Внедрить эффективные программы исследования данных непросто. Ведущие эксперты отрасли поделятся с нами стратегиями внедрения эффективных методологий исследования данных, которые помогут повысить продуктивность организации.
На этом мероприятии будет рассказано, как непрерывная интеграция и непрерывное развертывание с оптимизацией использования ГП могут принести выгоду для бизнеса:- Разрабатывайте модели на основе функций автоматизации.- Оптимизируйте инвестиции в ускорение вычислений (особенно в ГП). - Повышайте эффективность и производительность.
Сегодняшнее мероприятие ведет Андрей Карташев, представляющий подразделение Point Next компании HP Enterprise. С таким странным названием в компании HPE функционирует подразделение, которое занимается сервисными направлениями, начиная от техподдержки и заканчивая сложными внедренческими темами. Это мероприятие будет посвящено одной из таких тем, которая непосредственно связана с услугами. HPE решил вдохнуть новую идею в это направление и несколько диверсифицироваться от привычных вещей, с которыми мы всегда ассоциировали сервера и СХД.
Теперь берет слово Мэтт Мако, технический директор по взаимодействию с регионами в подразделении ПО Ezmeral компании HPE. Он расскажет о том, что подразумевается под понятием МО и графическими процессами в понимании HPE.
Когда речь идет о промышленном внедрении, можно использовать в качестве примера автомобильный завод. Это поможет нам точнее разобраться в особенностях внедрения анализа данных. Что же такое промышленное внедрение?
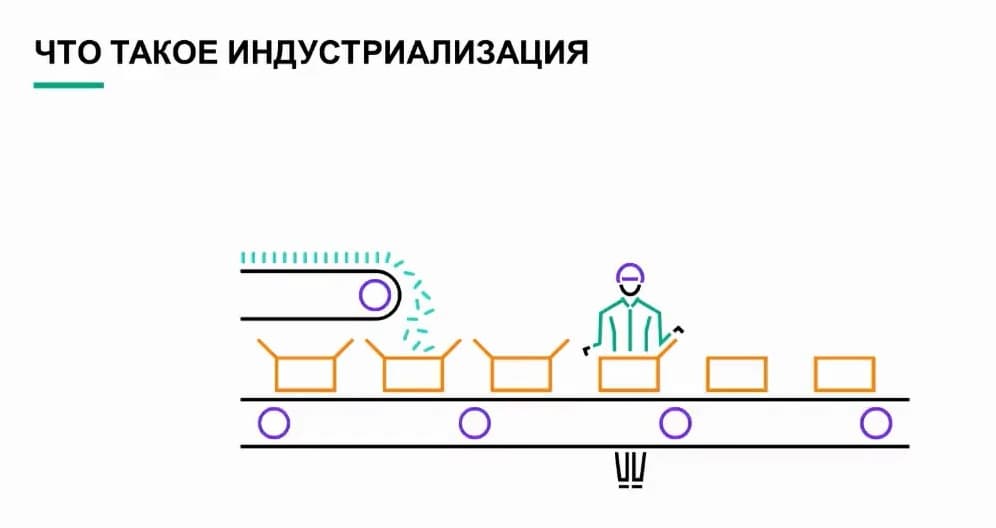
Например, на автомобильном заводе должна быть организована поставка деталей, должны быть квалифицированные рабочие, выполняющие сборку, должно быть соответствующее оборудование, роботы, автоматизирующие процесс. Чтобы добиться высоких объемов производства автомобилей, все эти компоненты должны быть согласованы. Давайте рассмотрим таким же образом процессы обработки и анализа данных организованы в компании. Как достичь максимальной автоматизации, высокой пропускной способности и эффективности при обработке и анализе данных?
