y tolerante a fallos. Todos los recursos de estos servidores (potencia de cálculo, memoria y almacenamiento) se combinan en un único pool. La ciberinfraestructura se basa en el sistema operativo Linux. La distribución incluye el sistema operativo, aunque existen opciones en las que se puede instalar el sistema operativo por separado, y el propio programa de software de la ciberinfraestructura, ya se instala sobre el sistema operativo. Sin embargo, lo más frecuente es que todo esto se instale simultáneamente. Un único clúster de servidores unidos se escala fácilmente añadiendo nodos y discos individuales.
En la diapositiva vemos que la ciberinfraestructura incluye almacenamiento definido por software de varios tipos, red definida por software y computación definida por software. Todo esto se gestiona desde una interfaz web, desde una línea de comandos, y existen sistemas de gestión y monitorización.
El componente principal y con lo que empezó este producto hace bastante tiempo, es el almacenamiento definido por software.
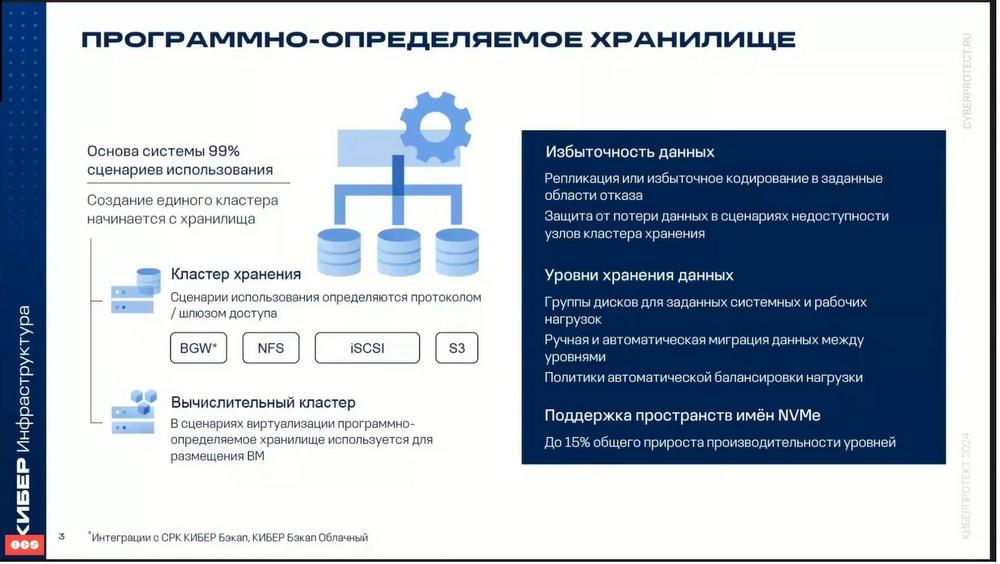
La ciberinfraestructura permite crear varios tipos de almacenamiento con acceso a través de los protocolos NFS, iSCSI y S3. Además, para la integración con otros productos de Cyberprotect, productos de copia de seguridad, como CIBER Backup Cloud y Cyber Backup, también se utiliza un almacenamiento especial, que se designa con la abreviatura BGW (Backup Gateway). De este modo, se admiten varios tipos de almacenamiento. Almacenamiento S3 para almacenar un número ilimitado de objetos y archivos, aunque existen ciertas limitaciones, aunque son un poco de marketing. También se utilizan y recomiendan los almacenamientos de bloques iSCSI para la virtualización de bases de datos y otras cargas de trabajo. Como ya se ha dicho, también se puede utilizar un almacenamiento adicional como puerta de enlace de copia de seguridad, que está destinado al sistema de copia de seguridad. La creación de sistemas de almacenamiento de archivos, bloques y objetos se consigue combinando los dispositivos de almacenamiento en un único pool. Es decir, los recursos de disco de cada uno de los servidores se añaden a este único pool y, de este modo, se combinan en un único almacenamiento.
Uno de los tipos de almacenamiento más populares actualmente es el almacenamiento de objetos. La ciberinfraestructura permite exportar el espacio de disco del clúster en forma de almacenamientos compatibles con S3.
