Сегодня компании OCS и VK Tech проводят встречу, которая будет посвящена Cloud Storage – российскому объектному хранилищу корпоративного уровня с протоколом доступа API S3. Cloud Storage позволяет организовать высокопроизводительное, надёжное и масштабируемое хранение файлов любого типа и размера: бэкапы, документы, мультимедийный контент и т.д.

Сегодня будет разговор о следующем:
- Проблемы классических систем хранения большого объёма данных,
- Как организовать хранение данных в компаниях с повышенными требованиями к контуру внутренней безопасности;
- Как легко осуществить миграцию на отечественное решение;
- Преимущества объектного хранилища Cloud Storage от VK.
В программе мероприятия:
- Потребность клиента;
- Презентация продукта Cloud Storage от VK;
- Партнёрская программа продукта;
- Реализованные кейсы.
Спикеры: Ханецкий Дмитрий, руководитель группы продаж Cloud Storage и Сорокин Георгий, архитектор Cloud Storage.

Портрет нашего клиента – это enterprise сегмент, т.е. крупный бизнес, это абсолютно любая индустрия, все те компании, у которых стоит задача хранить неструктурированный контент, под которым понимается разный формат данных: файлы, видео, сканы, аудио и т.д. Второй момент – это требования к SLA. Здесь должна быть высокая доступность, высокий SLA, как правило это госсегмент или банковский сектор, где присутствуют требования к критически важной инфраструктуре. Наше решение заточено под высококритичные SLA по доступности и безопасности хранения.
Что касается контура безопасности хранения – обеспечивается хранение более чем в одном дата-центре (в двух или трех), у компании VK их четыре. У нас повышенное внимание к требованиям регуляторов, это то что касается директивы №12-36, перехода на импортозамещение и определенные требования к принадлежности ПО к классу «российское».

Какие потребности встречаются у наших клиентов? Это долгосрочное хранение файлов различного типа, минимальный объем хранения составляет 50 Тбайт. Это полезные данные, а не сырая емкость хранения, ниже этого порога наши решения становятся не так интересны с точки зрения ценообразования и функционально они избыточны.
Еще один момент – постоянный интенсивный доступ на чтение и запись объектов. Если эти три критерия выполняются, то вы на правильном пути в плане нашего портфолио.

Что обычно хранят клиенты? В первую очередь бэкапы, архивы как горячие, так и холодные с различными типами данных, это документооборот, но есть кейсы с Big Data, машинным обучением и мультимедийный контент.