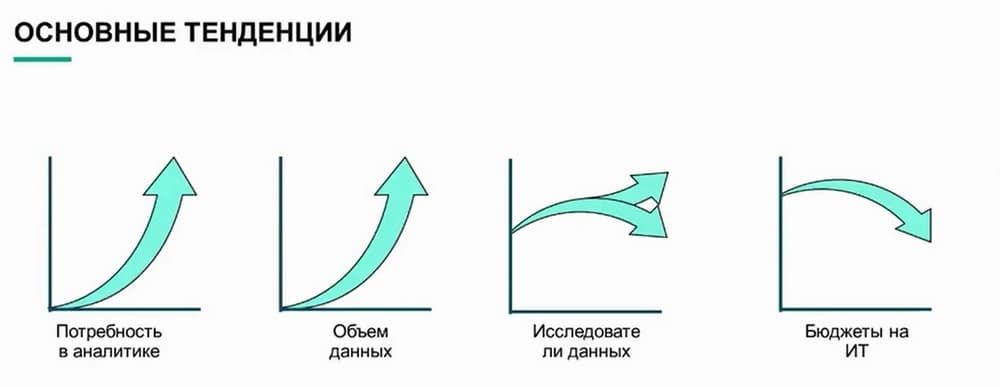
Какие тенденции наблюдаются в организациях. Во-первых, растущая потребность в аналитике. Компаниям необходимы более эффективные отчеты о прошедших событиях, анализы тенденций, исследование данных. Спрос на аналитику увеличивается в геометрической прогрессии в соответствии с растущим объемом данных. Появляются новые приложения, инфраструктура, точки взаимодействия с клиентами, и все они порождают данные, которые организациям нужно обработать и использовать. Эти задачи выполняют специалисты по анализу и обработке данных. Зачастую организациям непросто нанять или удержать их. Это также одно из условий рассматриваемой задачи промышленного внедрения. Также не будем забывать, что эта статья часто не учитывается в IT-бюджетах организаций.
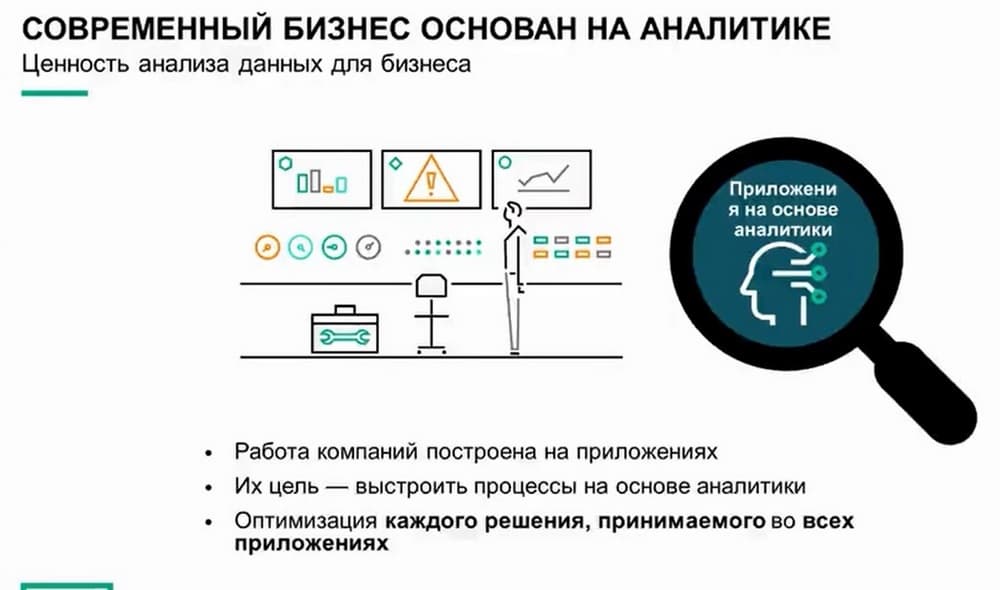
Что касается компаний, решающих эту задачу, то можно сказать, что большинство из них ориентированы на приложения. Проекты, осуществляемые в рамках цифровой трансформации последние несколько лет, в основном касались модернизации инфраструктуры приложений, а также модернизации ЦОД. Организации переходят от монолитных, трехуровневых приложений для мейнфреймов к облачным микрослужбам без отслеживания состояния, 12-факторным приложениям, причем довольно успешно. Следующий шаг - встроить в эти приложения процессы принятия решений на основе аналитики и данных, а затем интегрировать эти принципы в масштабе компании, чтобы каждое решение во всех приложениях, в каждом аспекте деятельности организации было основано на анализе и данных. На данный момент - это нетривиальная задача, но ее решение позволит достичь состояния, когда не нужно будет гадать, какая идея правильная, а можно будет принимать решения на основе данных в масштабе организации.
