Tradicionalmente, los sistemas DLP se basaban en el principio de proteger lo que se conoce. Pero si por un momento admitimos la idea de que podemos no saber algo, inmediatamente descubrimos una gigantesca "zona gris" de eventos no cubiertos por las políticas de seguridad. Es similar a los antiguos mapas marinos, donde la mitad del mundo no existe y la otra mitad está habitada por diversas criaturas y monstruos. ¿Es seguro navegar por un mapa así?
En muchos sistemas DLP, las cosas siguen siendo más o menos iguales, solo que la "zona gris" en lugar de dragones y sirenas está poblada por falsos negativos, procesos de negocio ilegítimos y falsos positivos: "incidentes" que no lo son. Para navegar con seguridad, debes saber a dónde vas.

Un sistema DLP de nueva generación se diferencia de los clásicos en que no deja misterios en forma de falsos negativos, falsos positivos y "zonas grises". En el evento, profundizaremos en el tema de los falsos negativos y falsos positivos, compartiremos recomendaciones sobre tecnologías y métodos para trabajar eficazmente con la "zona gris" de los flujos de información, para que pueda luchar contra las fugas, no contra los falsos positivos.
- Por qué aparecen los falsos negativos y falsos positivos. Y cómo los proveedores de sistemas DLP clásicos proponen resolver este problema, del que no se suele hablar en el mercado
- Cómo dejar los falsos positivos en el pasado. Tecnologías, automatización y ML para la actualización oportuna de las políticas de seguridad de la información, utilizando como ejemplo el sistema DLP InfoWatch Traffic Monitor.
- Posibilidades del aprendizaje automático para la agrupación de documentos frente al análisis manual de la "zona gris".
Hoy el evento está dirigido por Alexander Klevtsov, Jefe de Desarrollo de Producto de InfoWatch Traffic Monitor, empresa InfoWatch, y hablará sobre falsos negativos y falsos positivos, es decir, sobre los falsos negativos y falsos positivos del sistema DLP. Por qué es tan importante profundizar en cómo está realmente organizado el sistema DLP y qué se puede tomar aquí como métrica para evaluar la eficacia de su trabajo con él. Hablaremos de técnica, de detalles, no hablaremos de metodología, cultura de seguridad, sino de estos dos aspectos concretos. Y aquí tenemos una diapositiva preciosa: cómo vería un artista la problemática del sistema DLP, concretamente los falsos positivos y los falsos negativos.

Los falsos positivos, cuando hablamos de DLP, son el momento en que DLP considera algo una infracción que no lo es. Es decir, el sistema se activó ante algún evento, ante algún hecho, considerándolo una infracción, pero no hubo infracción. Un falso negativo es cuando el sistema deja pasar algo. Se produjo algún incidente, algo malo, pero el sistema DLP guardó silencio.
Aquí intentaré derrocar a algunos ídolos de su pedestal y cuestionaré tres tecnologías básicas del sistema DLP. Se trata de expresiones regulares, huellas digitales y diccionarios lingüísticos.

Hablando de falsos negativos y falsos positivos, tengo una receta para luchar contra estos falsos positivos. Es la transición del análisis de contenido al análisis contextual. El análisis de contenido es cuando el sistema puede detectar el número de una tarjeta de crédito, entender que esta correspondencia trata sobre logística, determina bien el tema, la estructura de los datos enviados, y el análisis contextual, además de permitir detectar algunos datos, también comprende el contexto empresarial. Pongamos un ejemplo elemental: que el nombre, los apellidos, el patronímico y el número de teléfono pueden ser simplemente una firma en una carta o alguien envió un contacto a un empleado para que interactúe con él. Y este puede ser el contacto de un cliente clave. Es importante entender que no es solo un teléfono y un nombre completo, sino que es necesario entender que es un teléfono y un nombre completo, por ejemplo, de un cliente VIP. Y hoy todo el evento tratará exclusivamente de esto, de cómo pasar del análisis de contenido, donde simplemente entendemos algunas estructuras de datos, la pertenencia a una u otra categoría, al contextual, cuando entendemos no solo la categoría de datos, sino también su valor, su importancia para el negocio, teniendo en cuenta la gestión documental o el proceso de negocio.
