En una de las reuniones anteriores, analizamos las novedades en el Código de Infracciones Administrativas, que aumentaron la responsabilidad por el incumplimiento de los requisitos para garantizar la seguridad de los datos personales e introdujeron multas basadas en la facturación por la fuga de datos personales. Ahora, nos reunimos para analizar las tecnologías para la protección de datos personales que permitirán evitar su fuga y evitar multas.

Al observar las diversas posibilidades para la protección de datos personales presentadas en el mercado, surgen preguntas y dudas razonables. A saber: los sistemas no detectan con suficiente calidad los datos personales en el tráfico, o literalmente abruman al especialista en seguridad de la información con cientos de falsos positivos en recibos de sueldo y firmas en correos electrónicos, bloqueando por completo los procesos de negocio legítimos. Si le resulta familiar esta situación o simplemente está eligiendo medios para proteger los datos personales, participe en la reunión de hoy y familiarícese con las capacidades de InfoWatch Traffic Monitor, un sistema DLP ruso con tecnologías especializadas patentadas para la protección de datos personales y capacidades de verificación de la admisibilidad del destinatario. Esto permitirá proteger los datos personales de manera eficiente sin perjudicar los procesos de negocio ni consumir tiempo de los servicios de seguridad de la información en falsos positivos. Discutiremos por qué los datos personales son el activo de información más complejo de proteger. Hablaremos sobre la tecnología InfoWatch para la protección de datos personales, que permite encontrar instantáneamente el robo incluso de un solo registro de datos personales. Analizaremos cómo evitar el bloqueo de los procesos de negocio diarios.
Hoy contamos con el orador Alexander Klevtsov, jefe de desarrollo de productos de InfoWatch y Traffic Monitor.

Hoy vamos a hablar sobre cómo proteger los datos personales. Tenemos un título un poco provocador: "Cómo proteger los datos personales y no 'tumbar' los procesos de negocio". ¿Cómo hacer que la protección de datos personales sea efectiva?

En la parte introductoria recordaré la importancia de la protección de datos personales, hablaré sobre el papel del producto DLP en la protección de datos personales. Hablaremos sobre los problemas relacionados con la protección de datos personales y los problemas con DLP, por qué no todos los DLP son igualmente útiles. Primero crearemos el problema, y luego hablaremos sobre su solución y analizaremos acciones concretas.
Se ha dicho mucho sobre la importancia de la protección de datos personales y, lo más importante, la protección contra la fuga de datos personales. Los problemas con los datos personales pueden generar pérdidas financieras. Según los resultados de la investigación de nuestro centro científico InfoWatch junto con una agencia, llegamos a la conclusión de que el daño promedio por fuga oscila entre 11,5 y 42 millones de rublos.

Aquí se entiende tanto el daño directo como el indirecto, las multas y los costos de investigación de fugas relacionadas con datos personales, y los costos de eliminar las consecuencias, en general, es una cifra compleja. Según las estadísticas, en 2024, el crecimiento en el número de datos personales comprometidos, robados, varios tipos de fugas relacionadas con datos personales, creció un 30%. Y por separado, quiero subrayar que el 20% de estas fugas son acciones intencionales de empleados, internos malintencionados. Es decir, la amenaza provenía del empleado, y él la llevó a cabo. El propio empleado robó datos personales. Por supuesto, la legislación sobre multas relacionadas con la pérdida de datos personales se ha endurecido.
Analicemos brevemente qué medidas debe tomar una empresa para organizar la protección de datos personales.

Esto es algo complejo. Está relacionado tanto con la certificación del sistema como con las certificaciones, la capacitación de los empleados y medidas técnicas como garantizar canales de comunicación protegidos, cifrado, diferenciación de derechos de acceso tanto a nivel de los sistemas donde se almacenan estos datos personales como a nivel del sistema operativo, y la auditoría de los lugares de almacenamiento de estos datos y mucho, mucho más. ¿Qué énfasis quiero hacer aquí? En cualquier empresa siempre hay y habrá empleados que legítimamente tienen acceso a datos personales en el marco de sus responsabilidades laborales.