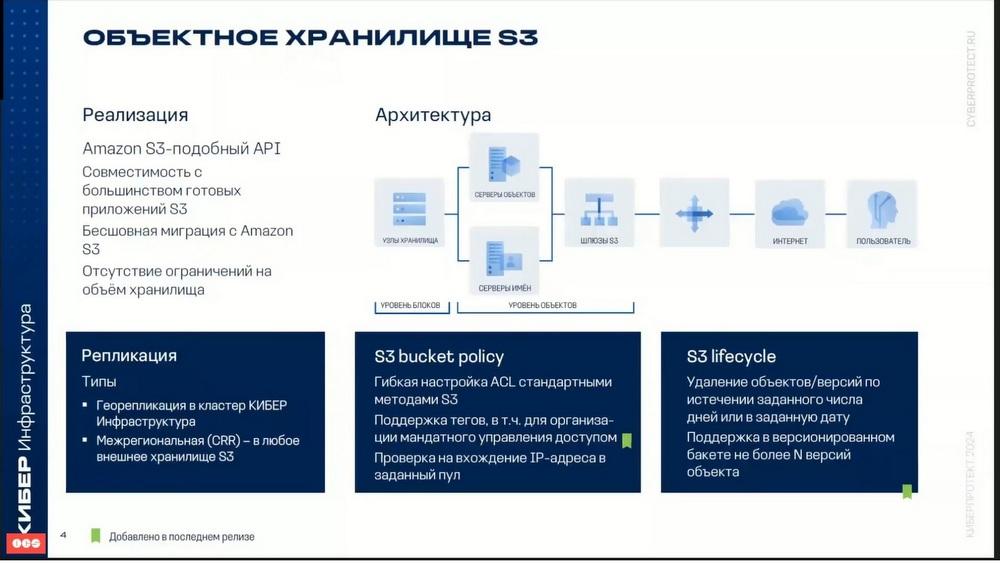
Los almacenamientos de objetos están optimizados para almacenar miles de millones de objetos, datos y aplicaciones, se pueden almacenar objetos de varios contenidos web estáticos, datos de servicios de almacenamiento en línea, big data, copias de seguridad, etc. La diferencia clave en comparación con otros tipos de almacenamiento que se utilizan en la ciberinfraestructura, es que las partes de un objeto no se pueden modificar. Es decir, al modificar un objeto, se forma su nueva versión. La ciberinfraestructura puede almacenar réplicas de datos del clúster S3 y mantenerlas actualizadas en varios centros de procesamiento de datos distribuidos geográficamente. Es decir, existe la posibilidad de georreplicación de un almacenamiento a otro. De este modo, se pueden utilizar para la resistencia a desastres de los datos.

Almacenamientos de bloques y archivos. En primer lugar, tiene sentido hablar de iSCSI y NFS. Estos son los principales sistemas adicionales de tipo almacenamiento. Se recomienda utilizar iSCSI para la virtualización de bases de datos y otras cargas de trabajo. Por ejemplo, bases de datos y sistemas transaccionales. El intercambio de datos con el almacenamiento se produce rápidamente gracias a la alta velocidad de lectura y escritura. Para aumentar la velocidad se pueden utilizar medios adicionales, como RDMA, que funciona sobre InfiniBand, pero esto es precisamente para garantizar un alto rendimiento del almacenamiento.
Los almacenamientos de archivos NFS se pueden utilizar para almacenar cualquier tipo de datos corporativos con acceso a través de NFS. El propio almacenamiento NFS se basa en el almacenamiento de objetos, y se puede escalar a miles de millones de entidades. Tiene un alto rendimiento, pero para utilizar un almacenamiento donde se requiere un alto rendimiento de entrada/salida, se recomienda utilizar iSCSI, no NFS.
Otro tipo de almacenamiento es la puerta de enlace de copia de seguridad. Los sistemas de copia de seguridad Cyber Backup y Cyber Backup Cloud, en el marco de las tareas de copia de seguridad y replicación, transfieren las copias de seguridad a la puerta de enlace. De este modo, la propia ciberinfraestructura se puede utilizar como almacenamiento de copias de seguridad, o se puede utilizar como puerta de enlace para poder utilizar la puerta de enlace para almacenar dentro del propio almacenamiento la copia de seguridad, o se puede utilizar la puerta de enlace como una especie de caché, que se utilizará para transferir datos a un sistema de almacenamiento externo. Esto puede ser S3 o NFS. ¿Cómo funciona? La puerta de enlace se utiliza como caché. Los datos primero llegan a la puerta de enlace, y luego ya llegan al almacenamiento externo S3 o NFS.
Para la protección de datos se utiliza la redundancia en el almacenamiento. Se utilizan dos tecnologías. Una tecnología se llama replicación, la otra es la codificación redundante.
