Сегодня мероприятие OCS Distribution и Polymatica с Gelarm рассматривает возможности применения искусственного интеллекта в мониторинге технологических процессов. На мероприятии представлены отечественные программные решения: • аналитическая платформа Polymatica BI для обработки данных с использованием алгоритмов интеллектуального анализа и машинного обучения, • система управления обработкой информации GIMS Automation для настройки API, сценариев обработки информации.
Сегодня в мероприятии принимают участие Михаил Александров, технический директор по продукту Polymatica ML, Илья Ушанов, генеральный директор ООО "ГЕЛАРМ" и Алексей Бредихин, менеджер по работе с ключевыми клиентами, Polymatica.
Компания Polymatica – это российский разработчик одноименной аналитической платформы, на рынке компания присутствует с 2011 года, пользователями платформы являются уже более 30 тысяч человек в России и в Европе.
Компания представлена в 5-ти отраслях: госсекторе, ретейле, энергетике, банках и телекоме, используется в 4-х критически важных приложениях Правительства РФ, при этом осуществлено 37 проектов в России и 8 – в Европе.
В Федеральной налоговой службе РФ Polymatica используется наиболее важный проект вендора при решении задач налоговой аналитики. На слайде видны клиенты вендора.

Что касается продуктовой линейки компании Polymatica, то в настоящий момент она комплексно закрывает все вопросы по работе с данными. У вендора сейчас 3 модуля.

Модуль Polymatica Dashboards – это конструктор информационных панелей, дашбордов и виджетов, рабочего стола руководителя, ситуационного центра. Здесь не требуется программирования, есть возможность встраивания дашбордов в сторонние приложения и возможность добавления пользовательских виджетов, без привлечения для консультаций сотрудников вендора.
Модуль Polymatica Analitics – этоn модуль позволяет работать с большими объемами данных в режиме близком к реальному времени.
Модуль Polymatica ML – этот модуль вышел на рынок в конце 2021 года. Это модуль для следующего этапа работы с данными, с применением модели машинного обучения и ИИ.
Платформа вендора разворачивается в инфраструктуре заказчика и поддерживается работа в закрытом контуре.
Затем слово взял Илья Ушанов, генеральный директор компании "ГЕЛАРМ".

Компания "ГЕЛАРМ" была образована в 2017 году, у сотрудников этой компании опыт в 12 лет по построению систем мониторинга и управления, они работали с такими компания как Мегафон, Вымпелком и т.д. Компания уходим от внедрения систем мониторинга и переключилась на продуктовый стек, в течение пяти лет разрабатывает свою продуктовую линейку, которая состоит из трех продуктов. Первый продукт GIMS Monitoring предназначен для сбора информации из различных источников и обработки этой информации. Второй продукт GIMS Inventory занимается инвентаризацией оборудования, ПО и различных процессов. И третий продукт GIMS Automation – это модуль, предназначенный для обработки событийной и метриковой информации.
В области телекома и энергетики у вендора накоплен большой опыт. Сейчас копании интересно создание систем мониторинга и управления именно для промышленного сектора, она совместно с компаний Polymatica сделала комплексное решение. Что вендор предлагает: есть технологический процесс, с которого снимаются определенные метрики, события, оборудование, ПО, которые управляют этим технологическим процессом, затем эти метрики обрабатываются, анализируются, формируются оптимальные параметры функционирования этого процесса и дальше эти управляющие команды можно инициировать на оборудование.
В результате получается единое окно, в котором видны единые отчеты как функционирует производственный процесс, индивидуальный технолог может подстраивать какие-то этапы технологического процесса.
GIMS Automation подключается к различным источникам данных, собирает параметры оборудования, параметры функционирования, параметры потребления расходных материалов, инженерные параметры, такие, например, как токи, размеры щелей и т.д. Далее, собранная информация передается в GIMS Monitoring. Эта метриковая информация сохраняется, и получается некий DataSet. На его основании модуль Polimatica ML анализирует эти данные и ищет оптимальные параметры для того, чтобы построить тот или иной этап технологического процесса. Т.е. фактически он формирует обратную связь. Технологический процесс выполняется, с него сняли данные, увидели, например, что он функционирует некорректно, либо не оптимально, проанализировали эти данные, определили оптимальные параметры, которые необходимо через обратную связь инициировать на оборудование, и через модуль GIMS Automation мы отправили управляющую команду на оборудование.