Какие препятствия существуют на этом пути? Почему это реализуется не во всех организациях? Первая причина заключается в распределенной структуре организаций. Дело не только в профильных специалистах по обработке данных, о них пойдет речь чуть позже. Дело в том, что многие организации имеют распределенную структуру, особенно IT-подразделения. Оставим пока бизнес-подразделения и сотрудников, не связанных с технологиями. Даже в технологических подразделениях, даже при наличии одного руководителя высшего звена, например, IT-директора, технического директора или директора по цифровым технологиям, функциональные направления разрозненны.
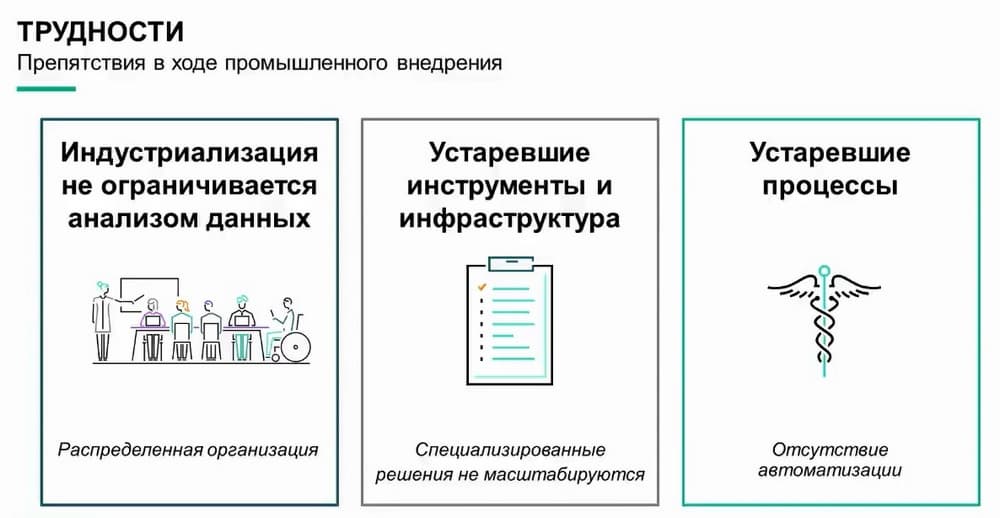
Чтобы специалист по данным мог собрать модель и где-то ее развернуть, необходимо "подружить" эти направления. Структурная разрозненность часто определяет поведение, и встает на пути прогресса. В этом заключается первая проблема, которую необходимо решить.