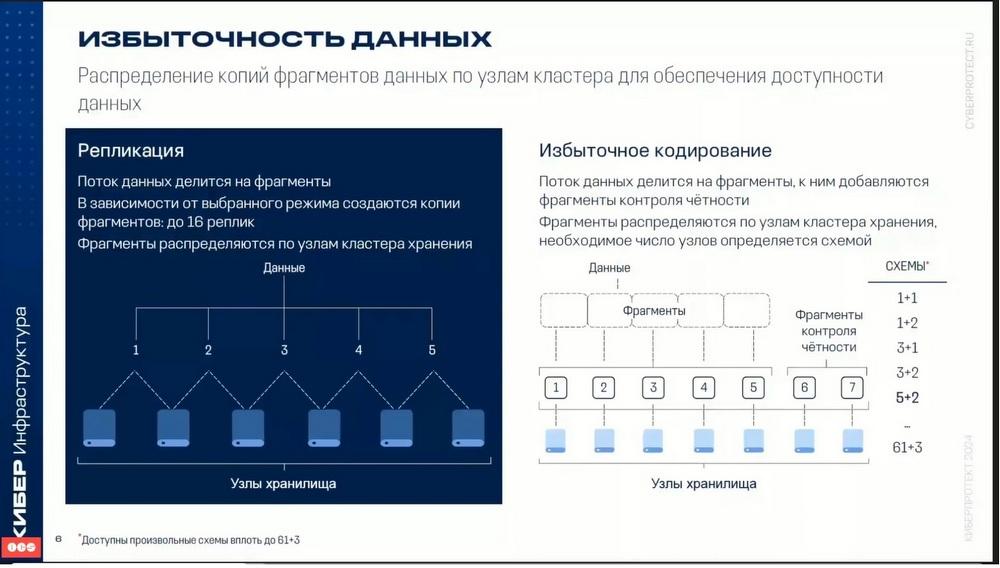
La replicación es, en esencia, la duplicación de datos. La replicación funciona de la siguiente manera: el flujo de datos se divide en bloques separados, cada uno de los cuales se guarda en dos o tres lugares en otros servidores. De este modo, se produce una redundancia de datos, ya sea un 100% o un 200% de redundancia de datos, pero al mismo tiempo se consigue la máxima protección contra fallos. La codificación redundante o, en inglés, RG-coding, es un mecanismo de división de flujos en bloques separados según un determinado esquema de redundancia. Se utilizan varios esquemas: 1+1, 1+2, 3+1, 3+2, 5+2,…, 61+3. Qué esquema utilizar depende de la elección de varios criterios. Se puede utilizar con la máxima fiabilidad de fallo de dos o más nodos, o se pueden considerar esquemas de mayor rendimiento.
Áreas de fallo. La alta disponibilidad de los sistemas se garantiza mediante ajustes flexibles, entre los que se pueden destacar las áreas de fallo.
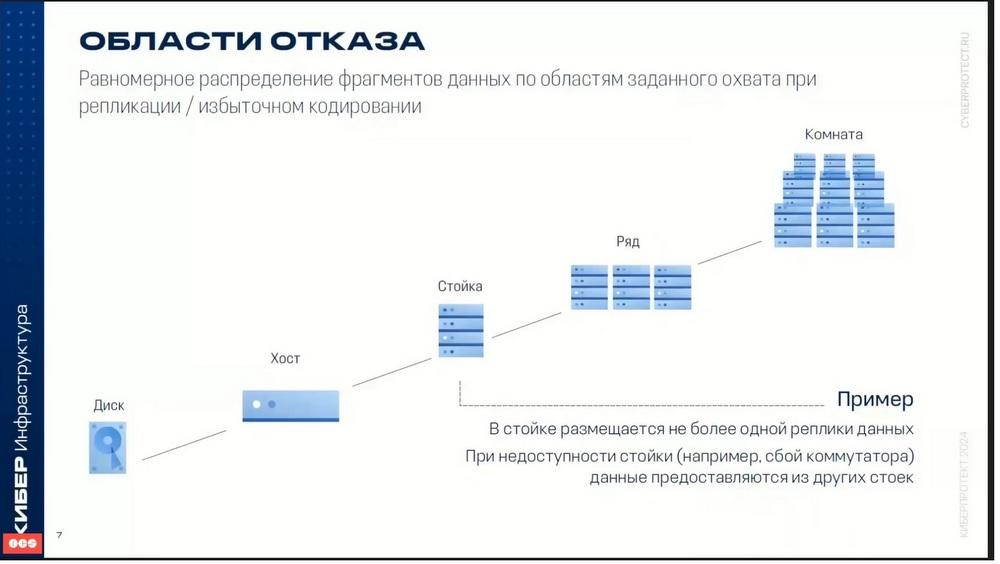
Como zona de fallo se puede elegir un disco, un host, un servidor o incluso un rack entero. En este caso, los datos se distribuyen entre los componentes individuales del mismo nivel. Es decir, entre discos, entre servidores, pero lo más frecuente es que esto ocurra precisamente entre servidores. Voy a mostrar dónde se distribuyen los datos entre diferentes servidores. De este modo, el fallo de uno o incluso dos servidores no provoca la pérdida de datos. En caso de fallo de algún componente, por ejemplo, un servidor, los datos que estaban en este servidor se redistribuyen a otros servidores. Es decir, si en el servidor que ha fallado había algunas copias de datos, estas copias de datos se distribuirán a otros servidores de forma que se respete el nivel de tolerancia a fallos. Es decir, si el nivel de tolerancia a fallos, por ejemplo, réplicas, dos o tres, los datos se redistribuirán de forma que se garantice el nivel de protección de datos necesario. Y, por supuesto, esto también depende de si hay espacio libre en el clúster.
La ciberinfraestructura permite distribuir los datos en varios niveles de almacenamiento e incluso equilibrar los datos automáticamente. El sentido es que se pueden distribuir diferentes cargas de trabajo en diferentes niveles de almacenamiento.