Модуль GIMS Inventory позволяет выполнять инвентаризацию. Для того, чтобы технологическим процессом управлять, мы должны понимать, где, какие модули в нашем технологическом процессе используются, какими параметрами они обладают, как они взаимосвязаны с другими модулями и т.д. Также в GIMS Inventory можно описывать некие логические сущности, которые относятся к этому техпроцессу, в частности подвязывать к готовой выходной продукции контрактную базу и т.п.
Разберем это на примере производства глинозема. Классический процесс получения глинозема из бокситов: сначала боксит поступает в дробилки, потом в автоклав, сгуститель, фильтр-пресс, осадитель, обжигатель-печь. С каждой части технологического процесса мы можем снимать свои параметры. И наша задача состоит в том, чтобы не просто снять и прочитать эти параметры, но, прежде всего в том, чтобы понять, насколько эти параметры оптимальны для создания наиболее качественного продукта. Так, на этапе дробления мы можем регулировать величину щели в дробилке или же размер шаров в шаровой мельнице для того, чтобы измельченный продукт оптимально соответствовал заданным параметрам. На этапе выщелачивания в автоклавах мы можем регулировать температуру, концентрацию щелочи. На участке сгущения мы можем регулировать расход реагентов, величину разгрузки, т.е. интервал времени, через который необходимо разгружать сгуститель. В фильтр-прессе мы можем управлять временем фильтрации, высадителем мощности и температуры. Все эти математические параметры собираются в нашу базу мониторинга, и после этого модуль Polimatica, анализируя накопленные ранее исторические данные и сравнивая их с текущими, определяет, насколько оптимально в настоящий момент функционирует технологический процесс. И задача модуля – сформировать наиболее оптимальные параметры для производства технологического процесса.
Классическая обратная связь у нас работает следующим образом: мы собираем данные, анализируем их, понимаем, как нужно скорректировать процесс, производим корректировку, снова делаем замеры, определяем, насколько эффективна была первая корректировка, делаем вторую корректировку, и т.д. Такого рода корректировки можно производить до бесконечности. Задача модуля Polimatica – сразу найти самый оптимальный вариант корректировки для того, чтобы не приходилось производить их бесконечно. Это существенно сокращает время настраивания процесса и затраты на расходные материалы. Например, на участке сгущения наш модуль позволяет сразу подобрать оптимальный расход коагулянтов с тем, чтобы не происходило его перерасхода, и продукт на выходе был по всем параметрам наиболее высокого качества.
Решение, которое мы предлагаем, обладает следующими преимуществами: все продукты компании Polimatica и "ГЕЛАРМ" находятся в реестре отечественного ПО. Наш модуль позволяет очень быстро создавать коннектеры к различному оборудованию и ПО. В модуль GIMS Automation встроен конструктор, который позволяет быстро для различных протоколов делать подключения и собирать информацию. Также на базе модуля GIMS Automation есть возможность гибко создавать процессы управления производством. Мы можем описывать бизнес-логику, например, передачи данных в системы плановых работ, в системы управления, в системы финансового управления и т.п. И использование алгоритмов ИИ для наиболее оптимального функционирования производства. Использует такие математические модели, которые позволяют оптимально и быстро подстраивать технологический процесс.
Затем слово взял Алексей Бредихин, менеджер по работе с ключевыми клиентами, Polymatica.
Первую часть, которую мы обсудили – это построение с интеграцией с УТП, т.е. с оборудованием, сбор информации с датчиков и последующая обработка. В такой конструкции это прекрасно работает. У нас есть набор жестких правил, четких сигналов для мониторинга и это решение закрывает эти потребности. А если мы хотим добавить ИИ в наше решение то, тут в результате обсуждения и проработки с коллегами у нас получилось интересное решение. Наш модуль Polimatica ML дополняет процесс сбора и мониторинга технологических параметров возможностью использования ИИ.