Вторая трудность связана с устаревшими инструментами и инфраструктурой, которые есть во многих организациях. Вы, наверное, подумали: погоди-ка, Мэтт, ты только что сказал, что эти компании проводили модернизацию, причем в крупных масштабах и достаточно долго. И это правда. В мире приложений у нас гибкая разработка, DevOps, непрерывная интеграция и непрерывная доставка. Но эти процессы почти не касаются аспекта управления данными. И снова о разрозненности. Многие из приложений, ориентированных на данные, будь то хранилища данных, системы мониторинга безопасности, озера данных и другие, часто развертываются вручную, от случая к случаю или аппаратным образом. В результате концепцию промышленного внедрения пытаются применить в недостаточно гибкой и адаптивной комбинации инфраструктуры и инструментов, с которыми она плохо сочетается. Это также является препятствием. Наконец, устаревшие организационные процессы. Даже если мой специалист по данным разработает самый блестящий алгоритм, а я смогу развернуть его на существующих системах, у этой задачи есть еще и бизнес-аспект. Например, сам факт выявления мошенничества вовсе не означает, что организация сможет отреагировать на эту проблему и пресечь ее. Мы остановим линию сборки? Многие из этих организационных процессов не автоматизированы, что ограничивает их масштаб и этот промышленный процесс линии сборки. Как решить эту проблему? Что считать успехом? Вернемся к аналогии с автозаводом.
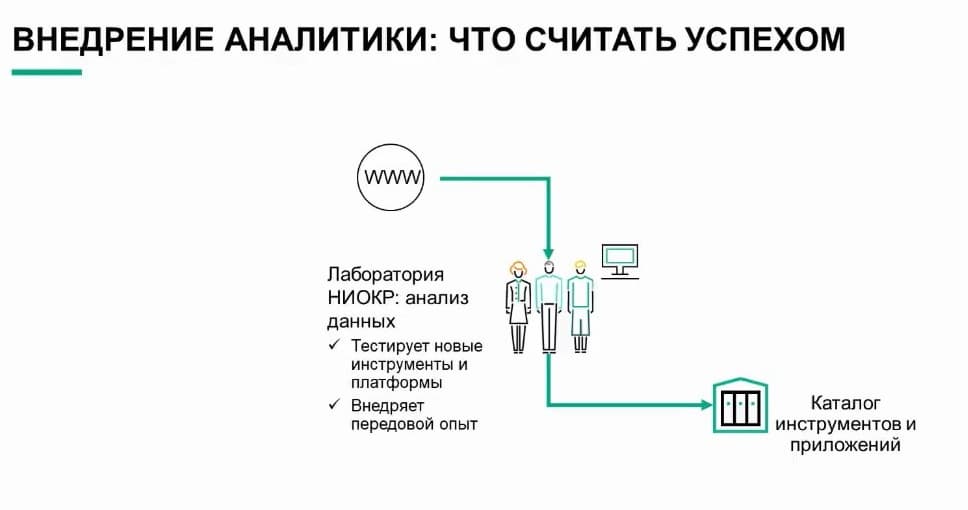
Задумайтесь о том, что концепция автомобиля, который производится сейчас, была создана несколько лет назад. За 3 года или 5 лет до этого момента группа специалистов из отдела исследований и разработки, дизайнеры, инженеры, механики собрались. чтобы спроектировать автомобиль следующего поколения. И они продумали все аспекты. Какой ширины должны быть шины? Каким будет изгиб капота? Нужен ли задний спойлер? Как будут открываться двери? Какой двигатель? Какая коробка передач? Все эти вещи продумываются заранее за несколько лет. Разрабатываются спецификации, прототипы. Затем, наконец, дело доходит до производственной линии и создаются роботы. Вы определяетесь с новыми оттенками краски.