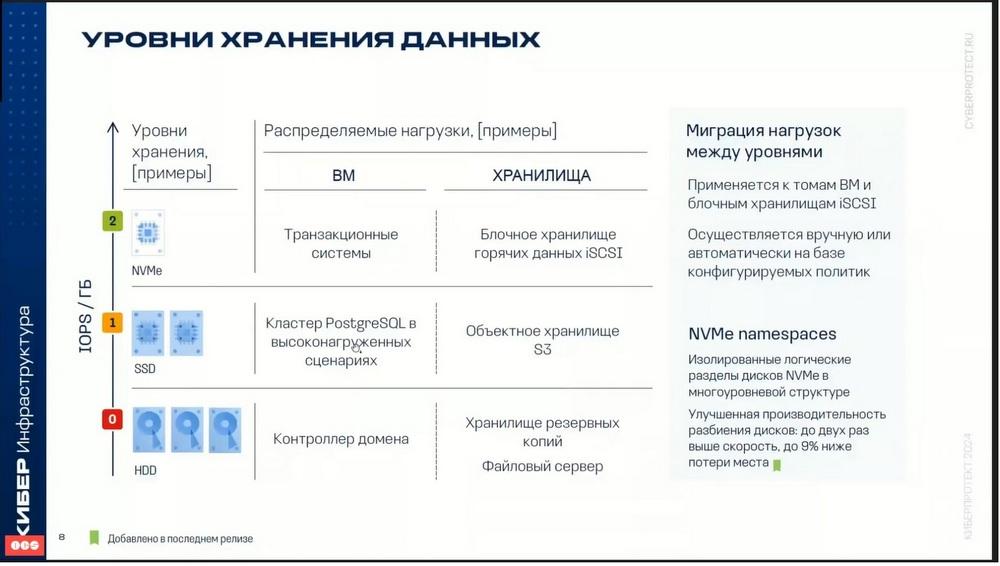
Supongamos que en esta diapositiva se puede ver que las cargas transaccionales o los datos "calientes" se pueden distribuir en el nivel donde se encuentran los discos NVMe. El siguiente nivel son los discos SSD. En él, por ejemplo, se pueden ubicar los datos de las bases de datos o los datos del almacenamiento de objetos. En el tercer nivel están los discos más lentos. En este nivel se pueden almacenar, por ejemplo, copias de seguridad o algunos archivos "fríos".
Si hablamos de los aspectos técnicos de la configuración, se encontrarán con que a los discos que están en el servidor se les asignan diferentes roles.

El primer rol, el disco del sistema, es necesario para instalar el sistema operativo y el software. El segundo nivel es el servidor de metadatos. Los servidores de metadatos son responsables de la información de los datos sobre el clúster, rastrean los fragmentos de datos, el estado, etc. El servidor de metadatos debe ser obligatoriamente más de uno. Se recomiendan dos o más servidores. El tercer nivel es el almacenamiento en caché. Algunos discos se pueden asignar como caché. Por ejemplo, si utilizamos discos HDD convencionales como discos de almacenamiento principales, se puede utilizar un SSD como caché para aumentar el rendimiento. El último nivel es el servidor de fragmentos, que desempeña el papel de almacenamiento.
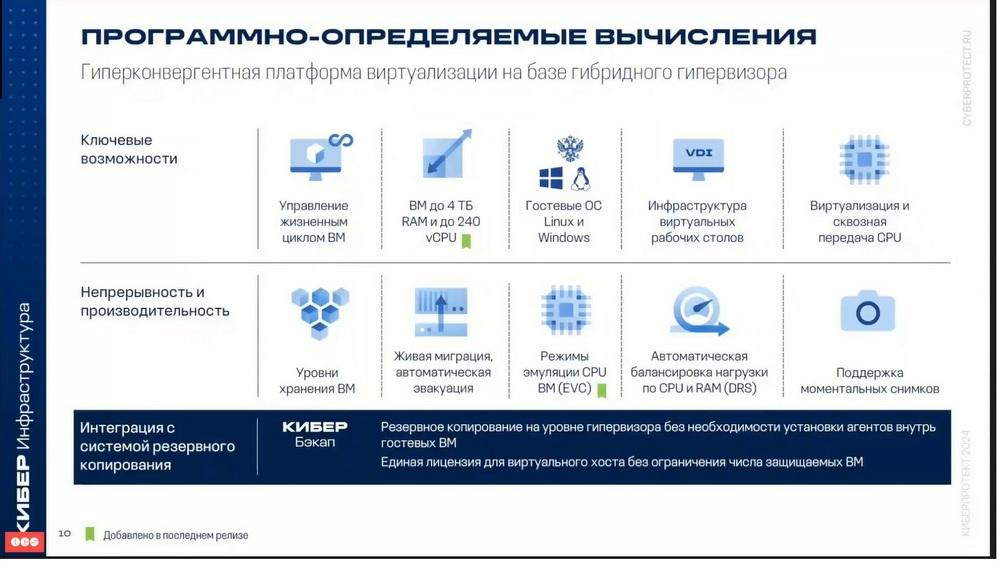
Ahora pasamos a la computación definida por software. La ciberinfraestructura incluye una plataforma de virtualización. Es decir, sobre el almacenamiento se puede desplegar una plataforma de virtualización. Como plataforma de virtualización se utiliza OpenStack. Y aquellos que estén familiarizados con las capacidades de OpenStack, se convencerán inmediatamente de que todas las capacidades de este producto están presentes. Para el almacenamiento de máquinas virtuales que se crean como almacenamiento, se utiliza el propio almacenamiento de la ciberinfraestructura o un almacenamiento externo.