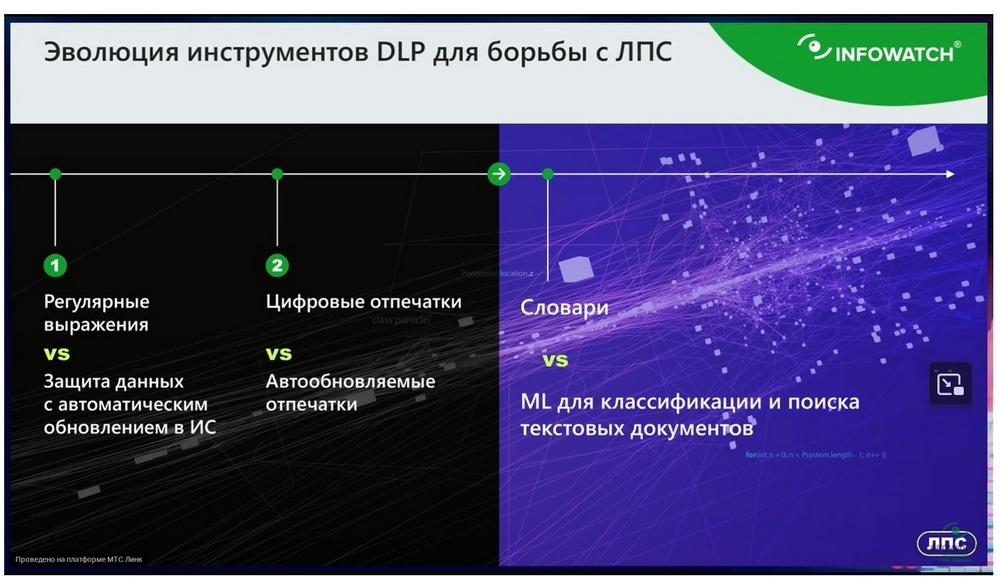
Expresiones regulares
Transición del análisis de contenido al contextual. Y todo esto en el marco del derrocamiento de tales ídolos de tres tecnologías básicas de DLP y cómo deben ser para ser más no sobre el contenido, sino sobre el análisis contextual.
Entonces, la primera tecnología de análisis que consideraremos, que criticaremos, que se ha convertido en un clásico del mercado DLP, son las expresiones regulares. Bueno, todo el mundo está familiarizado con cuando alguna construcción puede determinar cualquier detalle: número de tarjeta, teléfono, número de cuenta, NIF. Entonces, desde el punto de vista del análisis contextual, la expresión regular es lo más débil. Como ya he puesto el ejemplo, necesitamos distinguir la firma en una carta y los datos de algún cliente o incluso de un empleado que no es un empleado del departamento de clientes, no interactúa con otras contrapartes, no es una persona pública. Y desde el punto de vista de las expresiones regulares, sí, el sistema puede determinar que se trata de algún apellido-nombre-patronímico, algún correo electrónico, algún teléfono o incluso un número de personal, pero las expresiones regulares no entienden en absoluto si este nombre completo es el de un empleado, si este nombre completo es el de un cliente o si es simplemente una mención de alguna contraparte. Tenemos una tecnología de protección de bases de datos de clientes, protección de bases de datos de nomenclatura, protección de bases de datos de empleados, que comprende el contexto empresarial. Esto se logra integrándose con el sistema CRM, ABS o ERP, de donde extrae los datos y comprueba cada mensaje, cada carta, puede comprobar si se trata de datos de empleados, si se trata de datos de clientes o incluso, por ejemplo, realizar tal comprobación, que precisamente esta denominación es una mención de la base de datos de nomenclatura. Esta tecnología permite comprender claramente el contexto empresarial. Que no es solo alguna estructura, algún número, algún apellido, sino que es precisamente o un cliente, o un empleado, o un socio, o incluso alguna otra contraparte. La tecnología del sistema empresarial, donde se almacena el contexto, extrae los datos, y luego estos datos se comparan con cualquier mensaje interceptado. Y se puede decir con certeza que este número de teléfono del cliente, aquí está la diferencia fundamental entre el análisis de contenido y el contexto.

