Современная инфраструктура становится все сложнее, усложняются также и взаимодействия между ее разными уровнями. ИТ-администраторам все труднее обеспечить ее оптимальную и бесперебойную работу. Поиск неисправностей превращается в поиск иголки в стоге сена, что ведет к авралам и взаимным упрекам.
На этом мероприятии вы узнаете, как HPE InfoSight наблюдает за взаимосвязанными системами, использует искусственный интеллект и машинное обучение, обучаясь с помощью инсталлированной базы, как автоматизирует разрешение самых сложных проблем. Речь пойдет о реализации концепции AI Ops на базе трех принципов инфраструктуры: самоуправление, самовосстановление и самооптимизация.

Сегодняшнее мероприятие проводит Ронак Чoкши, старший менеджер по маркетингу продуктов в HPE. Сегодня речь пойдет о HPE InfoSight и об опыте использования заказчиками инфраструктуры с искусственным интеллектом на базе HPE InfoSight.

Благодаря внедрению искусственного интеллекта меняются практически все отрасли, повышается эффективность работы многих предприятий, предлагается дифференцированное обслуживание заказчиков, создаются инновационные продукты и услуги, ориентированные на данные. То же касается инфраструктуры – она должна сама «мыслить» принимать решения и даже самостоятельно изменяться. Она должна исключать непрерывны мониторинг, к которому вынуждают типовые платформы ИТ-операций. Только так вы сможете использовать ее гибкие возможности и инновации.
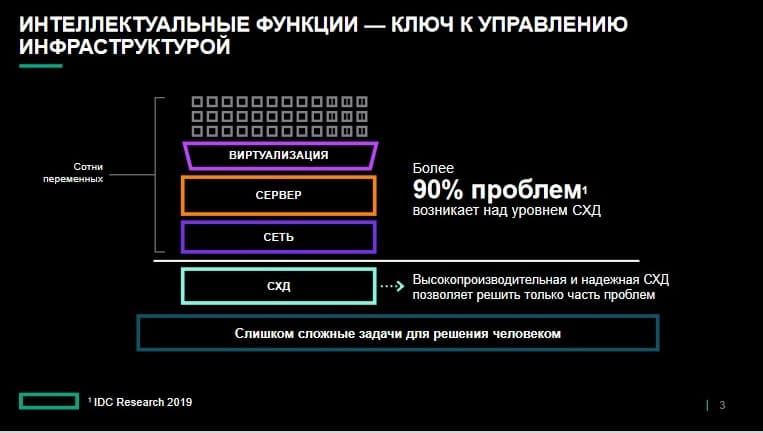
Со временем инфраструктура многих предприятий все больше усложняется, чему способствуют СХД, сетевые серверные системы, виртуализация, различные среды, сотни приложений на базе микрослужб и бесконечное взаимодействие между ними в рамках нескольких гибридных сред. И на каждом уровне возникают проблемы. Администраторам инфраструктуры приходится учитывать множество переменных, просматривать массу журналов и вручную устранять проблемы методом проб и ошибок. Подобными методами очень сложно выявить первопричины и устранить эти проблемы, чтобы в итоге сократить простои и перерывы в работе. Многие из таких проблем возникают на уровне СХД, большая их часть фактически проявляется на уровне выше или же при взаимодействии из-за несовместимости между уровнями. Здесь речь о том, что ИТ-отделу нужна интеллектуальная платформа, которая бы учитывала особенности уровней и связанные с этим сложности, наблюдала за инфраструктурой и взаимодействием в рамках всего комплекса, непрерывно обучалась и помогала предотвращать проблемы. Она поможет ИТ-отделу избежать постоянных авралов, поисков виноватого и поддерживать непрерывную работу приложений.
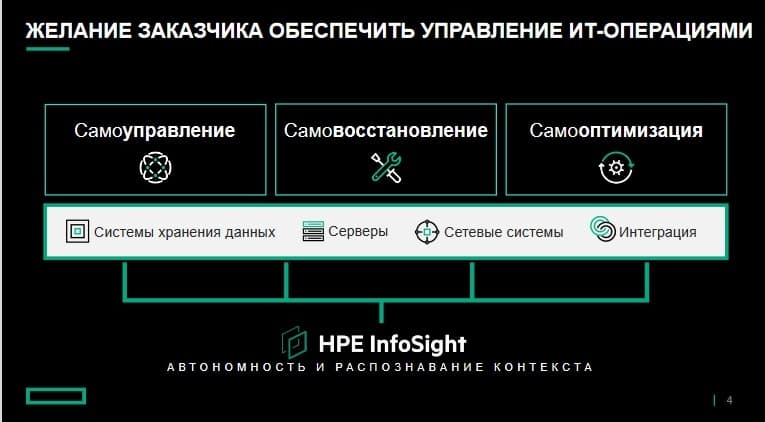
С учетом всех этих сложностей компании больше не хотят заниматься инфраструктурой, они хотят иметь инфраструктуру автономную. В HPE автономные ИТ и автономные операции определяются как сочетание трех основных принципов.