Como sistemas operativos invitados, naturalmente, pueden actuar varios sistemas operativos de la familia Windows, así como de la familia Linux. El producto posee todas las propiedades y funciones básicas que debe tener un sistema de virtualización moderno. Se admite todo el ciclo de vida de las máquinas virtuales. Es decir, la creación de plantillas, el encendido y apagado, la transferencia de máquinas entre nodos. En el producto se han implementado todas las funciones básicas, además de algunas capacidades adicionales que no todos los sistemas de virtualización poseen. Por ejemplo, se pueden establecer reglas de almacenamiento y políticas de almacenamiento de máquinas virtuales. Si una máquina virtual requiere un alto rendimiento, se puede ubicar en un determinado nivel de almacenamiento que posea un mayor rendimiento de entrada/salida. Y se puede, y esto se puede establecer en la configuración de la máquina virtual, hacer que en el futuro, durante la migración entre nodos, esta máquina virtual pueda ubicarse en otro nivel.
El sistema de virtualización garantiza una alta disponibilidad de las máquinas virtuales. Es decir, si falla un nodo del servidor en el que estaba funcionando una máquina virtual, ésta puede ser evacuada a otro nodo. Para la transferencia de máquinas virtuales entre nodos existen modos de migración tanto fría como caliente. En una de las últimas versiones se introdujo la posibilidad de DRS, que es la posibilidad de equilibrar la carga de CPU y memoria. Esta capacidad permite mover automáticamente, sin detenerse, las máquinas virtuales entre los servidores de virtualización para aumentar el rendimiento. Esto también se configura. El administrador puede, por ejemplo, excluir máquinas individuales de este proceso o, por el contrario, incluirlas.
Se admite el mecanismo de creación de instantáneas. Hay que decir que en la última versión también se incluyó la característica de que sobre el sistema de virtualización se podía desplegar la virtualización de escritorios, es decir, la infraestructura VDI de escritorios. Estas son las capacidades básicas.
En cuanto a la ubicación de los discos de las máquinas virtuales.
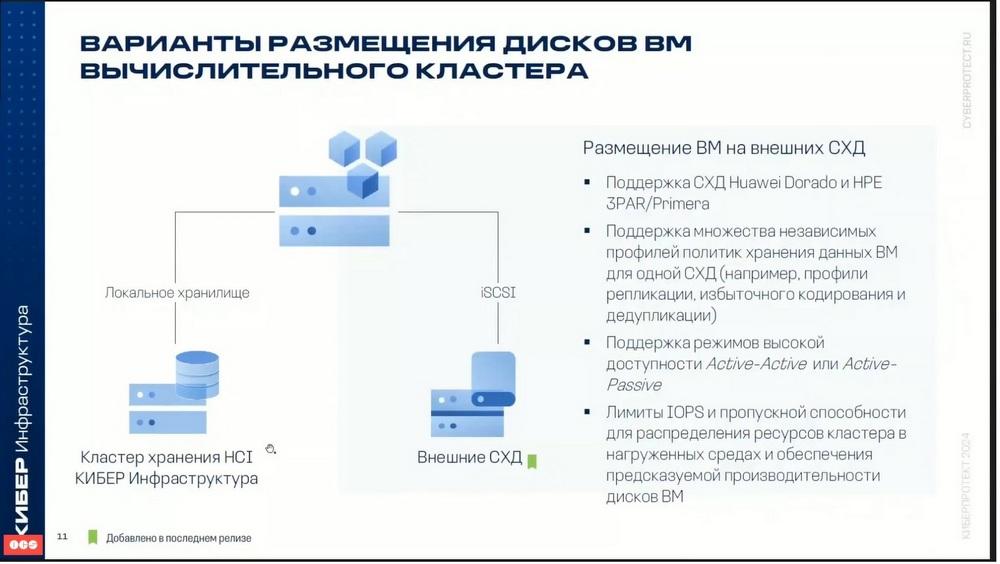
Lo más sencillo y evidente es cuando los discos de las máquinas virtuales se almacenan en el mismo almacenamiento de la ciberinfraestructura. Pero también se pueden utilizar en ella discos de almacenamiento externo. Esto se añadió en la última versión. Actualmente se admiten dos sistemas de almacenamiento. Estos son Huawei Dorado y HPE 3PAR. Funciona igual que en VMware. Un análogo de lo que en VMware se llamaba Vivo. Es decir, en el sistema de almacenamiento, a través de la API, la ciberinfraestructura puede crear los discos necesarios y conectarlos a la máquina virtual en los sistemas de almacenamiento externos a través de la API. Así es como funciona.