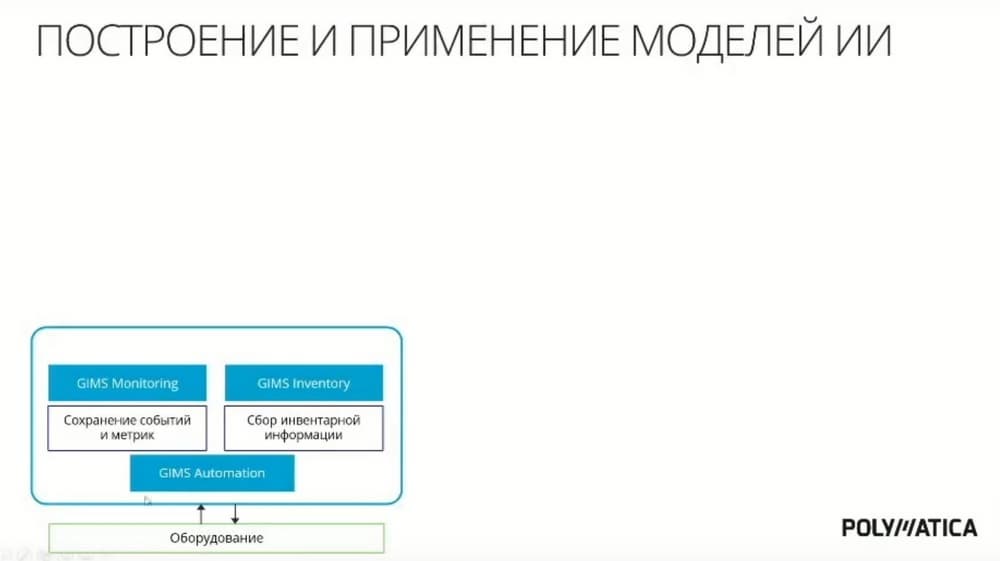
Давайте посмотрим, как это выглядит, когда мы дополняем это правилами. Первый важный момент для любого ИИ, это то, что необходимо накапливать исторические данные для построения моделей, сбор витрины и решения коллег позволяет эту важную часть закрыть, т.е. обеспечить сбор данных и накопление исторических данных для дальнейшего применения. Далее, перед тем, как строить модель, обычно аналитик-эксперт берет и смотрит, что представляют собой собранные данные. И здесь начинается использование модуля Polimatica ML. Он делает этот первый шаг – исследование данных функционал, который позволяет посмотреть на то, насколько качественны полученные данные, посмотреть выбросы, провести предварительную аналитическую обработку, например, заполнить пропуск, если приходят какие-то сбои. Поступление информации с датчиков. Ну и т.д. На этом шаге мы понимаем, что представляют собой данные, какие модели мы на этом можем построить.
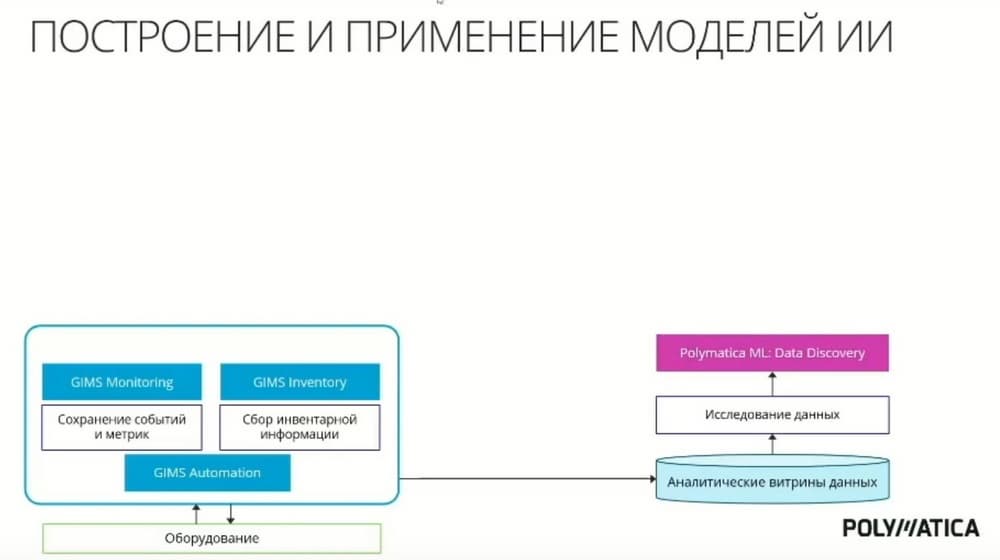
Следующий шаг - это построение различных моделей ИИ. Это позволяет сделать модуль Polimatica ML. Основная идея в том, что функционал модуля ориентирован на построение моделей не профессиональными Data-Set-тистами, а экспертами в предметной области. Это важно. Мы не раз сталкивались с тем, что профессиональные Data-Set-тисты и функциональные эксперты с трудом находят общий язык для согласования требований и для построения модели в ходе обсуждения процесса.