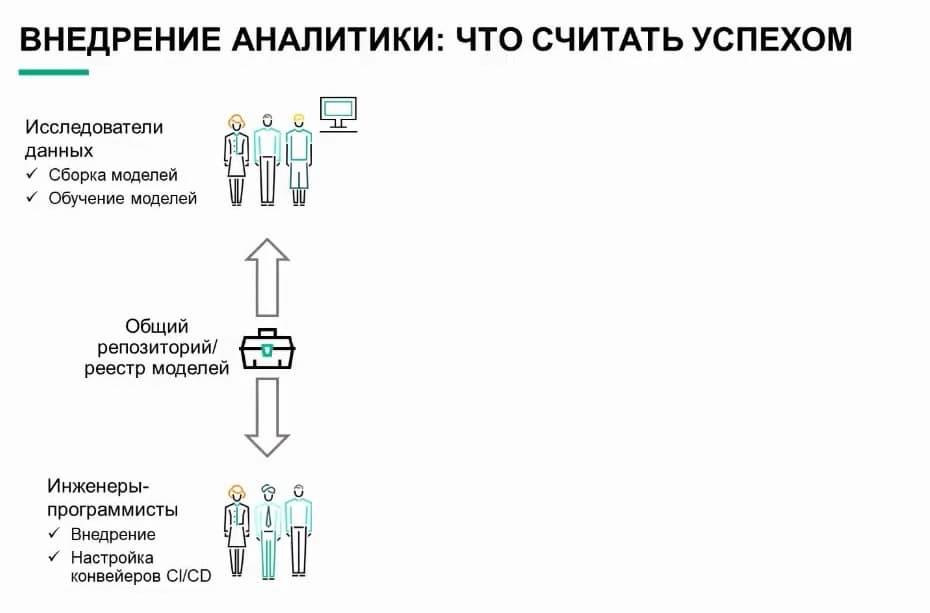
Вы подключаете поставщиков, чтобы, когда ваша команда будет готова, у вас были люди, способные собрать этот автомобиль. То же справедливо и для промышленного внедрения анализа данных. Нам нужно, чтобы логистическая цепочка, поток данных были готовы для выполнения аналитических моделей. Они должны быть предусмотрены и доступны для всех аналитических задач организации. Нужны подходящие инструменты - не только во время экспериментов. Специалистов, которые создают аналитические модели, должны иметь доступ к новейшим инструментам и инфраструктуре, будь то ЦП, ГП или области верхней памяти - все это также должно доступно. И самое важное: эту сборочную линию нужно настроить, чтобы она позволяла развертывать аналитические модели в производственной среде. Это значит, что производственная среда должна быть готова к использованию инструментов, библиотек, наборов данных и приложений, разработанных на более ранних этапах процесса. Во многих организациях направление R&D воспринимается как центр передового опыта, в котором специалисты по данным и инженеры объединяют усилия для поиска решений и взаимодействуют с IT-отделами для подготовки процесса к внедрению. Далее специалисты по данным отбирают новейшие инструменты и библиотеки, сертифицированные организацией. Они выбирают подходящие данные, необходимые для решения конкретной задачи как инструменты в строительном магазине, а затем проводят эксперименты. Они строят эти аналитические модели. Они обучают эти аналитические модели. Причем все это они делают итерациями снова и снова. Обычно не в изоляции от других. Часто несколько специалистов по данным работаю вместе, сотрудничают на проектах - на уровне организации, подразделения или даже отдела.

Они совместно разрабатывают процедуры передачи и получения кода как разработчики ПО. Они используют системы управления версиями, чтобы выполнять итерации с версиями модели, пробуя новые библиотеки и методы. И наконец, когда они приходят к пониманию, что модель разработана, им требуется ее обучить. Это значит, что им нужен доступ к очень крупным наборам данных, позволяющим обучить модель и проверить, как она работает, на основе прошлых событий. Потом они корректируют значения переменных, проходя этот процесс повторно. Он итеративный по своей сути. Параллельно в игру вступает еще один важный персонаж - подразделение разработки ПО. В некоторых компаниях это отделы МО или инжиниринга данных. Эти люди отвечают за получение результатов от специалистов по данным: запросов к базам данных, скриптов, кода на Python - и обеспечивают их развертывание на следующих этапах процесса. Часто система, на которой нужно развернуть код, написанный специалистами по данным, не принимает его. Например, потому что на ней не запускается Python. Тогда группа разработки ПО переписывает код и алгоритмы, созданные специалистам по данным, или помещает его в приложение, которое в конечном счете исполняется в целевой системе.