En las próximas versiones se planea admitir el protocolo Fibre Channel. Actualmente sólo se admite iSCSI, pero esta tecnología se seguirá desarrollando. Muchos clientes lo preguntan. Por lo tanto, habrá una próxima versión con soporte para el protocolo Fibre Channel, para que se pueda conectar externamente desde HD a través de la interfaz Fibre Channel.
Migración entre plataformas. La ciberinfraestructura realiza la migración de máquinas virtuales desde VMware, Hyper-V al interior de la ciberinfraestructura mediante un appliance virtual. El appliance virtual se llama V2V appliance para la transferencia de máquinas virtuales. La migración de máquinas virtuales desde VMware está disponible en modo autónomo y en modo online. La migración de máquinas virtuales Hyper-V sólo está disponible en modo autónomo.

Red definida por software. Como ya se ha dicho, el sistema de virtualización se basa en el producto OpenStack. Por lo tanto, muchas cosas son conocidas y comprensibles para aquellos que están familiarizados con cómo está estructurado OpenStack.
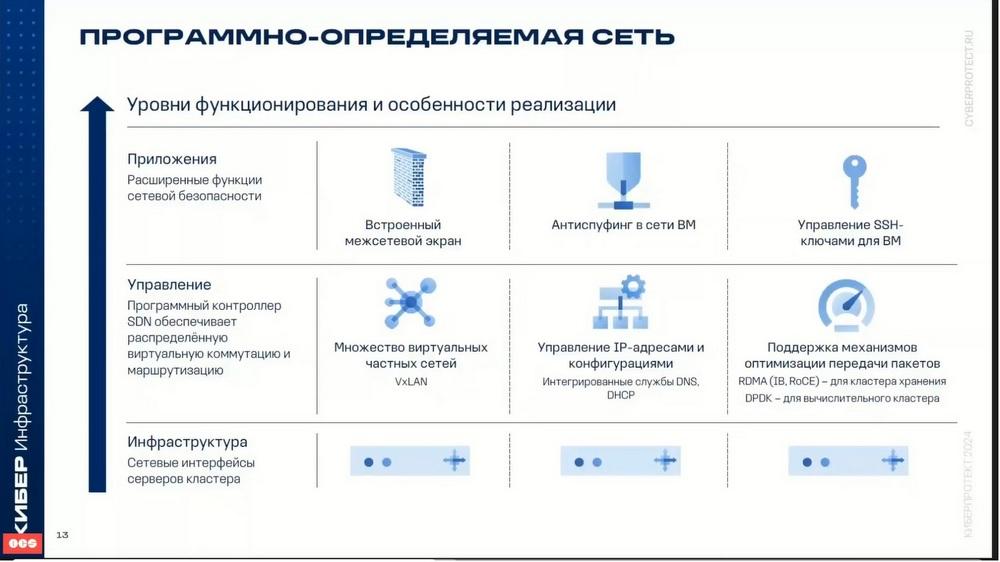
La ciberinfraestructura admite la conmutación virtual basada en OpenViSwitch. El conmutador OpenViSwitch se ejecuta en cada nodo de cálculo, redirige el tráfico de red entre las máquinas virtuales en este nodo, así como entre las máquinas virtuales y las redes de la infraestructura, es decir, entre otros nodos. La conmutación virtual distribuida proporciona una supervisión centralizada, la gestión de la configuración en todos los nodos del clúster de cálculo. El enrutamiento virtual distribuido permite ubicar enrutadores virtuales en los nodos de cálculo y redirigir el tráfico de las máquinas virtuales directamente desde los nodos de ubicación. En el escenario se utiliza una dirección IP directamente asignada a la interfaz de red. Si se utiliza S, el tráfico se redirige a través de los nodos de gestión. Como es sabido, la tecnología dentro de OpenStack, al igual que en la ciberinfraestructura, utiliza tecnologías VxLAN para las redes virtuales. Esta tecnología permite crear redes lógicas L2 en redes L3 mediante la encapsulación sobre paquetes UDP. También hay integración con los servicios DNS y DHCP. Se puede utilizar RDMA sobre InfiniBand para el clúster de almacenamiento, para la organización de la red interna del almacenamiento. La red interna del almacenamiento se utiliza precisamente para la organización del almacenamiento. Se puede construir sobre la base de RDMA.
También, al igual que en OpenStack, en la ciberinfraestructura es posible utilizar una arquitectura multiinquilino, que se utiliza en la construcción de nubes privadas y públicas.
