Традиционно DLP-системы строились на принципе - защищать то, о чем знаешь. Но если на минуту допустить мысль о том, что можешь чего-то не знать — моментально обнаруживаешь гигантскую «серую зону» событий, не покрытых политиками безопасности. Это подобно древним морским картам, где половины мира нет, а другая половина населена различными существами и чудовищами. Можно ли безопасно плавать по такой карте?
Во многих DLP-системах дела до сих пор обстоят примерно также, только «серая зона» вместо драконов и русалок населена ложно-отрицательными срабатываниями (ЛОС), нелегитимными бизнес-процессами и ложно-положительными срабатываниями (ЛПС) — «инцидентами», которые таковыми не являются. Чтобы безопасно плавать — знай, куда плывешь.

DLP-система нового поколения тем и отличается от классических, что не оставляет загадок в виде ЛОС, ЛПС и «серых зон». На мероприятии мы погрузимся в тему ЛОС и ЛПС, поделимся рекомендациями по технологиям и методам эффективной работы с «серой зоной» информационных потоков — чтобы вы могли бороться с утечками, а не с ложными срабатываниями.
- Почему вообще появляются ЛОС и ЛПС. И как вендоры классических DLP-систему предлагают решать эту проблему, о которой не принято говорить на рынке
- Как оставить ложные срабатывания в прошлом. Технологии, автоматизация и ML для своевременной актуализации политик ИБ на примере DLP-системы InfoWatch Traffic Monitor.
- Возможности машинного обучения для кластеризации документов против ручного разбора «серой зоны».
Сегодня мероприятие ведет Александр Клевцов, руководитель по развитию продукта InfoWatch Traffic Monitor, компания InfoWatch, и он будет говорить о ЛОС и ЛПС, то есть о ложно-отрицательных и ложно-положительных срабатываниях системы DLP. Почему так важно копаться в том, как на самом деле устроена DLP-система и что здесь можно взять в качестве метрики, чтобы оценить эффективность вашей работы с ним. Мы поговорим про технику, про детали, мы не будем говорить про методологию, культуру безопасности, а про конкретные эти два аспекта. И вот у нас здесь есть прекрасный слайд: как бы видел художник, проблематику DLP-системы, а именно ложно-положительные срабатывания и ложно-отрицательные.

Ложно-положительные срабатывания, когда мы говорим про DLP, это тот момент, когда DLP посчитала что-то нарушением, что нарушением не является. То есть система сработала на какое-то событие, на какой-то факт, посчитав его нарушением, но нарушения не было. Ложно-отрицательное срабатывание, это когда система что-то пропустила. Произошел какой-то инцидент, нехорошая вещь, но DLP-система промолчала.
Тут я постараюсь как бы свергать каких-то идолов с пьедестала и подвергну сомнению три базовые технологии DLP-системы. Это регулярные выражения, цифровые отпечатки и лингвистические словари.

Говоря про ЛОС и про ЛПС, есть у меня один рецепт, как бороться с такими срабатываниями. Это переход от контентного анализа к контекстному. Контентный анализ - это когда система может детектировать номер кредитной карты, понять, что вот эта переписка про логистику, хорошо определяет тематику, структуру присылаемых данных, а контекстный анализ, помимо того, что он позволяет детектировать какие-то данные, он еще и понимает бизнес-контекст. Приведем элементарный пример, что имя, фамилия, отчество и номер телефона это может быть просто подпись в письме или кто-то присылал контакт сотруднику, чтобы с ним взаимодействовать. И это может быть контакт ключевого клиента. Важно понимать, что это не просто телефон и ФИО, а нужно понимать, что это телефон и ФИО, например, VIP-клиента. И сегодня все мероприятие будет исключительно об этом, как перейти от контентного анализа, где мы просто понимаем какие-то структуры данных, принадлежность к той или иной категории, к контекстному, когда мы понимаем не только категорию данных, но и ее ценность, ее важность для бизнеса, с учетом документооборота или бизнес-процесса.