Какие моменты стоит уточнить у заказчика, когда вы начинаете беседу о продаже продуктов VK? В первую очередь это готовность использовать стандартный протокол S3. Это международный стандарт, который был создан компанией Amazon в 2006 году. Мы этого стандарта строго придерживаемся, двигаемся в рамках стандартных правил протокола S3. Есть масса кейсов, когда наши заказчики в курсе, и применяют S3 как стандартное направление протокола для хранения, но бывают кейсы, когда не применяют. Поэтому об этом стоит спрашивать и учитывать их пожелания на ранней фазе создания проекта.
Второй момент - это готовность разворачивать решение во внутреннем контуре, а не в облаке. В данном случае мы говорим о “on-premise” решении. Эта инсталляция в контуре заказчика, она полностью интернет-независима с точки зрения внешнего доступа. У нас никакие ключи не хранятся вовне в случае такой инсталляции, у нас нет ограничений с точки зрения доступа. Т.е. это полноценно изолированное решение, которое может быть растянуто на один, два и более ЦОДов у заказчика.
Третий момент - это возможность размещения аппаратных мощностей data -центра, потому что мы часто сталкиваемся с ситуацией, когда заказчик не обладает либо достаточной ёмкостью в data-центре, либо какими-то внутренними мощностями и ресурсами для размещения оборудования у себя. Если на все эти три вопроса ответы положительные, то мы двигаемся дальше.
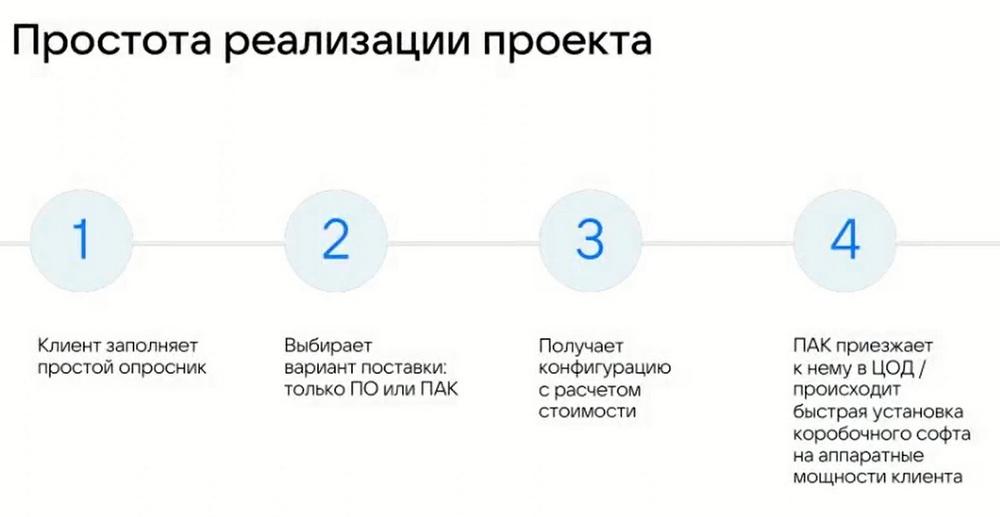
Хочу обратить ваше внимание на простоте реализации нашего кейса. У нас есть стандартная форма в виде опросного листа. Он включает в себя около 15 вопросов. Базовый профайл, который мы составляем на основании этих ответов, он дает картину по профилю нагрузки, по объему для расчета спецификации стоимости проекта.
Первый момент - это выбор формата поставки. В нашем случае имеется несколько вариантов, доступных на рынке. Это просто ПО, передаем его вам для продажи заказчику. Далее вы можете самостоятельно дополнить это решение оборудованием, конфигурацией железа, аппаратной платформой (мы также прикладываем к конфигурации).
Второй момент - это продажа программно-аппаратного комплекса (ПАК). Мы, как вендор, также предлагаем ПАК, который сами собираем у себя на базе, тестируем, преднастраиваем и передаем заказчику как готовый аппаратный продукт. В него входят и сопровождение, и аппаратная часть, и программная часть. Это полноценное готовое вендорское решение, какие мы привыкли видеть на рынке.
Есть и третий вариант реализации. Он как раз является тем самым исключительным случаем для конфигурации меньше 50 Тбайт. Это продажа в рамках публичного облака VK.
Четвертый шаг, который мы проходим, перед продажей, перед закрытием проекта, мы получаем ту самую конфигурацию, которую необходимо получить, либо в варианте ПАКа, либо в программном варианте. Продаем ее вам с необходимыми ценами и документацией для продажи и передачи заказчику. В конечном итоге мы просто, если это ПАК, привозим его прямо в ЦОД, производим настройку своими силами, а, если вы хотите сами поучаствовать в этом процессе, можем передать бразды управления вам, но, как правило, первичные внедрения мы стараемся делать самостоятельно для того, чтобы избежать рисков некачественной сборки платформы. Либо, мы можем аудировать вашу работу, если вы получите достаточные компетенции, будете готовы обучаться в этом направлении, мы такие услуги тоже оказываем и готовы развивать своих партнеров. При определенных условиях мы можем передавать внедрение вам. У нас уже есть несколько партнеров, которые обладают необходимыми компетенциями и сертификатами по внедрению наших решений и успешно это производят на рынке уже не первый раз.
Это основные четыре шага, которые мы определяем для успешной продажи. Хочу еще раз сделать акцент на том факте, что мы стараемся максимально упростить процесс продажи и конфигурацию решения. Это базовый подход. Мы никаких усложнений и дополнений вносить сюда не хотим, стараемся облегчить работу своим партнерам для более продуктивной работы с заказчиками. Чтобы это занимало не недели, а день-два.