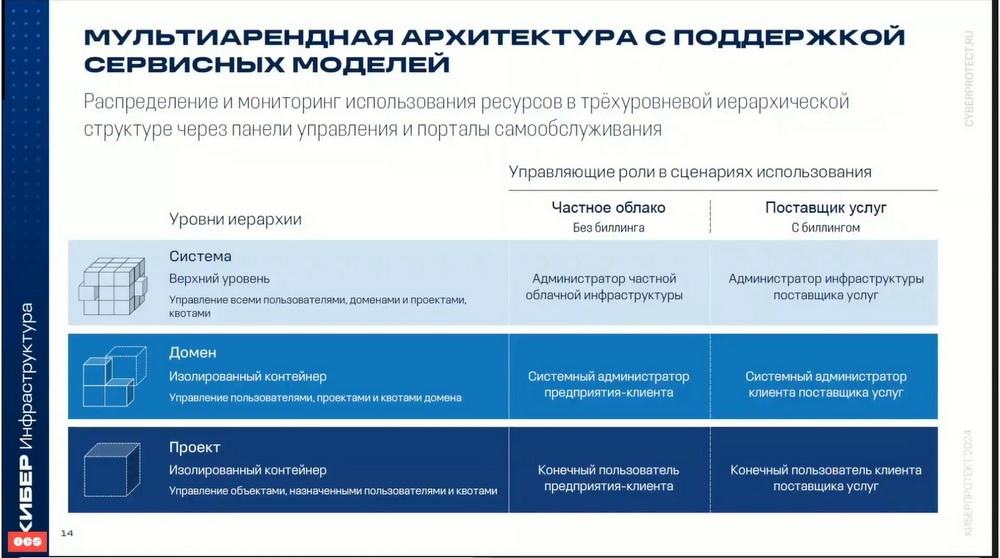
En la ciberinfraestructura se utiliza una jerarquía administrativa de dominios y proyectos. Los proyectos también se denominan "tenants" con control de acceso basado en roles para la gestión de objetos virtuales del clúster de cálculo, tales como máquinas virtuales, volúmenes, redes virtuales. Un dominio representa un contenedor aislado de proyectos y usuarios con roles asignados. Cada proyecto y usuario puede pertenecer sólo a un dominio. Un proyecto representa un contenedor aislado de objetos virtuales con usuarios asignados y determinadas restricciones establecidas para los recursos virtuales, tales como procesadores centrales virtuales, RAM, almacenamiento y direcciones IP flotantes.
De acuerdo con estos niveles, en el producto se prevén tres roles de usuarios: administrador del sistema, administrador del dominio y participante del proyecto.
Continuidad del trabajo. La alta disponibilidad garantiza el funcionamiento de los servicios de la ciberinfraestructura incluso en caso de fallo de un nodo.
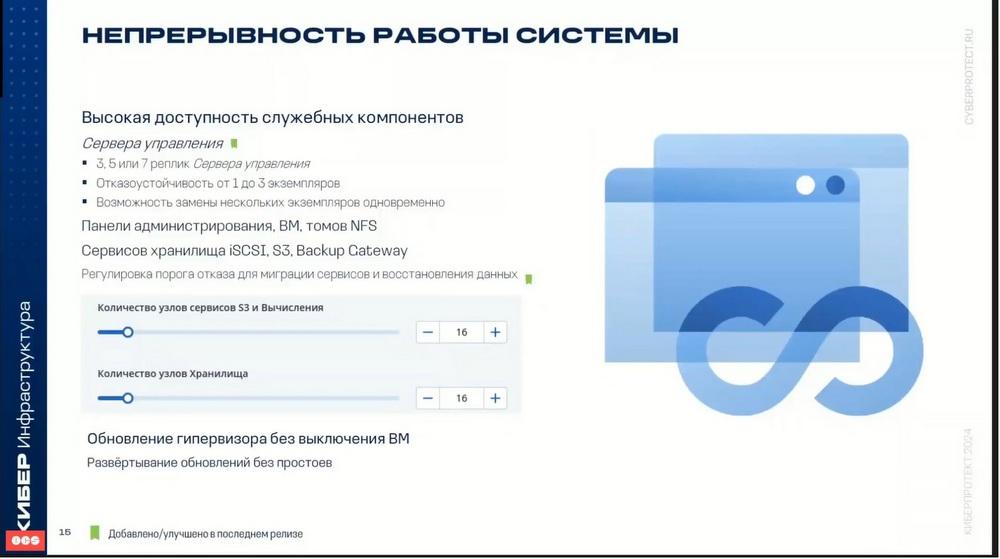
En caso de fallo de algún nodo, los servicios que funcionaban en este nodo se transfieren a los nodos en buen estado de acuerdo con el algoritmo de consenso RAFT, que se utiliza precisamente para la tolerancia a fallos en el sistema en caso de fallo. ¿Con qué métodos se logra la alta disponibilidad? En primer lugar, la redundancia de los metadatos. Para un funcionamiento fiable es necesario configurar varios servidores de metadatos. Para que, en caso de fallo de uno, otros nodos retomen este trabajo. La redundancia de los propios datos es el segundo método, que también se utiliza para garantizar la continuidad y la protección de los datos.
La ciberinfraestructura garantiza una alta disponibilidad de todos los servicios. Se refiere al panel de administrador. El servidor de gestión normalmente se agrupa en clústeres, y normalmente en el sistema existen varios servidores de gestión.