Регулярные выражения
Переход от контентного анализа к контекстному. И все это в рамках свержения таких идолов трех базовых технологий DLP и какими они должны быть, чтобы как раз быть больше не про контентный, а про контекстный анализ.
Итак, первая технология анализа, которую мы рассмотрим, которую мы покритикуем, которая стала классикой рынка DLP, это регулярные выражения. Ну, всем знакомо, когда какая-то конструкция может определять любой реквизит: номер карты, телефона, номер счетов, ИНН. Так вот, с точки зрения контекстного анализа, регулярное выражение — самая слабая вещь. Как я уже приводил пример, нам нужно различать подпись в письме и данные какого-то клиента или даже сотрудника, который не является сотрудником клиентского отдела, не взаимодействует с другими контрагентами, не является публичным лицом. И вот с точки зрения регулярных выражений да, система может определить, что это какая-то фамилия-имя-отчество, какой-то e-mail, какой-то телефон или даже табельный номер, но регулярные выражения совершенно не понимают является ли это ФИО - сотрудника, является ли это ФИО - клиента или это просто упоминание какого-то контрагента. У нас есть технология защиты клиентских баз, защиты номенклатурных баз, защиты баз сотрудников, которая понимает бизнес-контекст. Достигается это за счет того, что она интегрируется с CRM, АБС или ERP-системой, оттуда она извлекает данные и проверяет каждое сообщение, каждое письмо, может проверить являются ли это данными сотрудников, является ли это данными клиента или даже, например, осуществлять такую проверку, что вот именно вот это наименование - это упоминание из номенклатурной базы. Эта технология позволяет четко понимать бизнес-контекст. Что это не просто какая-то структура, какой-то номер, какая-то фамилия, а это именно или клиент, или сотрудник, или партнер, или еще какой-то контрагент. Технология из бизнес-системы, где хранится контекст, извлекает данные, и потом эти данные сравнивает с любым перехваченным сообщением. И точно можно сказать, что вот этот номер телефона клиента, вот и принципиальная разница контентного анализа и контекста.

Цифровые отпечатки
Когда с конкретного документа снимается цифровой отпечаток тогда и позволяем его упоминать или его фрагмент выявлять. Как от контентного анализа перейти к контекстному? На рынке сложилось такое правило, что цифровые отпечатки - это либо текстовые цифровые отпечатки, либо бинарные. Так вот, чтобы цифровые отпечатки стали более чувствительными, более полезными с точки зрения детектирования служебной и конфиденциальной информацией, они должны определять максимальное количество разнообразных данных.
Хорошие цифровые отпечатки, чтобы быть эффективными, кроме текста, потоковой информации в виде аудио- и видеофайлов, должны понимать еще растровые изображения.
У нас был клиент у которого воровали репортажные фотографии с места происшествия.
И у них была цель отлавливать упоминания в трафике этих фотографий. Причем было не важно, фотография была изменена в разрешении, то есть это был формат RAF, а превратили его в JPEG, или RAF превратили в PNG, изменили разрешение и количество точек. Все равно эта система должна была это детектировать. У нас есть технология цифровых отпечатков, встроенная в DLP, которая позволяет отлавливать упоминания именно фотографий. Даже если фотографии немного обрезали, перевернули, изменили формат.
Есть еще отдельный модуль, который позволяет делать цифровые отпечатки с векторных изображений, с CAD-файлов. Когда, например, мы загоняем в систему очень грубый чертеж танка, и если кто-то пересылает хотя бы часть этого чертежа, то система все равно понимает, что это часть конфиденциального чертежа. Там анализ происходит за счет разбора графических примитивов: точек, линий, кривых и их взаимоотношений. То есть это не просто нарезка по бинарным данным, а это именно понимание, что изображено на векторном отпечатке. И как же заставить технологии цифровых отпечатков перейти от контентного анализа к контекстному? Естественно, цифровые отпечатки должны интегрироваться с системами электронного документа, со всеми теми хранилищами, где хранятся оригиналы документов, которые мы хотим защищать.