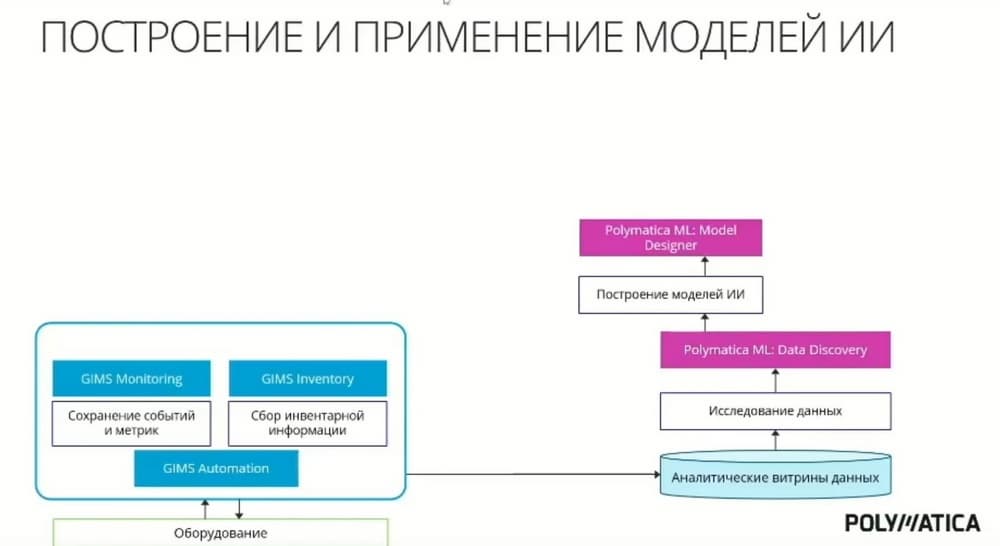
И этот модуль позволяет функциональным экспертам без глубокого погружения в математику, программирование и статистику, используя данные технологических процессов, строить модель. При этом как бы хороши ни были эти модели, никто не отменяет классических экспертных правил. Наше решение позволяет с одной стороны настроить модели машинного обучения, которые строятся на исторических данных и выявляют некоторые закономерности, используя алгоритмы прогнозирования. С другой стороны, наше решение позволяет настраивать бизнес-правила и, что особенно важно, затем их комбинировать. И в результате у нас появляется единый репозиторий с моделями ИИ, которые затем мы можем применять.
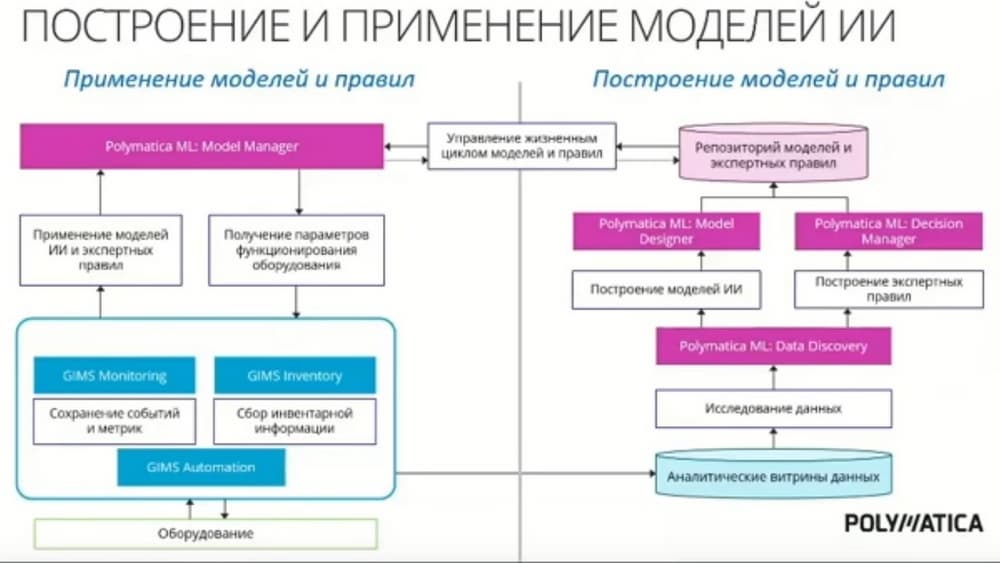
После того, как у нас появляются правила модели, следующим шагом будет ее применение. Тут вступает в работу наш следующий компонент, который отвечает за управление жизненным циклом модели и правил. И он позволяет сформированному репозиторию быстро и просто запускать эти модели и правила, встраивая их в процесс принятия решений, в том числе интегрируя с системами мониторинга технологических процессов. Этот процесс выглядит следующим образом. Из системы мониторинга GIMS Automation нам поступают значения параметров, которые собраны с технически предобработанного оборудования. И поступают на вход по нашим модельным экспертным правилам. Эти модели дают некоторые рекомендации, которые в том числе могут поступать в GIMS Automation и оказывать управляющее воздействие на оборудование технологической линии. Это в идеале. Ну, а обычно, для начала, выдаются просто некие уведомительные рекомендательные сигналы, которые поступают оператору, и он затем принимает решение.