Самоуправление. То есть инфраструктура должна освободить ИТ-специалистов от ежедневных забот по управлению ею.
Самовосстановление. Имеется в виду, что она должна автоматически прогнозировать и предотвращать проблемы.
Самооптимизация. Она должна обеспечивать идеальное состояние среды, поддерживая баланс между производительностью, затратами и ресурсами.
Таково передовое решение на основе искусственного интеллекта для инфраструктуры - HPE InfoSight. С помощью этих инноваций компания HPE более десятилетия ведет отрасль к автономной ИТ-инфраструктуре. При создании этой платформы компания HPE руководствовалась принципами самоуправления, самовосстановления и самооптимизации.
HPE InfoSight встроена в предлагаемые компанией HPE СХД, серверы, сетевые решения, а также решения конвергентной инфраструктуры. Это решение искусственного интеллекта дает заказчикам не только автономность операций, но и осведомленность о контексте. Прогнозы этого вендора, рекомендации, оповещения и автоматизированная поддержка учитывают особенности именно вашей ИТ-среды, рабочих задач и инфраструктуры. Это архиважно, поскольку все ИТ-среды разные. Приложения и рабочие задачи, выполняемые в инфраструктуре, уникальны для каждого предприятия и потому предлагать контекст в рамках прогнозов вполне логично. Это и предлагает платформа AI Ops.
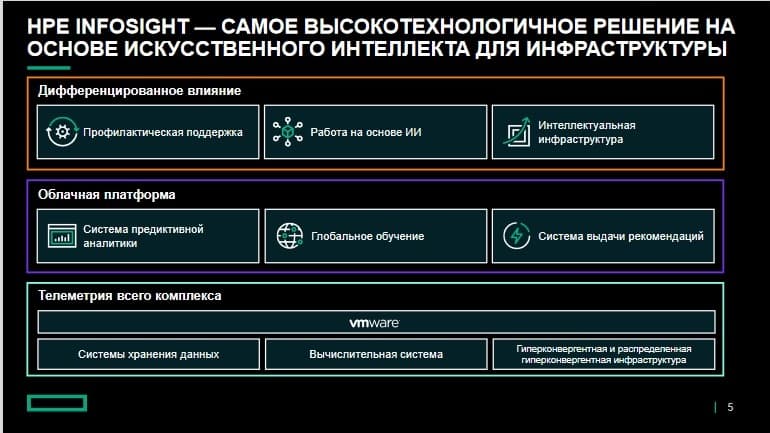
При создании HPE InfoSight применялся специальный подход. Сначала выполняется сбор и анализ телеметрических данных, поступающих от СХД, вычислительных и встроенных решений, виртуальных машин. Более десятилетия каждую секунду HPE InfoSight получает и анализирует данные миллионов датчиков. Это значит, что в каждую систему встроены тысячи датчиков, данные поступают со всего инфраструктурного комплекса, т.е. со всего подключенного оборудования, установленного вендором по всему миру. Данные передаются в облачную платформу искусственного интеллекта, где с помощью машинного обучения выполняется следующее.
Во-первых, осуществляется непрерывное изучение моделей приложений и рабочих задач всего установленного оборудования. Во-вторых, производится тренировка моделей машинного обучения и прогнозирование возможных проблем с помощью системы предиктивной аналитики. И, в-третьих, происходит составление на основе прогнозов конкретных рекомендаций по настройке инфраструктуры с целью предотвращения возникновения проблем. Это помогает предлагать заказчикам индивидуальные результаты.
Вендор предлагает автоматизированную прогнозную поддержку, т.е. прогнозирование, предотвращение и автоматическое разрешение проблем. Мы преобразуем ИТ-среды и операции заказчиков в операции с поддержкой искусственного интеллекта для чего даем рекомендации по их улучшению и непрерывному совершенствованию. Наконец, благодаря применению глобальной системы обучения для всего подключенного оборудования, последнее с каждым днем становится все более эффективнее и надежнее.