И вся эта база цифровых отпечатков должна поддерживаться в актуальном состоянии, то есть должна быть постоянная синхронизация, обновление отпечатков. У нас в Traffic Monitor для этого есть специальная API, которая позволяет все цифровые отпечатки поддерживать в актуальном состоянии и интегрироваться в системе электронного документооборота.
Лингвистические словари
Теперь переходим к другой технологии классической для рынка DLP, это лингвистические словари.
Как заставить эту технологию словарей перейти от контентного анализа к контекстному, чтобы она учитывала все нюансы. Здесь нам на помощь приходит машинное обучение. Потому что создание словарей — это очень затратная вещь. Чтобы создать эффективный словарь, чтобы он действительно четко детектировал ту или иную категорию информации, нужно от 5 до 7 рабочих дней профессионального лингвиста. Должна быть составлена полноценная лингвистическая модель, где может содержаться пара сотен терминов. Вот такой словарь создать тяжело. Машинное обучение снижает трудозатраты. Есть примеры документов, скормил информацию и через минуту готов новый словарь. Такой же эффективный, как если бы работал профессиональный лингвист. Дело в том, что удешевляя и ускоряя создание словарей, когда мы можем их генерировать десятками, экспериментировать, создали сегодня один – не заработал, на следующий день создали другой или его переобучили, это позволяет гранулировано каждую категорию данных, которые у вас есть в компании, отразить в политику. Например, если взять «из коробки» какой-то словарь, связанный с логистикой. А вы можете, например, его отключить. И создать на примере ваших конкретных документов словарь «логистика расходных материалов» или «логистика поставки товаров». Или создать словарь, который будет четко отражать коммерческие предложения. Удешевляя создание словарей с помощью искусственного интеллекта, с помощью машинного обучения, мы можем «нагенерить» этих словарей сколь угодно много, они будут отражать все нюансы вашего документооборота или бизнес-процесса. Удешевляя создание словарей для офицера безопасности, возможно их постоянно переделывать. Мы можем гранулировано каждую категорию данных отразить в политике, повторюсь, для каждого вида договора создать отдельный словарь.
И даже если у нас будут появляться новые какие-то категории данных, которые не были учтены, мы можем быстро на них реагировать. Вот поэтому машинное обучение и искусственный интеллект дает возможность более четко отражать бизнес-контекст в политике.
Теперь переходим к самому неприятному аспекту эксплуатации DLP-системы – это ложно-отрицательные срабатывания.

На самом деле это такой бич, про это на рынке DLP не принято говорить. Это неприличная тема, можно сказать, запретная. И в чем здесь проблема? DLP пропускает какие-то инциденты, даже не потому, что там ленивый офицер безопасности что-то там не учел, что-то вовремя не отметил в политиках. Проблема ложно-отрицательного срабатывания в том, что офицер безопасности может и не знать, что у него в трафике появился какой-то информационный актив, который он никак в политиках не учел.

Соответственно, не он об этом не знает, не DLP-система, которую он никак не обучил. Пропущенные инциденты, ложно-отрицательные срабатывания - это даже не проблема самой DLP -системы, а проблема того, что офицер безопасности так сильно загружен, что у него не хватает времени, вручную все просматривать, регулярно разбирать события, которые DLP-система не разметила. Это просто проблема человеческих ресурсов и гигантских трудозатрат. Единственный инструмент, который позволяет бороться с ложно-отрицательным срабатыванием, это когда мы открываем DLP -систему и руками, глазами методично просматриваем события, которые DLP-система не отработала, и ищем какую-то иголку в стоге сена.