Это может быть встроенный код. Это может код Java. Каким бы он ни был, именно группа разработки ПО работает над внедрением алгоритма, созданного специалистами по данным. Параллельно они также строят конвейеры CI/CD. CI - это непрерывная интеграция, а CD - непрерывная доставка и непрерывное развертывание. Так мы переносим облачный процесс DevOps в мир анализа и обработки данных. Это важно, потому что процесс DevOps позволяет говорить об автоматизации. Он предполагает выполнение батареи тестов в рамках непрерывной интеграции, позволяющей удостовериться, что код исполняется на целевых системах, что он взаимодействует с инфраструктурой, что ему предоставляются ГП и т.п.
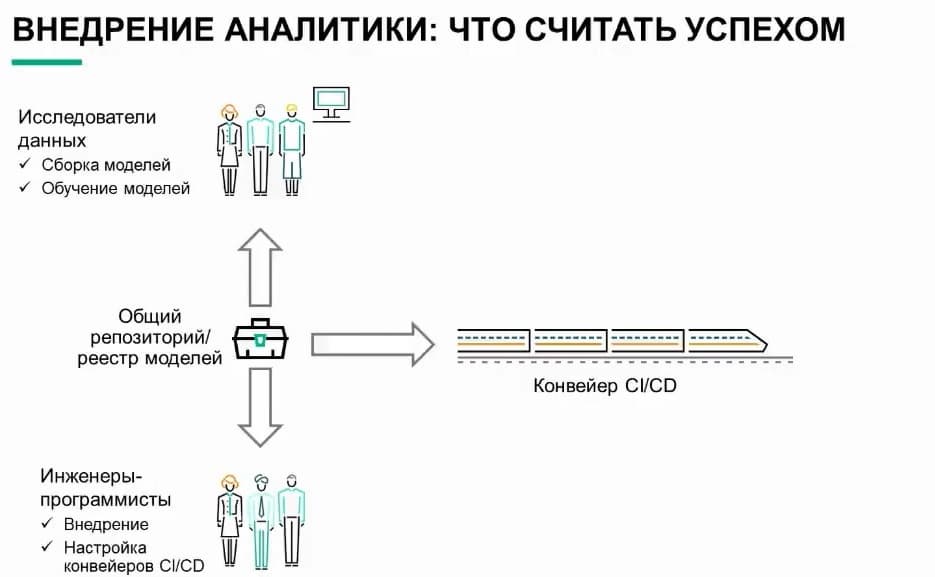
После этого он упаковывается в артефакт, который затем может быть развернут в среде выполнения. Соединение этих функций позволяет реализовать облачную модель работы. Оба этих персонажа работают с одним репозиторием кода. Они работают вместе над созданием кода, а затем инженеры-программисты создают автоматизацию. Чтобы каждый раз, когда специалист по данным возвращает новую версию, она проверялась автотестами, и в результате становилась доступной для развертывания в производственной среде или среде выполнения. Опять же, она может выполняться в озере данных, во встроенной системе или сервере приложений. За мониторинг среды выполнения и производственной среды отвечает группа эксплуатации, которая тесно взаимодействует с программистами. Здесь группы разработки ПО (dev) и эксплуатации (ops) работаю вместе, чтобы реализовать концепцию DevOps. Это не бросание кода через стенку по старинке в надежде, что группа эксплуатации сможет его поддерживать.