Huellas digitales
Cuando se toma una huella digital de un documento específico, entonces permitimos mencionarlo o revelar su fragmento. ¿Cómo pasar del análisis de contenido al contextual? En el mercado se ha establecido la regla de que las huellas digitales son o bien huellas digitales de texto, o bien binarias. Entonces, para que las huellas digitales sean más sensibles, más útiles desde el punto de vista de la detección de información oficial y confidencial, deben determinar la máxima cantidad de datos diversos.
Las buenas huellas digitales, para ser eficaces, además de texto, información de flujo en forma de archivos de audio y vídeo, deben comprender también imágenes rasterizadas.
Teníamos un cliente al que le robaban fotografías de reportaje del lugar de los hechos.
Y su objetivo era localizar menciones de estas fotografías en el tráfico. Además, no importaba si la fotografía había sido modificada en resolución, es decir, era un formato RAF, y la convirtieron en JPEG, o RAF la convirtieron en PNG, modificaron la resolución y el número de puntos. Aun así, este sistema debía detectarlo. Tenemos una tecnología de huellas digitales, integrada en DLP, que permite localizar menciones precisamente de fotografías. Incluso si las fotografías se recortaron, giraron, modificaron ligeramente el formato.
También hay un módulo separado que permite hacer huellas digitales de imágenes vectoriales, de archivos CAD. Cuando, por ejemplo, introducimos en el sistema un boceto muy burdo de un tanque, y si alguien reenvía al menos una parte de este boceto, el sistema sigue entendiendo que es parte de un boceto confidencial. Allí el análisis se realiza mediante el análisis de primitivas gráficas: puntos, líneas, curvas y sus relaciones. Es decir, no es solo un corte por datos binarios, sino precisamente la comprensión de lo que se representa en la huella vectorial. ¿Y cómo hacer que las tecnologías de huellas digitales pasen del análisis de contenido al contextual? Naturalmente, las huellas digitales deben integrarse con los sistemas de documentos electrónicos, con todos aquellos almacenamientos donde se guardan los originales de los documentos que queremos proteger.
Y toda esta base de datos de huellas digitales debe mantenerse actualizada, es decir, debe haber una sincronización constante, una actualización de las huellas. En Traffic Monitor tenemos una API especial para esto, que permite mantener todas las huellas digitales al día e integrarse en el sistema de gestión documental.
Diccionarios lingüísticos
Ahora pasamos a otra tecnología clásica para el mercado DLP, se trata de diccionarios lingüísticos.
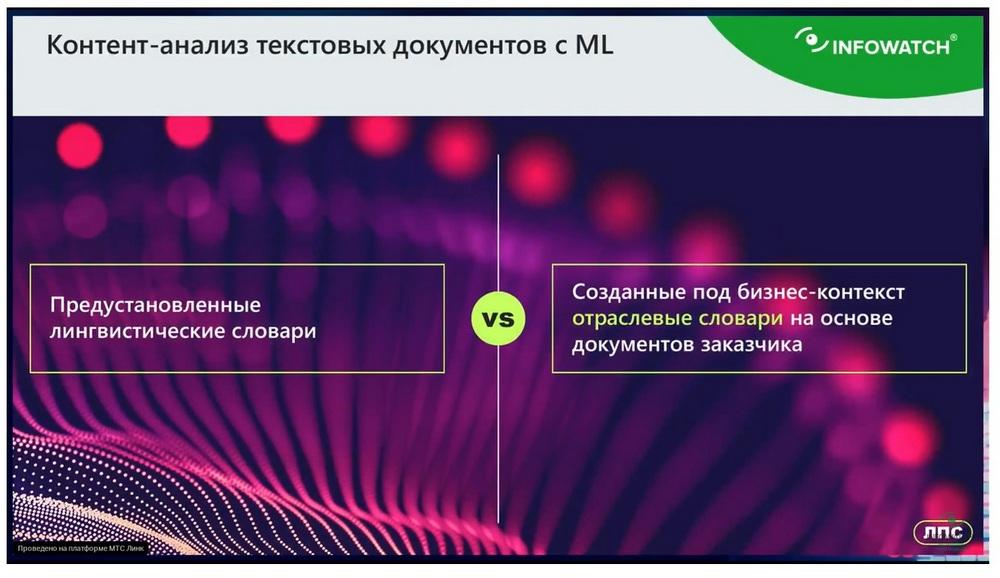