Y por mucho que te protejas de un atacante externo, por mucho que organices canales de cifrado, diferenciación de derechos de acceso, alguien de tus propios empleados aún puede robar estos datos. Existe una práctica estándar en el ejemplo de un banco, cuando organizan el procesamiento de datos personales en circuitos cerrados. Cuando colocan sistemas críticos para el negocio, por ejemplo, ABS, en algún circuito cerrado, desde el cual no hay acceso a Internet, y aparentemente así reducen el riesgo de fugas de infracciones relacionadas con datos personales. Pero siempre hay empleados que tienen acceso simultáneamente a los lugares de trabajo y al circuito cerrado, y al circuito abierto con Internet, y el riesgo potencial de fuga siempre existe. Es decir, hay que entender que sin DLP no se puede hacer nada. Y no importa lo que hagamos, pero sin controlar los canales donde estos datos personales pueden ser transferidos a algún lugar, no podremos evitarlo.
Yo analicé lo que dice el mercado, lo que dice Internet sobre los problemas con la protección de datos personales con la ayuda de DLP. Dicen que es suficiente con implementar DLP, de alguna manera realizar una auditoría, configurar DLP, y aparentemente los datos personales se pueden proteger. En realidad, no es del todo así. Ahora expresaré una idea ruda, sobre el hecho de que DLP en su comprensión clásica protege muy mal los datos personales. Ahora explicaré por qué. Porque BDN es en realidad un activo funcional pesado que es difícil de proteger.

Aquí en la diapositiva, preste atención, se muestra un ejemplo, hay dos mensajes. En uno de ellos hay una fuga de datos bajo la apariencia de algún mensaje inofensivo. Y el otro es simplemente una charla de los empleados. Dos mensajes completamente similares entre sí, pero uno de ellos es una fuga, y el otro no. Y este es un caso de la vida real, cuando en un banco bajo la apariencia de algunos mensajes inofensivos, simplemente supuestamente se informaba sobre tutores de idiomas extranjeros. Y en realidad, el empleado transmitía al exterior en estos breves mensajes datos sobre clientes vip. ¿Cómo se utilizaron estos datos después? Llamaban al cliente, se presentaban, ofrecían condiciones más favorables para los productos bancarios. Y al final, el cliente con algún activo financiero muy serio transfería el servicio de estos activos a otro banco. Una fuga como esta es muy difícil de detectar en el diseño clásico de DLP. Porque, ¿cómo vamos a detectar el apellido, el nombre y el número de teléfono? Crearemos una expresión regular para el apellido y el teléfono, entonces tendremos LPS, como en esta diapositiva, por ejemplo, en cualquier firma en un correo electrónico. Tampoco se pueden crear diccionarios. Teniendo en cuenta que estos datos personales pueden ser cientos de miles, si hablamos de un banco, y un millón de datos. Resulta que no podemos clasificar un mensaje así. Si, por ejemplo, intentamos con la ayuda de DLP detectar cualquier mensaje donde se mencionen combinaciones como número de teléfono, apellido y nombre, esto conducirá a enormes falsos positivos. Nos cansaremos de resolver tales eventos después. Además, hay un problema adicional. Imaginemos una situación en la que, sin embargo, configuramos de tal manera que el sistema reacciona a cualquier mención de datos personales, al número de teléfono, a la mención del apellido, nombre, entonces el oficial de seguridad, al ver los eventos interceptados, el incidente potencial con tal texto, nunca en su vida entenderá si es una fuga o no, a menos que recuerde de memoria todos los datos de contacto de los clientes del banco.