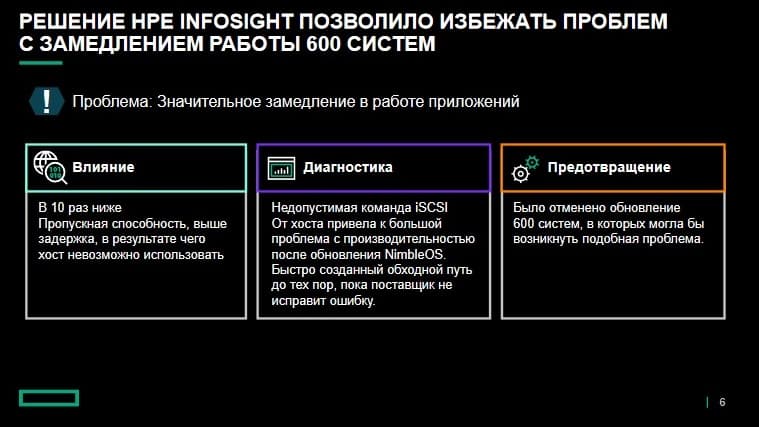
Вот одна из историй заказчиков. Он обратился к нам, когда поле обновления нашей ОС до последней версии в 10 раз снизило производительность всех его приложений. Мы выяснили причину с помощью HPE InfoSight. Оказалось, что проблема возникла не с массивом. С уровня виртуализации в массив поступала недопустимая команда iSCSI, что и вызвало избыток повторных попыток и падение производительности. Чтобы обойти проблему мы разработали для заказчика исправление, но на этом не остановились. Мы решили определить, не могло ли возникнуть такие же проблемы у кого-то еще в рамках базы установленного оборудования. Мы создали для этой проблемы сигнатуру (они создаются для точной фиксации параметров проблемы) с учетом принципов расширенного распознавания моделей. С помощью сигнатуры мы провели поиск конкретных конфигураций версии ОС, средств виртуализации, данных настройки и т.д. Мы запустили мониторинг данных телеметрии систем, подключенных к базе установленного оборудования. И нашли 600 заказчиков, у которых могла возникнуть точно такая же проблема. Мы внесли эту версию ОС в запретный список и посоветовали заказчикам временно пропустить данное обновление ОС. Таким образом мы предотвратили возникновение этой проблемы у 600 заказчиков.
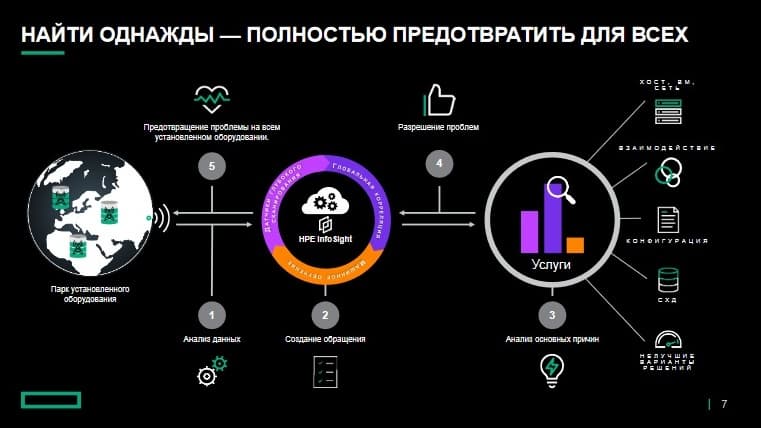
Теперь посмотрим как это произошло. HPE InfoSight собирает телеметрию с подключенных систем глобальной базы установленного оборудования и непрерывно анализирует модели их производительности. Анализ телеметрии позволяет выявлять в инфраструктурном комплексе даже самые неявные проблемы с хостом, виртуальными машинами, совместимостью компонентов сети, конфигурацией и рабочими задачами приложений. Не говоря об СХД. Заметив в среде заказчика новую проблему, мы выявляем ее причину и создаем для нее сигнатуру, чтобы убедиться, что эта проблема больше не повториться у других заказчиков. Если же механизм автоматического сопоставления сигнатур обнаружит, что в среде других заказчиков появилась та же сигнатура с аналогичным алгоритмом поведения, с такой же конфигурацией и у них может возникнуть подобная проблема, мы тут же открываем заявку, дает заказчикам рекомендации по устранению проблемы и закрываем заявку.
Платформа HPE InfoSight создана по принципу «раз увидеть, значит предотвратить навсегда». За десятилетие использования HPE InfoSight были создано несколько сотен таких сигнатур, что помогла предотвратить проблемы еще до их проявления.