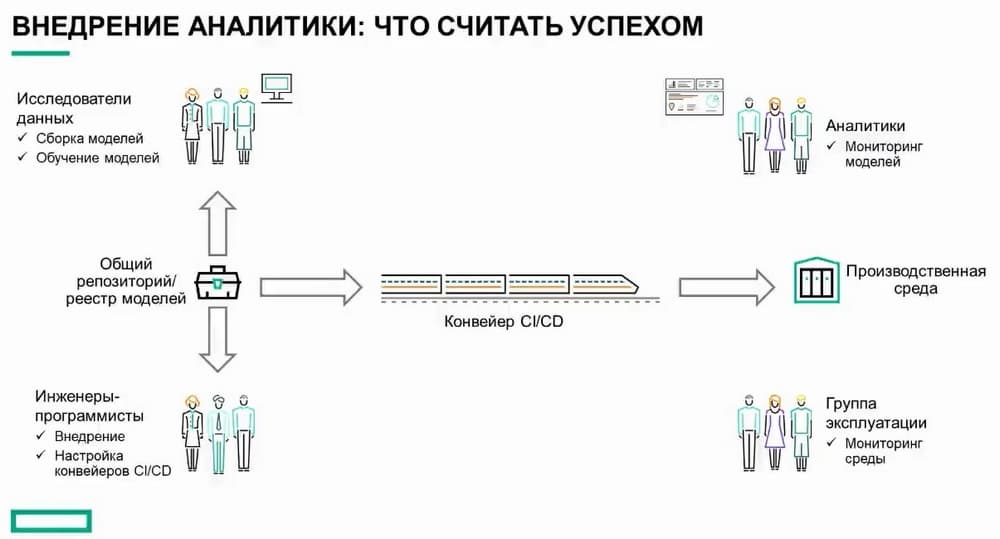
Группа эксплуатации вовлекается в самых ранних этапах и совместно с программистами определяет, как должна выглядеть система, как она масштабируется, какие ресурсы должны быть доступны, нужны ли графические процессоры постоянно или по запросу, как мы масштабируются, какая нужна производительность.
Итак, они вовлекаются в процесс проектирования на ранних этапах и работают как виртуальная команда. И наконец, последнее ключевое действующее лицо в этом процессе. Здесь еще много участников, но я рассказываю об основных. Речь идет об аналитиках, их часто называют специалистами по бизнес-аналитике или бизнес-аналитиками. Они отвечают за создание отчетов для различных направлений бизнеса. Эта должность уже существует в организациях. В контексте промышленного внедрения я рекомендую подключать их к процессу чтобы они могли формировать основные показатели производительности, панели мониторинга и предупреждения для аналитических моделей, развернутых в производственной среде. Это важно, потому что аналитические модели часто взаимодействуют с объектами реального мира, потоковыми данными, решениями, принимаемыми в реальном времени, веб-аналитикой, которые со временем меняются.
Меняются люди, модели поведения, в уравнении появляются новые переменные. Модели же со временем становятся все менее эффективными, устаревают. Об этом можно узнать, только отслеживая эффективность самих моделей, алгоритмов, результатов прогнозирования. Если для аналитиков настроены предупреждения и панели мониторинга они смогут уведомить группу специалистов по данным. Они могут быть в одной команде или в разных, но аналитики могут сообщить специалистам по данным о том, что их модель уже не так эффективна. Мы думаем, что в среде что-то изменилось. В соответствии с принципами промышленного производства мы не начинаем с нуля, не возвращаемся к началу сборки. Если использовать автомобильную аналогию, обнаружив что переключения коробки передач происходит не так как следует, мы будем рассматривать только этот узел. Также и в промышленном анализе данных. Специалисты по данным могут вернуться к этой модели. Причем сделать это может и начинающий специалист, что дает нам еще больше свободы. Не нужно искать узкого специалиста с немыслимой квалификацией. Возможно, разобраться с этой моделью и специалист начального уровня путем восстановления среды до момента, когда эта модель была развернута. Мне нужна среда разработки где можно посмотреть код, структуру приложения, библиотеки, инструменты и платформы, использованные для построения данной модели, связанные с ней метаданные, набор данных для обучения модели. Давайте изменим ее, соберем, выполним, переобучим и затем вернем в репозиторий. Конвейер CI/CD получит это изменение, проверит его и выполнит повторное развертывание. Возможно у группы эксплуатации есть политика пересборки и повторного развертывания, тогда все это производится автоматически. Это эффективный цикл анализа данных в масштабных инфраструктурах. Он позволяет организации перейти к управлению на основе данных.
Как избавиться от трудностей в этих трех областях?