En el mensaje, por ejemplo, estará escrito: "¡Hola! Te transmito los datos del tutor de francés". ¿Cómo puede un oficial de seguridad determinar que esto es una fuga? Otra cosa es cuando se filtra una fuga realmente evidente en fotografías, alguna tabla de Excel o algún informe, donde se ve que se enumeran nombres completos, direcciones, teléfonos. Esto está claro. Y cualquier DLP reaccionará fácilmente a esto. Y un oficial de seguridad, al ver tal conjunto de datos, entenderá que se trata de algún conjunto de bases de datos. Y cuando un mensaje pequeño como este ni DLP ni el oficial de seguridad pueden determinar esto como una fuga.
En realidad, las cosas son aún peores. Ya dije que DLP determina bien las fugas masivas a través del filtro, no permite filtrar una tabla.
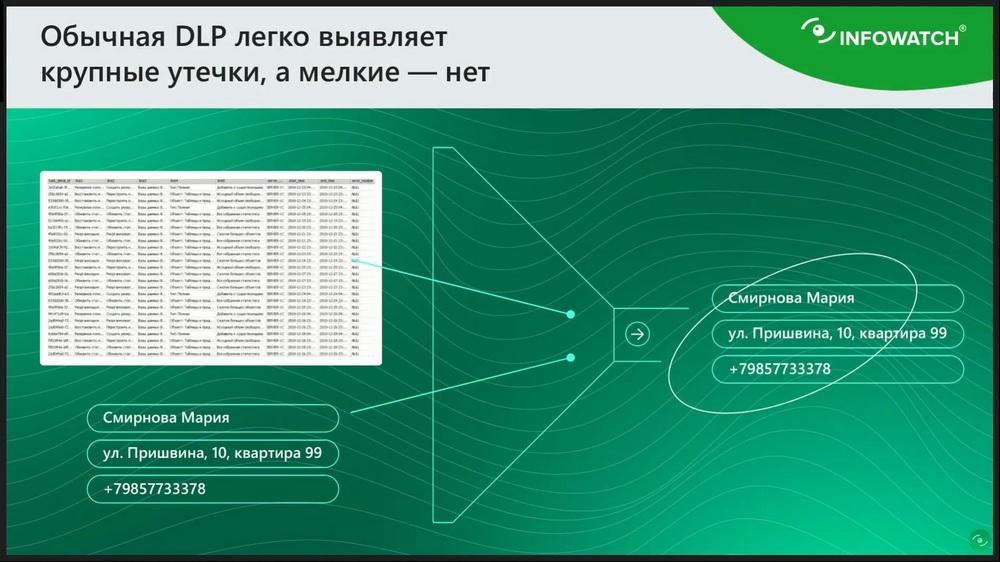
Y aquí hay un pequeño mensaje que es indistinguible de cualquier firma, no se puede determinar. Una fuga tan pequeña es muy difícil de detectar. Pero, sin embargo, incluso una fuga tan pequeña puede generar una pérdida financiera directa, de la que quizás ni siquiera nos enteremos. No son esas grandes fugas en las que se filtró alguna base de datos, en algún lugar apareció en los medios, o tal vez esta fuga se hizo a propósito para comprometer, desacreditar a la empresa. Sino que es una pequeña fuga secreta que de alguna manera se utilizó, y al final no sabemos nada al respecto. Ni el sistema sabe nada al respecto, ni la persona.
Pero el problema es aún peor. El problema es que en casi cualquier empresa existen procesos en los que la transferencia de datos personales, incluso fuera del perímetro de la empresa, es un proceso absolutamente legítimo. Siempre existen procesos en los que se transfieren algunos datos personales fuera del perímetro de la empresa. Esto puede ser, por ejemplo, cosas como los envíos de correo electrónico, donde las organizaciones financieras ofrecen a los clientes algunos productos personales, algunas ofertas personales. Y ahí es donde envían alguna información, ahí es donde también se transmite todo esto. Pero también dentro de la empresa, los datos personales a menudo se transfieren. Estos pueden ser recibos de sueldo y pólizas de seguro médico privado, se transfieren muchos datos personales tanto dentro como fuera de la empresa. Digo esto porque no será posible apretar tanto las tuercas para que en absoluto esté permitido transferir datos personales a nadie ni a ningún lugar. Hay muchos procesos legítimos en los que se transfieren datos personales.
Y aquí hay una tarea aún más compleja. Qué hacer si necesitamos determinar que una porción de datos personales se transmite precisamente a su propietario.