При этом важным моментом является то, что мы обеспечиваем сбор информации о работе моделей, потому что модели не вечны, они могут портиться, точность их показаний может ухудшаться. И экспертные правила тоже подчас требуют неких ревизий. А наше решение позволяет собирать характеристики, проводить оценку точности модели, и в случае, если точность модели упала ниже определенного порога, мы сигнализируем ответственным сотрудникам о том, что пора модель либо переобучить, либо подумать о создании новой модели. Таким образом наше комплексное решение закрывает полный цикл от сбора информации с производственных систем, накопления информации для дальнейшего анализа построения модели, до построения модели и применения ее в реальных технологических процессах.
Теперь чуть подробнее про сам модуль Polimatica ML. Когда мы начинали разрабатывать этот модуль, перед нами были поставлены две задачи. Первая – создание модели машинного обучения, в первую очередь функциональными экспертами. Понятно, что люди, которые работают с модулем, должны иметь представление о том, что такое ИИ и что такое МО, но все математические, технические и статистические нюансы скрыты от пользователей графического интерфейса.
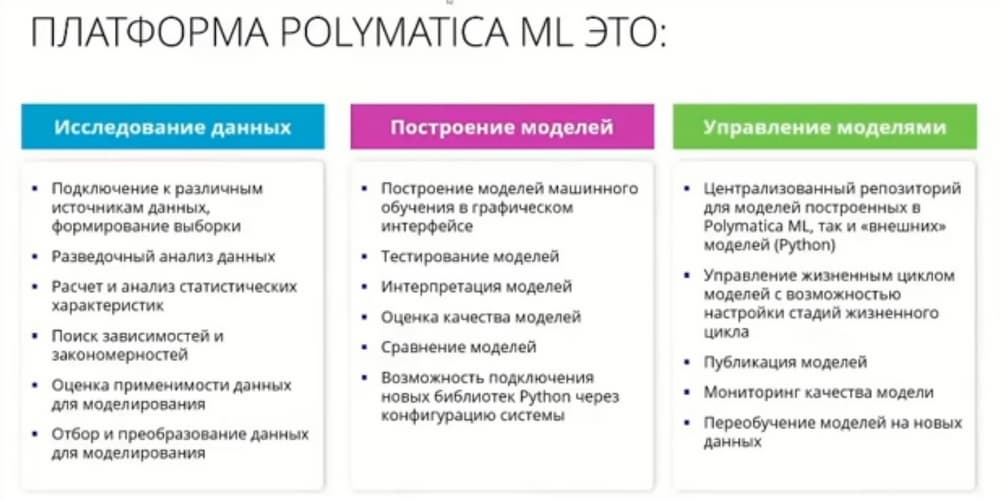
Строят модели по обработке и затем их применяют. Второй важной задачей являлось применение модели МО и управление жизненным циклом модели. Первое, что позволяет делать модуль, это оперативно внедрять модели МО в бизнес-процесс компании и интегрироваться с другими решениями. Мы по щелчку мыши можем развернуть модель для доступа, либо для пакетной обработки данных, если эта обработка требуется по регламенту. Причем пакетная обработка может требоваться как для больших массивов (раз в сутки или раз в месяц), так и для более оперативного (раз в 15 минут, раз в полчаса). Мы обеспечиваем контроль за точностью модели МО. Потому что внедрить и запустить модель – это лишь половина успеха. Важно, особенно, если модель используется в таких критических задачах, как мониторинг технологического процесса, если модель начинает выдавать некорректные значения, т.е. точность модели падает, вовремя поймать этот момент и либо переобучить модель, либо эту модель вывести из эксплуатации и построить новую.