Máquinas virtuales. Si una máquina virtual falla, la ciberinfraestructura, el propio sistema de virtualización, transfiere esta máquina a otros nodos libres. Los servicios iSCSI, I3, S3, Backup Gateway, NFS, todos estos servicios están protegidos contra fallos.

Metroclúster. En una de las últimas versiones apareció la posibilidad de construir un metroclúster, es decir, de separar los nodos de la ciberinfraestructura entre diferentes sitios para excluir la probabilidad de pérdida del sitio por completo.
Administración centralizada.

La administración de la infraestructura se realiza de varias maneras. Para ello, existe una herramienta principal: la interfaz web, la línea de comandos, la llamada interfaz vinfra CLI y también la API de OpenStack, la interfaz de programación de OpenStack. La consola web es la interfaz visual principal para administrar el clúster de cómputo y el clúster de almacenamiento. A través de la consola web, se puede administrar servidores, redes, usuarios, autoservicio, roles, seguridad, etc.
La interfaz de línea de comandos Vinfra sirve para administrar el clúster de almacenamiento y el clúster de cómputo. Admite una sintaxis unificada y varios formatos de comandos.
Y, por último, OpenStack, el programa de interfaz de administración, permite implementar ciertas capacidades de administración.

El sistema de monitoreo sirve para rastrear el rendimiento de la infraestructura y sus componentes. Incluye la recopilación automatizada de métricas de todos los componentes del sistema: servidores, discos, redes, almacenamientos, servicios de cómputo, etc. La ciberinfraestructura permite ver toda la información sobre servidores, discos, redes, retrasos, rendimiento y administrar los umbrales de valores para las alertas.
También se utiliza la ciberinfraestructura del sistema de monitoreo Prometheus. Y también, con la ayuda de la aplicación web externa Grafana, se pueden ver diagramas detallados para clústeres, servidores, almacenamientos. Y existe la posibilidad de crear sus propios paneles de monitoreo y diagramas.
Requisitos de hardware recomendados. Aquí se presentan los requisitos mínimos y los recomendados.
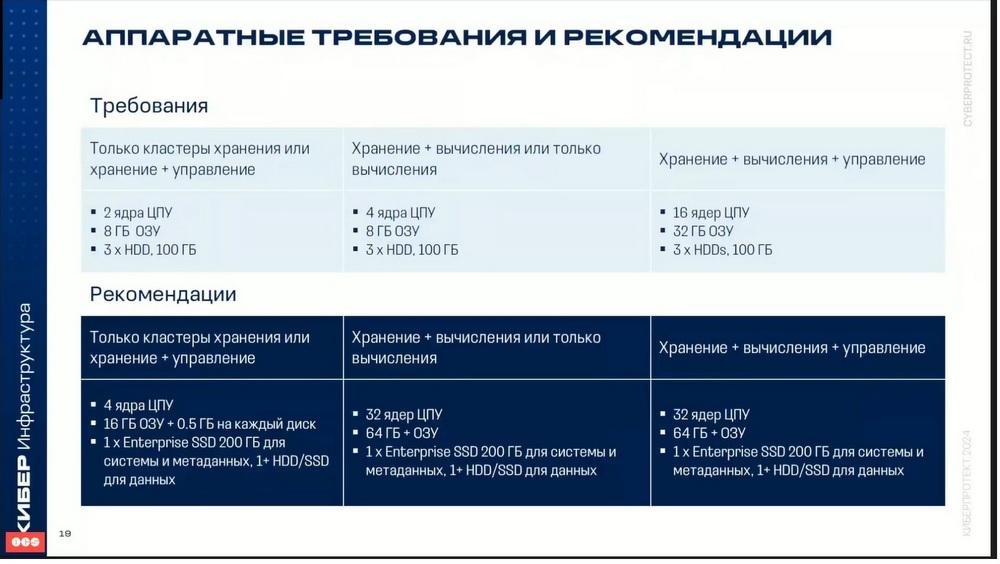
Hay que decir que, para elegir qué servidores utilizar, es necesario realizar un cierto dimensionamiento. Para evaluar el dimensionamiento, es necesario comprender si en este clúster solo habrá almacenamiento o si habrá simultáneamente almacenamiento e infraestructura de cómputo, es decir, se levantará la virtualización. Para determinar, por ejemplo, qué cantidad de CPU y memoria tomar, también es necesario comprender si será nuevamente una pieza de almacenamiento o virtualización. Si va a ser virtualización, entonces es necesario evaluar un cierto volumen límite de procesadores virtuales que se necesita para la virtualización y un volumen límite de memoria. Para el almacenamiento, es necesario comprender qué tipos de almacenamiento de datos se utilizarán, es decir, qué servicios funcionarán. Cada servicio requiere ciertos parámetros propios.

Licenciamiento. El almacenamiento se licencia por terabytes, y se licencia precisamente el espacio útil. En cuanto a la virtualización, se licencia por la cantidad de sockets del servidor. Cabe decir que, para implementar en un entorno de prueba, se incluye una licencia gratuita de 1 TB, que forma parte de la versión de prueba.
Ilustraciones proporcionadas por la empresa «Kiberprotekt».