Que, por ejemplo, la oferta personal del cliente del banco se transmita precisamente al cliente del banco. Que los datos personales confidenciales del empleado se transmitan específicamente al empleado. ¿Cómo resolver esta tarea, que no solo el oficial de seguridad vea la información y deba comprender que los datos se transmiten, por ejemplo, al cliente del banco? Por ejemplo, ve un mensaje: "Estimado Iván Ivánovich, queremos ofrecerle tales y tales cambios en tales y tales productos". Y ve algún correo electrónico personal, por ejemplo, Alex.34@gmail.com. ¿Cómo puede el oficial de seguridad determinar que este es precisamente el correo electrónico del cliente al que se dirige? Es imposible. ¿Cómo se podría hacer esto idealmente en un sistema DLP?

En un sistema DLP, en su ejecución clásica, tendríamos que crear, por ejemplo, 1000 reglas para 1000 porciones de datos personales. Una porción específica de datos personales - un destinatario específico. Una porción específica - un destinatario específico. Pero, si tienes un millón de clientes, la tarea vuelve a ser irresoluble.
Resumamos, ¿cuáles son nuestros problemas con la protección de datos personales?

Los datos personales son difíciles de clasificar. Porque todos los datos personales son a menudo datos con nombre. Es un número de teléfono específico, un nombre completo específico, una dirección específica, etc. Es decir, cuando hablamos de protección de datos personales, no es importante para nosotros detectar algún número de teléfono, alguna dirección. Necesitamos detectar una dirección específica, un número de teléfono específico, una mención específica de una persona. Este es el principal problema de la protección de datos personales. Aquí hay un bloque: información confidencial similar a la pública. Esta es una continuación del mismo problema, que es difícil distinguir los datos personales confidenciales de los públicos.
El segundo problema son los enormes volúmenes de datos. Estos son datos pequeños que pueden contarse por millones de registros. Y el tercer problema fundamental es que el DLP, en su diseño clásico, tiene reglas demasiado generales. No se puede configurar de forma granular una regla específica para una porción específica de datos para un destinatario específico, para determinar que los datos personales los recibe precisamente su propietario. Es decir, teóricamente es posible, pero tendrías que crear cientos de miles de reglas y mantener todo esto actualizado. Por lo tanto, es muy difícil implementarlo en el paradigma al que todos estamos acostumbrados.
Por lo tanto, la empresa InfoWatch, basándose en estos problemas, creó una tecnología que propone pasar del análisis de contenido, que de alguna manera clasifica los datos personales: números de teléfono, números de cuenta, nombres completos, direcciones, del contenido con la determinación de qué tipo de datos son, al contexto, es decir, la comprensión de que se trata de una porción específica de datos personales, que tienen un propietario específico, estos datos tienen un inicio específico.

Transición a la definición granular de los valores de los datos personales para cada propietario, es decir, del contenido al contexto. Esto se logra mediante la indexación de datos de los sistemas de información corporativos. Es decir, en este caso, el sistema DLP – monitor de tráfico se integra con el ERP o CRM corporativo, o incluso con el sistema de gestión de documentos electrónicos, extrae de allí los datos personales, los indexa. Y, si hablamos en un lenguaje sencillo, crea como una política automática, que incluye y puede incluir cientos de miles de reglas, millones de reglas. No es necesario mantener esta política actualizada manualmente. Los datos se indexan de los sistemas de información corporativos y se protegen.
Propongo considerar un ejemplo concreto. Se implementó con la ayuda de esta tecnología.