Теперь поговорим о одной из функций HPE InfoSight. Это рекомендации, для которых применяются искусственный интеллект и машинное обучение. Представим, что платформа операций искусственного интеллекта могла бы подсказать как обеспечить оптимальное использование инфраструктуры, отказаться от неэффективного выделения ресурсов, заранее настроить эти ресурсы так, чтобы избежать простоев в работе приложений, при этом прогнозировать проблемы, которые могут возникнуть в ближайшие недели и предотвращать их.
Рассмотрим примеры. Предположим, что перед замедлением или прерыванием работы остальных томов, наблюдается повышенная активность тома 1. Тогда чтобы повысить производительность тома 2, мы посоветуем применить к тому 1 систему QoS.
Другой пример. На основе исторически сложившихся моделей рабочих задач, приложений и т.д., мы можем спрогнозировать, что, скажем, через 23 дня будет превышена емкость пула ресурсов хранения данных. Чтобы избежать простоев, мы посоветуем добавить ресурсов и точно укажем необходимое их количество.
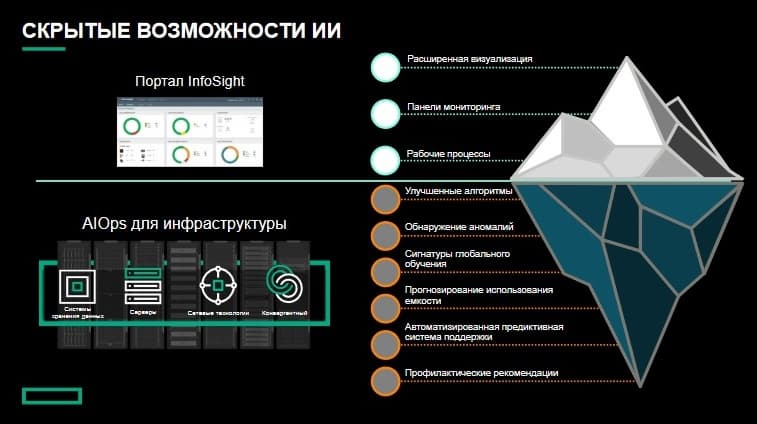
Заказчикам хорошо знаком портал InfoSight. На нем представлены расширенные визуализации, информационные панели и рабочие процессы, которые можно интегрировать в инфраструктуру. Здесь представлены и основные данные и оповещения об инфраструктуре пользователей, а также незримая работа искусственного интеллекта, разработанного специалистами HPE, обнаружение отклонений, применение сигнатур глобального обучения, прогнозирование использования ресурсов, автоматизация прогнозной поддержки и предоставление упреждающих рекомендаций. Все это интегрировано в платформу и представленные на портале визуализации, информационные панели и рабочие процессы.
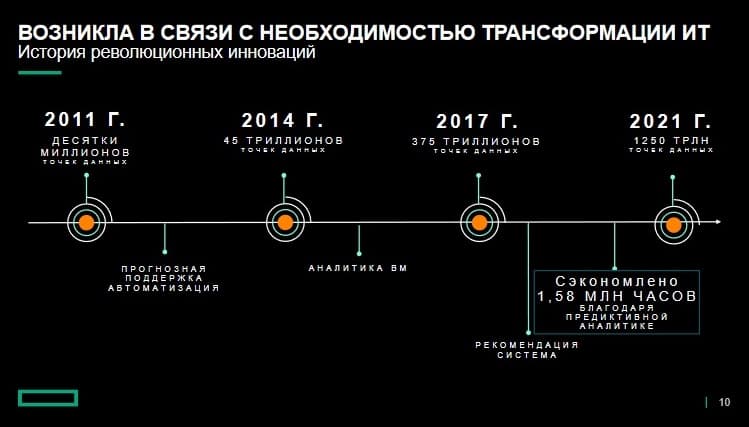
Этот переход вендор начал около 10 лет назад с системы Nimble Storage, сбора данных телеметрии и корреляции базовых данных. Их применили для автоматизации поддержки и тогда же предложили автоматизированную систему прогнозной поддержки. Через несколько лет вендор представил средства аналитики ВМ для получения заказчиками дополнительных идей об их виртуальных средах. Еще через несколько лет была представлена первая версия системы рекомендаций, после чего стали предлагать конкретные, директивные рекомендации. На предыдущем слайде изображен имевший место в последние 10 лет рост количества собираемых данных. На данный момент нам удалось сэкономить более 1,58 млн часов простоя, благодаря прогнозированию и предотвращению проблем.