¿Cómo hacer que esta tecnología de diccionarios pase del análisis de contenido al contextual, para que tenga en cuenta todos los matices? Aquí nos ayuda el aprendizaje automático. Porque la creación de diccionarios es algo muy costoso. Para crear un diccionario eficaz, para que realmente detecte claramente una u otra categoría de información, se necesitan de 5 a 7 días laborables de un lingüista profesional. Debe crearse un modelo lingüístico completo, que puede contener un par de cientos de términos. Es difícil crear un diccionario así. El aprendizaje automático reduce el coste laboral. Hay ejemplos de documentos, se introdujo la información y en un minuto está listo un nuevo diccionario. Tan eficaz como si trabajara un lingüista profesional. El caso es que, al abaratar y acelerar la creación de diccionarios, cuando podemos generarlos por decenas, experimentar, crear uno hoy - no funcionó, al día siguiente creamos otro o lo reentrenamos, esto permite granular cada categoría de datos que tenga en su empresa, reflejarla en la política. Por ejemplo, si tomamos "de fábrica" algún diccionario relacionado con la logística. Y puede, por ejemplo, desactivarlo. Y crear, basándose en sus documentos concretos, un diccionario "logística de materiales consumibles" o "logística de entrega de mercancías". O crear un diccionario que refleje claramente las ofertas comerciales. Al abaratar la creación de diccionarios con la ayuda de la inteligencia artificial, con la ayuda del aprendizaje automático, podemos "generar" tantos diccionarios como queramos, reflejarán todos los matices de su gestión documental o proceso de negocio. Al abaratar la creación de diccionarios para el responsable de seguridad, es posible reconstruirlos constantemente. Podemos granular cada categoría de datos reflejándola en la política, repito, para cada tipo de contrato crear un diccionario aparte.
E incluso si aparecen nuevas categorías de datos que no se han tenido en cuenta, podemos reaccionar rápidamente ante ellas. Por lo tanto, el aprendizaje automático y la inteligencia artificial permiten reflejar más claramente el contexto empresarial en la política.
Ahora pasamos al aspecto más desagradable de la explotación del sistema DLP: los falsos negativos.

En realidad, este es un problema del que no se suele hablar en el mercado de DLP. Es un tema delicado, incluso tabú. ¿Y cuál es el problema? DLP pasa por alto algunos incidentes, no porque el responsable de seguridad sea negligente y no tenga en cuenta algo en las políticas. El problema del falso negativo es que el responsable de seguridad puede no saber que en su tráfico ha aparecido algún activo de información que no ha tenido en cuenta en las políticas.

En consecuencia, ni él lo sabe, ni el sistema DLP, al que no ha entrenado. Los incidentes omitidos, los falsos negativos, no son tanto un problema del propio sistema DLP, sino del hecho de que el responsable de seguridad está tan sobrecargado que no tiene tiempo para revisar todo manualmente, para analizar regularmente los eventos que el sistema DLP no ha marcado. Es simplemente un problema de recursos humanos y de enormes costes laborales. La única herramienta que permite luchar contra los falsos negativos es cuando abrimos el sistema DLP y, manualmente, con nuestros propios ojos, revisamos metódicamente los eventos que el sistema DLP no ha procesado, y buscamos una aguja en un pajar.