Во-первых, необходимо избавиться от организационной разрозненности, создав виртуальную команду специалистов. Это позволяет получить максимум от сотрудников. При решении задач нам не придется полагаться на изолированные группы. В виртуальной команде мы согласуем все направления, чтобы ключевые сотрудники могли работать максимально эффективно.
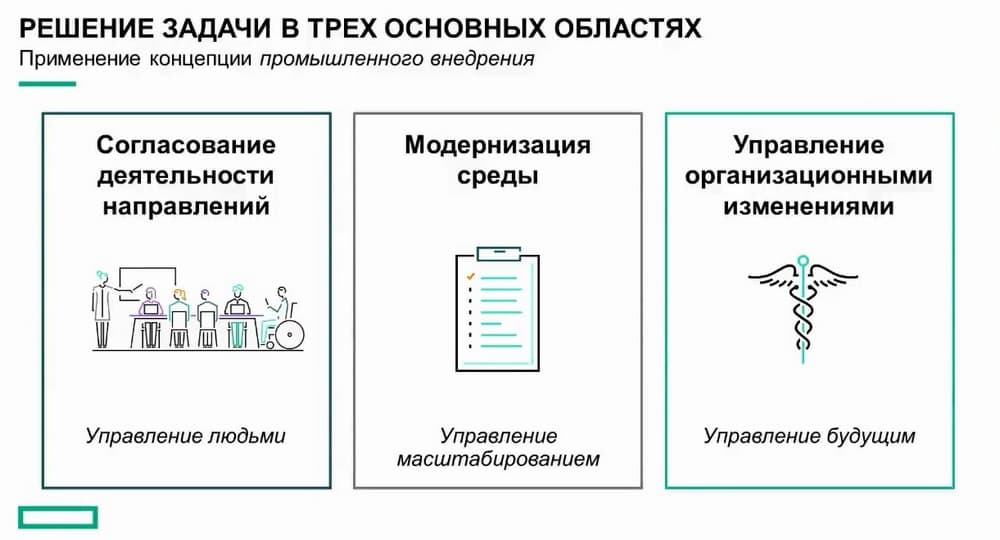
Во-вторых, нам не нужно модернизировать среду, можно развернуть лучшую инфраструктуру. Нам нужно установить графические процессоры и сделать их доступными по требованию, чтобы специалисты по данным могли ими пользоваться, когда необходимо и продуктивно работать. Также нам необходимо подключить ПО для управления инфраструктурой, чтобы мы могли выполнять эти операции повторно в рамках компании, внедряя как можно больше средств автоматизации, чтобы запустить поточную линию. Наконец, нам нужно позаботиться об управлении изменениями в компании. Нам нужно подумать, каким образом результаты применения этой концепции промышленного внедрения анализа данных подтолкнут организацию к изменению бизнес-процессов. Нужно подумать, как адаптировать и реагировать, переходить к приложениям на основе данных. Важно уделять этому внимание, чтобы управлять изменениями и иметь возможность масштабироваться с учетом будущих задач.

Подводя итог хочу напомнить о трех ключевых идеях. Во-первых, обработка и анализ данных – это командный спорт. У нас есть основные игроки и ключевые позиции, но это лишь отдельные функции. Только когда они все объединяются и работают для достижения общих целей, решают сложные задачи автоматизации и организационные проблемы, компания может работать эффективнее. Во-вторых, мы сможем это сделать, только располагая подходящими технологиями. У нас есть модернизированная, дифференцированная инфраструктура, например, графические процессоры, доступные этим пользователям. У нас есть ПО для максимально возможной автоматизации процесса, чтобы эти операции можно было выполнять снова и снова. Наконец нам нужно будет продумать как организация будет меняться и адаптироваться. Организационные изменения – это самая трудная часть. Подвести ее к осознанию того, что каждое решение должно приниматься на основе данных одна из основных задач промышленного внедрения.