У нас есть заказчик, он рассказывал, что у него есть такая регулярная стандартная практика. Когда какой-то сотрудник подает заявление на увольнение, они начинают методично все его события просматривать. То есть, в особенности пересылку на почту, на флешку и так далее. И вот этот заказчик что говорит? Нет, нет, да, в какой-то момент они обнаруживают какую-то категорию данных, какую-то структуру документов, какую-то новую форму, которую они в политиках не учли, а сотрудник в недельный срок несколько документов слил. И они начинают политики дорабатывать. Получается, чтобы бороться с ложно-отрицательными срабатываниями в текущих реалиях у DLP есть только одно – удача. Что при просмотре «руками» событий и инцидентов нам повезёт и мы найдем тот самый неучтенный информационный актив, который сможем обратить в политику. Если не повезет, то мы будем находиться в сладком неведении и не узнаем, что у нас что-то утекает. Что для этого мы можем предложить в данном контексте? Я уже даже не помню, год или полтора, у нас появилась технология машинного обучения, которая кластеризует неизвестные, никак не размеченные данные DLP-системы.

Что значит кластеризует? Она берёт всю серую зону, которую DLP-система никак не разметала, разбивает документы по кучкам и для каждого документа формирует аннотацию, подсвечивая наиболее яркие примеры документов. То есть, вот вы взяли, например, на этапе внедрения DLP-системы, у вас система отработала, нет ни одной «сработки», нет ни одной политики.
Запустили инструмент, он называется Data Explorer, и он вам раскидает все неизвестные документы по кучкам, создаст для них аннотацию и подсветит наиболее яркие примеры. И вы можете быстро посмотреть и понять, какие категории документов у вас входят в трафик.
Как работает эта технология? Представьте, что вы офицер безопасности. Перед вами стоит задача разобрать серую зону, разобрать эту массу документов, которые DLP-система никак не отработала. Представляете, что вы сидите за столом и к вам высыпают из корзины тысячи, десятки тысяч документов. И вам говорят, разберитесь какие здесь категории информации. Вот этим самым и занимается офицер безопасности, когда пытается «руками» разбирать серую зону. Документы никак не размечены в DLP, он начинает хаотично как-то ковыряться в этом. Руками и глазами.
Технология машинного обучения ведет себя по-другому. Представьте, что перед вами не куча документов, а перед вами положили скрепленные стопки документов, сказали, вот здесь договора, здесь товарно-транспортные накладные, здесь документы, связанные с сотрудниками. И на каждую стопку документов прикрепили еще желтый стикер, где указали, какие ключевые термины есть в этой стопке, так и еще наверх этой стопки положили наиболее яркие и разнообразные документы, которые эту стопку отражают.
Технология машинного обучения позволяет любые неизвестные ни человеку, ни DLP-системе данные разложить по стопкам и сформировать для них аннотацию. Так вы еще можете вот эту стопку взять и скормить другой технологии машинного обучения, которая вам сформирует за одну минуту новый словарь.
В данном случае, мы не то что от контента к контексту переходим, а мы этот контекст можем понять.

Заказчик столкнулся с проблемой, что у него определенная группа сотрудников выводила массовые документы за периметр компании. Это было суммарно 4 тысячи документов. DLP никак на эти документы не отработала. То есть не посчитала их конфиденциальными. Стали внимательно изучать эти документы. Получается, что какая-то категория информации, то ли она конфиденциальная, то ли не конфиденциальная, непонятно. Как сам заказчик оценил трудозатраты - 30 часов понадобилось бы чтобы два офицера безопасности разобрали эти документы. Но он использовал технологию машинного обучения, которая за полтора часа проанализировала 4 тысячи документов. В итоге было выяснено, что это определенный документ для подготовки слияний, для каких-то ВИПовских сделок и так далее, но которые в политиках никак отражены не были. И они в последствии эти информационные активы отразили в политике. Во-первых, они поняли, что это не нарушение, что это подготовках к сделке. А во-вторых, смогли этот информационный актив задешево исследований всего полтора часа вместо 30 часов. И потом с помощью машинного обучения создать словари и отразить их в политике. Заказчик говорит про трудозатраты, сколько он потратил, сколько он может потратить, сколько он не может потратить на обслуживание сделки, как ему обосновать перед руководством такие манипуляции по разбору серых событий.