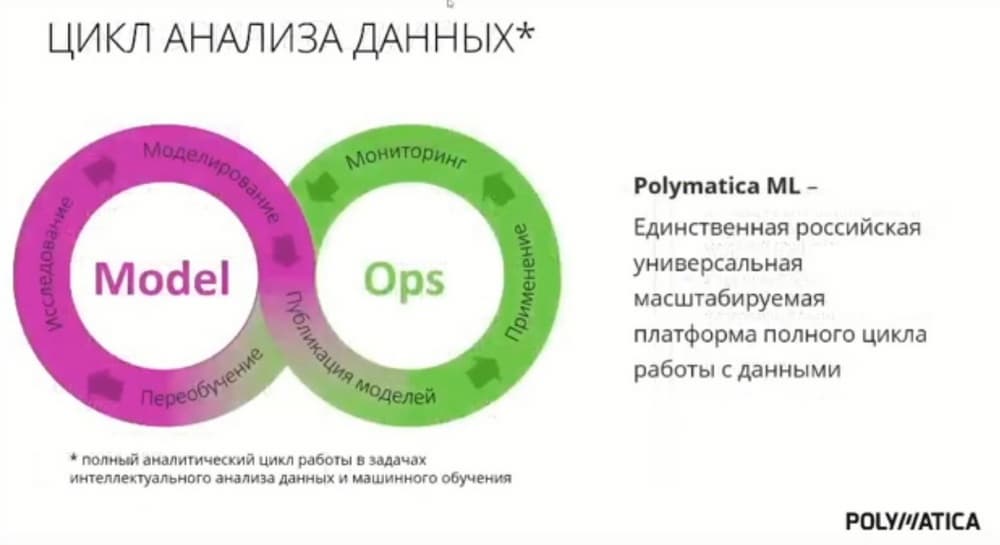
Еще один важный момент. Поскольку мы быстро и просто можем публиковать модели и обновлять их, важно, чтобы перед публикацией модель прошла все необходимые согласования. Это тоже обеспечивается нашими решениями. Т.о. мы закрываем весь цикл по работе с моделями ИИ, начиная от исследования данных и аналитической предобработки, и заканчивая непосредственным построением моделей, публикацией и применением моделей, мониторингом их работы и последующим переобучением.
Теперь несколько слов о архитектуре решений. Это микросервисная архитектура. Важной особенностью является то, что у нас есть возможность быстро и просто подключать новые алгоритмы и новые библиотеки с алгоритмами МО.
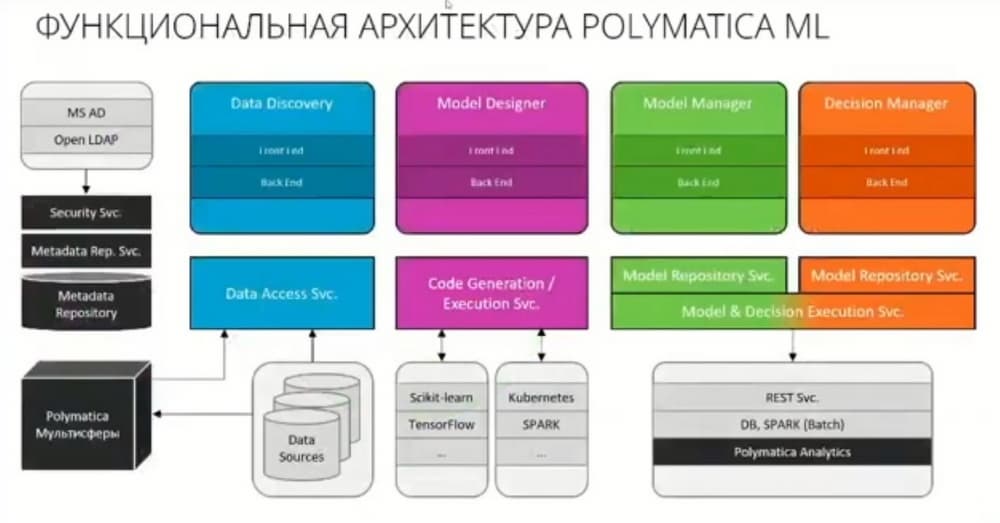
Подключение новых библиотек, новых версий библиотек, новых алгоритмов происходит через конфигурацию системы. И есть возможность заводить специфические узлы и алгоритмы, которые особенно интересны в применении в промышленности, когда у нас идет комбинация классических методов МО с физико-математическим моделированием. Но в принципе такие вещи мы тоже можем делать. Можем встраивать такие алгоритмы в наши решения. Решения изначально поддерживают горизонтальное масштабирование, поддерживается инвентаризация и обеспечивается развертывание моделей быстро и просто либо в виде сервисов для работы через Rest, либо в пакетном варианте.