Tenemos un cliente que contaba que tiene una práctica estándar regular. Cuando un empleado presenta su dimisión, empiezan a revisar metódicamente todos sus eventos. Es decir, sobre todo los envíos por correo, a una memoria USB, etc. ¿Y qué dice este cliente? Que de vez en cuando descubren alguna categoría de datos, alguna estructura de documentos, algún nuevo formulario que no habían tenido en cuenta en las políticas, y el empleado ha filtrado varios documentos en una semana. Y empiezan a mejorar las políticas. Resulta que para luchar contra los falsos negativos en la realidad actual, DLP solo tiene una cosa: suerte. Que al revisar los eventos e incidentes "manualmente" tengamos la suerte de encontrar ese activo de información no contabilizado que podamos convertir en política. Si no tenemos suerte, estaremos en una dulce ignorancia y no sabremos que algo se está filtrando. ¿Qué podemos ofrecer en este contexto? Ya ni siquiera recuerdo si hace un año o año y medio, apareció nuestra tecnología de aprendizaje automático, que agrupa los datos desconocidos y no marcados del sistema DLP.

¿Qué significa agrupar? Toma toda la zona gris que el sistema DLP no ha marcado, divide los documentos en grupos y genera una anotación para cada documento, destacando los ejemplos más llamativos de documentos. Es decir, por ejemplo, en la fase de implantación del sistema DLP, el sistema ha funcionado y no hay ni un solo "disparo", ni una sola política.
Se inicia la herramienta, llamada Data Explorer, y ésta distribuye todos los documentos desconocidos en grupos, crea una anotación para ellos y destaca los ejemplos más llamativos. Y puedes ver y entender rápidamente qué categorías de documentos entran en tu tráfico.
¿Cómo funciona esta tecnología? Imagina que eres un responsable de seguridad. Tienes la tarea de analizar la zona gris, de analizar esta masa de documentos que el sistema DLP no ha procesado. Imagina que estás sentado a una mesa y te vierten miles, decenas de miles de documentos de una cesta. Y te dicen, averigua qué categorías de información hay aquí. De esto es de lo que se encarga el responsable de seguridad cuando intenta analizar la zona gris "manualmente". Los documentos no están marcados en DLP, y él empieza a hurgar caóticamente en esto. Con las manos y los ojos.
La tecnología de aprendizaje automático se comporta de forma diferente. Imagina que no tienes un montón de documentos delante, sino que te han puesto montones de documentos grapados, y te han dicho, aquí hay contratos, aquí hay albaranes, aquí hay documentos relacionados con los empleados. Y a cada montón de documentos le han pegado una nota amarilla donde se indican los términos clave que hay en ese montón, e incluso han puesto encima de ese montón los documentos más llamativos y diversos que reflejan ese montón.
La tecnología de aprendizaje automático permite descomponer cualquier dato desconocido, tanto para la persona como para el sistema DLP, en montones y generar una anotación para ellos. También puedes coger este montón y alimentar con él otra tecnología de aprendizaje automático que te generará un nuevo diccionario en un minuto.
En este caso, no es que pasemos del contenido al contexto, sino que podemos entender este contexto.

Un cliente se enfrentó al problema de que un determinado grupo de empleados sacaba documentos masivos fuera del perímetro de la empresa. Se trataba de un total de 4.000 documentos. DLP no procesó estos documentos de ninguna manera. Es decir, no los consideró confidenciales. Empezaron a estudiar estos documentos con atención. Resulta que alguna categoría de información, ya sea confidencial o no, no está claro. Según el propio cliente, se necesitarían 30 horas para que dos responsables de seguridad analizaran estos documentos. Pero utilizó una tecnología de aprendizaje automático que analizó 4.000 documentos en una hora y media. Al final, se descubrió que se trataba de un determinado documento para la preparación de fusiones, para algunas operaciones VIP, etc., pero que no se reflejaba en las políticas de ninguna manera. Y posteriormente reflejaron estos activos de información en la política. En primer lugar, se dieron cuenta de que no se trataba de una infracción, sino de preparativos para una operación. Y en segundo lugar, pudieron obtener este activo de información a bajo coste investigando solo una hora y media en lugar de 30 horas. Y luego, con la ayuda del aprendizaje automático, crear diccionarios y reflejarlos en la política. El cliente habla de los costes laborales, de cuánto gastó, cuánto puede gastar, cuánto no puede gastar en el servicio de la operación, cómo justificar ante la dirección tales manipulaciones para analizar los eventos grises.