Hay un banco en el que trabajan 20 mil empleados. En este ejemplo, se hablará de la protección de los datos personales de estos empleados. Es necesario proteger cualquier dato de los empleados. Estos pueden ser pólizas de seguro médico voluntario, contratos, recibos de sueldo. Es necesario proteger de la siguiente manera: para que los datos del empleado se envíen estrictamente solo al empleado y a nadie más. Es decir, por ejemplo, si la póliza de seguro médico privado de Ivánov se envía por error a Petrov, entonces ya es una infracción. Pero al mismo tiempo, hay un matiz, es necesario hacer que el empleado disponga de sus datos personales como quiera, y no debemos limitarlo. Y un punto importante en esta tarea que resolvimos es que, si los datos se envían al empleado equivocado, entonces tales cartas, tal comunicación corporativa debe bloquearse. Es decir, lo que sucede es que, si el departamento de recursos humanos envía una póliza de seguro médico privado al empleado, al propietario de esta póliza, entonces esto es normal. Si, por ejemplo, luego el empleado toma y reenvía esta póliza de seguro médico privado a su correo personal, es decir, dispone de sus datos personales como quiere, la reenvía a su correo personal o envía esta póliza a su esposa, esto tampoco se considera una infracción, porque él mismo dispone de ella.
¿Cómo se implementó esto con la ayuda de esta tecnología? Hubo una integración con el sistema DLP. De allí se extraían todos los datos de cada empleado, los datos por los que se podía identificar a este empleado. Y además se extraía el correo electrónico que se indicaba en la tarjeta del empleado. ¿Cómo se implementó la protección? Se determinaba una porción específica de datos personales con la ayuda de una política automática. Y se comparaban el destinatario real de estos datos personales y el correo electrónico que se había indexado de la tarjeta de los empleados. Y, si el correo electrónico real no coincidía con el correo electrónico indexado del sistema DLP, entonces esto se consideraba una infracción. No es necesario mantener esta política manualmente. Se actualiza constantemente de forma automática diez veces al día. Se producía la sincronización. Se realizaba una protección granular de los datos personales de los empleados. En este caso, resolvimos una tarea elemental como el envío de recibos de sueldo. Porque antes de esto, el sistema DLP se ponía rojo dos veces al mes, provocado por el envío de recibos de sueldo, porque el sistema consideraba que era información financiera, una fuga, y no podía determinar quién recibe este recibo de sueldo, el propietario o no el propietario.
Pregunta. ¿Y si se envía no al correo, sino a través de un mensajero?
Respuesta. Es necesario determinar, en nuestra práctica, si se envía a un mensajero, es poco probable que exista un proceso tan largo. Es poco probable que RR. HH. envíe a un mensajero. En este escenario, el envío de todos los datos personales, como los regulados, solo se realiza a través del correo corporativo. Si, por supuesto, permitimos el momento en que los datos personales se envían, no se sabe cómo, a través de todos los canales, entonces, por supuesto, el DLP en este caso será como una pared de un metro por un metro en un campo limpio. Por lo tanto, se trata de la correcta organización de los canales, es necesario escribir esto en los actos legales locales de la empresa, que todos los datos personales, toda la información confidencial del empleado se envían solo a través de este canal corporativo.
Pregunta. ¿Se debe tener en cuenta la dirección de la transmisión de mensajes, cuando se puede filtrar el reenvío dentro de la organización?
Respuesta. Pero, de nuevo, si RR. HH. envió por error al mismo empleado, entonces no detectaremos tal fuga. Por lo tanto, la dirección, desafortunadamente, no ayudará a resolver tal tarea de protección granular de datos personales.
Pregunta. ¿Y si precisamente el acceso al mensajero de esta organización, cómo tiene en cuenta el sistema tales eventos?
Respuesta. Si ha decidido que este es un canal regulado, entonces no hay problemas. Y no importa qué canal sea. La tecnología funciona en cualquier canal de comunicación. No hay ninguna diferencia. Si se habla de correo, entonces se entiende que la tecnología funciona en cualquier canal.