И второй кейс – это финансовая организация, которая использовала технологию, которая противопоставлена регулярным выражениям. Это технология, которая в отличие от регулярных выражений, позволяет не просто контент, а контекст данных понимать. Компания, у нее 3000 сотрудников, 20 лет она на рынке, очень 100 тысяч клиентов. И у заказчика была задача – понимать, что данные клиента, выписки, коммерческие предложения, может быть, такие переписки, отправляются к конкретному клиенту. То есть, если я, например, отправляю коммерческое предложение партнеру или клиенту, но по ошибке указал неверный адрес, то это должно считаться нарушением. По сути, клиент с помощью этой технологии реализовал автоматическую политику, которая содержит в себе сотни тысяч правил. Здесь именно понимание контекста данных максимально раскрыто. Во-первых, мы определяем принадлежность данных конкретного клиента и автоматически определяем, что данные отправляются именно этому клиенту. Плюс эта технология внедрена в работе «в разрыв». То есть, если письмо отправляется не тому клиенту, или по ошибке, или там указано какие-то не те персональные данные, отправка будет заблокирована.
Это достигнуто за счет запатентованной технологии, алгоритмов индексации и поиска. Технология очень производительная. Приведу небольшой пример. Отпечаток клиентской база в 10 миллионов, ее вхождение в любое сообщение, любое упоминание любого клиента проверяется за одну десятую долю секунды.
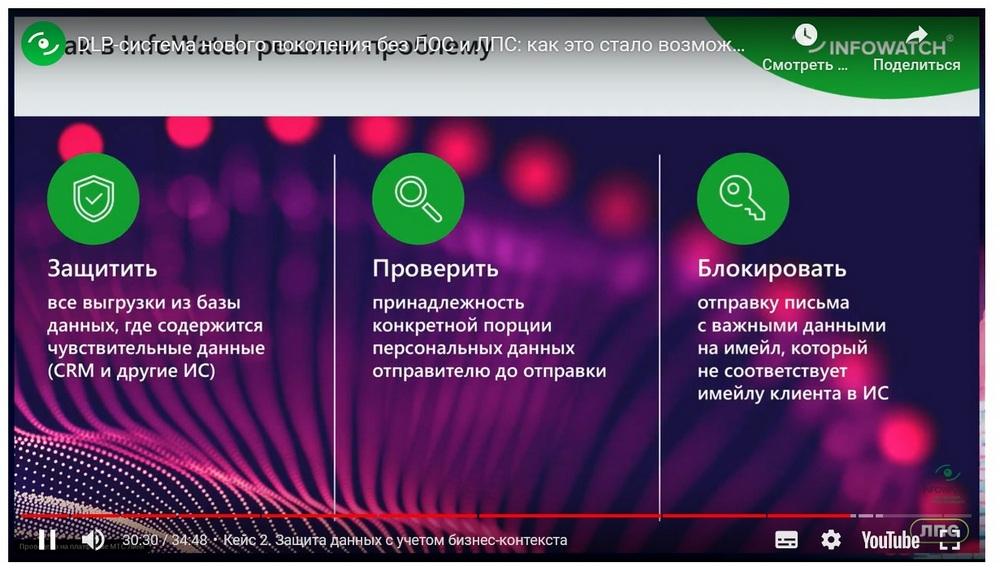
Мы смогли интегрировать DLP-систему Traffic Monitor с бизнес-системой заказчика, откуда забирали данные о клиентах, определяли принадлежность этих данных, ну и блокировали, если порция данных отправляется не тому контрагенту.
Вот за эту технологию мы получили национальную банковскую премию в номинации «Лучшая система защиты персональной данной для банковского сектора».