Важно то, что мы интегрируемся с нашими модулями продуктовой линейки Polimatica и модулем Polimatica Analitics, который позволяет нам проводить исследование, которое позволяет смотреть на данные с разных сторон.
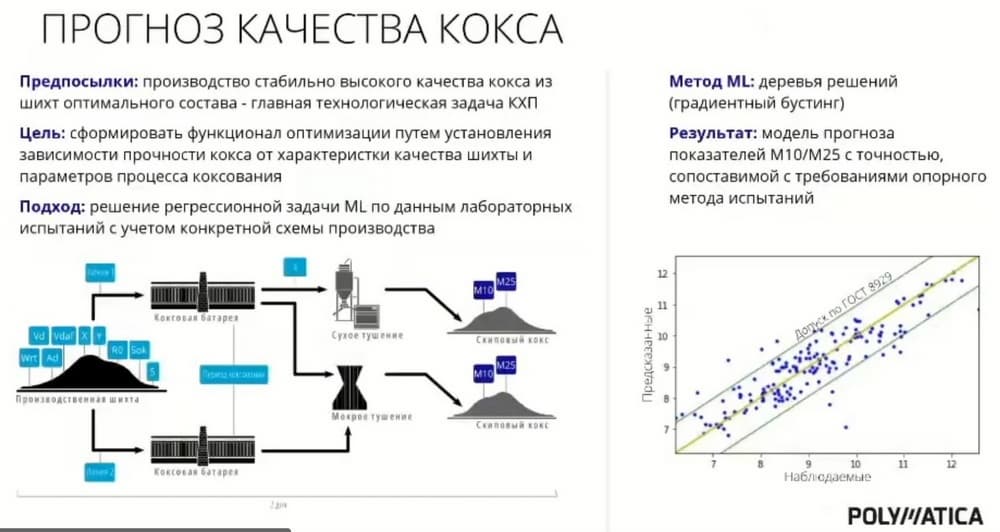
Один из примеров пилотного проекта, который сейчас находится в проработке. Первые результаты уже показаны. Это прогнозирование качества функций в коксохимической промышленности, где мы по различным параметрам из производственной шихты предсказываем, какое качество продукции получится, и далее можем использовать для построения оптимального производственного процесса. Тут использование модели позволяет гораздо быстрее реагировать, чем на лабораторное исследование. В принципе этот параметр нужно исследовать лабораторно, можно замерить, но для того, чтобы провести лабораторные испытания потребуется гораздо больше времени, и при получении результатов лабораторных испытаний как-то повлиять на производственный процесс невозможно. Т.е. использование модели с одной стороны обеспечивает приемлемую точность в пределах допуска по ГОСТу, и с другой стороны, реагировать оперативно, оптимально выстраивая параметры.

Преимущества решения. Это решение входит в реестр российского ПО, что важно в текущей ситуации. Важным также является то, что построение модели или ее адаптация может выполняться функциональными экспертами. Обычно это следующий сценарий о том, что, либо мы, либо совместно с партнером проводим первое внедрение и последующую поддержку и адаптацию модели или построение новых выполняется клиентами самостоятельно, т.к. интерфейс не требует каких-то специфических знаний и привлечения профессиональных data-сайнтистов. Сроки внедрения небольшие. На пилотный проект мы можем выходить очень оперативно. Основной момент – это наличие накопленных данных. Если у вас имеются накопленные исторические данные, то мы можем быстро пропилотировать и перейти к эксплуатации. Если же исторических данных нет, то имеет смысл внедрение выполнять в несколько этапов. Начинать внедрение, обеспечив сбор и накопление исторических данных с производственных линий, и после этого срок зависит сильно от производственной специфики, это может и три месяца, и даже больше. И после этого можно быстро построить модели и их использовать.