Pregunta. ¿Y si las hojas de cálculo se empaquetan en archivos con contraseña? El nombre del archivo está despersonalizado, simplemente "libro de hash" de números.
Respuesta. Mire, si se permite que se reenvíe información de contraseñas dentro de la empresa, entonces, por supuesto, ningún DLP le ayudará. Si, por ejemplo, estas contraseñas son individuales para cada empleado, entonces es posible que no tenga ese problema. Es decir, el empleado sabe que esta contraseña es solo suya, entonces, por supuesto, esto será relevante.
Pregunta. Aquí, Andréi pregunta, ¿cómo implementar la protección si la propia compañía de seguros envía pólizas de seguro médico voluntario (DMS) a todos?
Respuesta. Entonces, debe pedirle a la compañía de seguros que implemente DLP. Si envía pólizas de seguro médico voluntario (DMS) individualmente, entonces, por supuesto, la compañía de seguros es potencialmente un punto de fallo en este caso. Esto se resuelve así. Tomamos, indexamos también los datos RIP de los clientes y controlamos el correo entrante. Si hay correo entrante, incluso se puede especificar desde un dominio específico de esta compañía de seguros, llega una póliza, e identificamos esta póliza como una póliza específica de un empleado específico, y el destinatario del empleado en el correo entrante no coincide, entonces podemos de alguna manera interceptar esta carta. Es decir, sí, se puede resolver el problema no implementando DLP en la compañía de seguros, sino dentro de su DLP interno.
Pregunta. En este caso, ¿es necesario crear una lista de correos electrónicos legítimos de antemano para que funcione normalmente?
Respuesta. Sí. Aquí se asume que cuando protegemos la protección granular de datos, una porción específica de datos personales, entonces, por supuesto, debemos obtener este correo electrónico legítimo de alguna parte. Aquí lo tomamos del sistema DLP. Porque no es que a menudo, sino siempre, en tales sistemas se indica el correo electrónico de contacto del empleado. Aquí estamos incluso un poco condenados al éxito, porque tales datos siempre se almacenan en los sistemas corporativos.
¿Existen herramientas que protejan contra la fotografía de la pantalla? Respuesta. Existe una herramienta que permite, supuestamente, ver que un empleado está apuntando una cámara en su teléfono a la pantalla del monitor, o está apuntando su teléfono inteligente a la pantalla. Pero, como ha demostrado la práctica, esto no es muy efectivo. Desafortunadamente, no es muy bueno para hacer esto. Pero cuando hablamos de fotografiar la pantalla, especialmente cuando no tenemos cámaras, entonces la pregunta es que no es necesario proteger contra las fugas de datos, sino que es necesario controlar qué datos presenta el empleado en su lugar de trabajo. Espero haber respondido a las preguntas. Ahora hablemos de los detalles. Repito, el caso está implementado. En el banco hay 20 mil empleados. Los datos de un empleado no se pueden enviar a nadie más que a él mismo. Y el empleado ya puede disponer de estos datos como quiera. Esta política automática verifica que, si el remitente de estos datos personales es el propio propietario de los datos personales, entonces no es necesario restringirlo de ninguna manera. Es decir, la política automática implementa dos reglas automáticas: que la recepción de datos personales corresponde al propietario de los datos personales y que el remitente de datos personales corresponde al propietario.
Ahora analicemos más detalles.

Todo este caso se resolvió teniendo en cuenta el bloqueo, es decir, sin procesamiento diferido. Interceptamos la carta, entendimos que el destinatario real y el propietario de los datos personales no coinciden, e inmediatamente la bloqueamos. Todo esto se hace muy rápido. Existe un indicador, del que hablamos a menudo, que la verificación de cualquier mensaje, incluso pequeño, en los mensajeros, la comparación de este mensaje con una base de datos de diez millones de datos personales no lleva más de una décima de segundo. Cada mensaje, cada carta, podemos verificar si hay mención de datos personales específicos de alguna base de datos. Repito, porque fijamos estos datos de los sistemas donde se almacenan estos datos.
Ilustraciones proporcionadas por el servicio de prensa de InfoWatch
Ilustraciones proporcionadas por el servicio de prensa de InfoWatch
proporcionado por el servicio de prensa de InfoWatch