Y el segundo caso es una organización financiera que utilizó una tecnología que se opone a las expresiones regulares. Esta es una tecnología que, a diferencia de las expresiones regulares, permite entender no solo el contenido, sino también el contexto de los datos. La empresa tiene 3.000 empleados, lleva 20 años en el mercado y tiene 100.000 clientes. Y el cliente tenía la tarea de entender que los datos del cliente, extractos, ofertas comerciales, tal vez, tales correspondencias, se envían a un cliente específico. Es decir, si yo, por ejemplo, envío una oferta comercial a un socio o cliente, pero por error indiqué una dirección incorrecta, esto debe considerarse una infracción. En esencia, el cliente implementó una política automática con esta tecnología que contiene cientos de miles de reglas. Aquí es donde la comprensión del contexto de los datos se revela al máximo. En primer lugar, determinamos la pertenencia de los datos de un cliente específico y determinamos automáticamente que los datos se envían precisamente a este cliente. Además, esta tecnología se implementa en el trabajo "en la brecha". Es decir, si una carta no se envía al cliente correcto, o por error, o si se indican algunos datos personales incorrectos, el envío se bloqueará.
Esto se ha logrado gracias a una tecnología patentada, algoritmos de indexación y búsqueda. La tecnología es muy productiva. Daré un pequeño ejemplo. La huella de una base de clientes de 10 millones, su entrada en cualquier mensaje, cualquier mención de cualquier cliente se verifica en una décima de segundo.
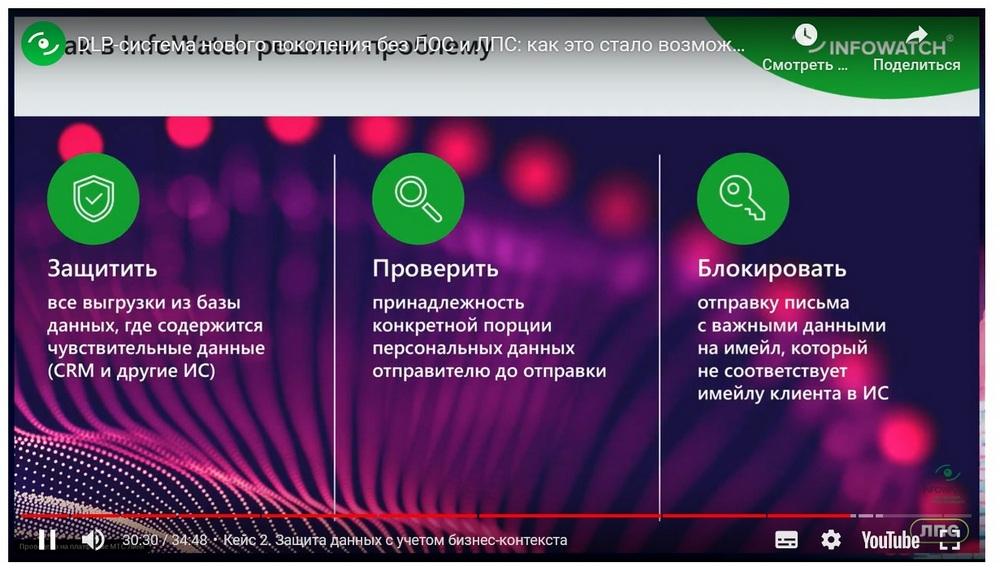
Pudimos integrar el sistema DLP Traffic Monitor con el sistema de negocio del cliente, desde donde tomamos los datos de los clientes, determinamos la pertenencia de estos datos y, bueno, bloqueamos si una porción de datos se envía al socio incorrecto.
Por esta tecnología recibimos el premio bancario nacional en la nominación "El mejor sistema de protección de datos personales para el sector bancario".