Есть небольшой сегмент, который мы хотели бы осветить в части классических СХД. Более года мы находимся в ситуации, когда на рынке появились проблемы, связанные со сложностями поставки зарубежной классики и переходом на что-то русское, но в блочном формате. Есть вендоры, которые производят эти СХД, но есть клиенты, которые переходят с западных решений на локальные альтернативные технологии.
Как правило, вся эта конструкция в идеале находится на поддержке вендоров, и любые манипуляции это прежде всего потраченное время и плюс затраты. С точки зрения растянутости хранилища на более, чем один ЦОД, здесь тоже есть определенные нюансы, которые касаются реализации архитектурной растянутости хранилища, и, как вы понимаете, эти ограничения никуда не уходят. Также для блочных СХД нужно создавать дополнительный контур доступа для структурированного контента. Все эти челенджи это все те базовые вещи, с которыми заказчики сталкиваются до перехода на альтернативную технологию S3.

Теперь расскажу о том, как мы с этими челенджами боремся, какие мы имеем преимущества для наших клиентов перед коллегами в части подхода и технологий. Первое, что хочется отметить, это неограниченное масштабирование. Это архитектура x86, обычные серверы, и мы горизонтально не имеем планки, по крайней мере, мы до нее еще не дошли в архитектурном решении. У нас есть инсталляции более 350 Пбайт данных. Таких инсталляций нет ни у кого в России, кроме как в VK в наших ЦОД. Т. о. мы утверждаем, что у нас нет ограничений по масштабированию. Все это происходит в рамках единой большой инсталляции, и мы добиваемся масштабирования путем доставления определенных серверов либо дисковых полок просто в систему, без остановки процесса. Т.е. заказчик, или вы, если вы будете его обслуживать, можете привести в data-центр заказчика дополнительное оборудование и в режиме on-line просто его законнектить в уже готовую архитектуру. Все это делается оперативно и, самое главное, доступно. Сервера x86 доступны на рынке. И еще хочу отметить, что мы не привязываемся к производителям этих серверов. Если вы поставляете ПО, и мы с вами продаем его заказчику, то серверы имеют только определенные конфигурационные требования, которые мы должны учитывать. С точки зрения производителя вендора этого железа, его наличия и других факторов, ограничений нет.
Второй момент - это снижение TCO. Мы можем поставлять решение как в виде ПО, что на рынке практически никто не делает, в основном - это ПАКи, т.е. это привязка к железу, собственному оборудованию и вендору. Либо это могут быть ПАКи от нас, если заказчик хочет все из одного окна, полную поддержку с горячей заменой. В случае поставки ПАК, заказчик получает полностью комплексное решение. Т.о. мы снижаем TCO относительно блочных историй за счет того, что архитектурно мы дешевле. Сам софт и компоненты с архитектурой x86 ниже по стоимости, чем блочные. Так что мы вольны делать все, что угодно, и у вас тоже развязаны руки в плане конфигурировании решений. Т.е. как один из вариантов бизнеса, мы будем поддерживать, если вы, как партнеры, будете предлагать на вашей стороне конфигурировать определенные ПАКи для заказчиков.
Гибкость конфигурации хранилища - это еще один момент, который у нас присутствует. Мы можем, в зависимости от той задачи, которую заказчик решает, например, есть большие блоки данных, которые надо записывать, но при этом акцент на хранение там не делается, а акцент поставлен на ввод-вывод горячих данных. Это один вариант конфигурации. Второй вариант - это холодное хранение данных, когда, допустим, у заказчика имеется множество различного рода объектов, малых, средних и больших, которые хранятся на долгосрочной основе по определенным критериям. В этом случае мы можем реконфигурировать наше решение и добавлять ноды определенного формата производительности на хранение и т.д. Наше решение максимально гибко конфигурируется с точки зрения компонентов дисков, объема дисков, мощности процессоров и т.д. Мы не ограничены в плане вариантов параметров аппаратной конфигурации. Это тоже очень важно для заказчика.
Мы обеспечиваем многоцодовую конфигурацию, причем это не изолированные конфигурации, это одна большая растянутая конфигурация на много ЦОДов. Т.е. это система, которая полноценно закрывает решение с кластером, с мультицодовым хранением. И у нас есть примеры нескольких площадок. У нас в VK есть 4 площадки в которых мы храним наши данные. И это все одна большая инсталляция.
И последний момент, тоже важный. Это наша собственная разработка с самого нулевого цикла.
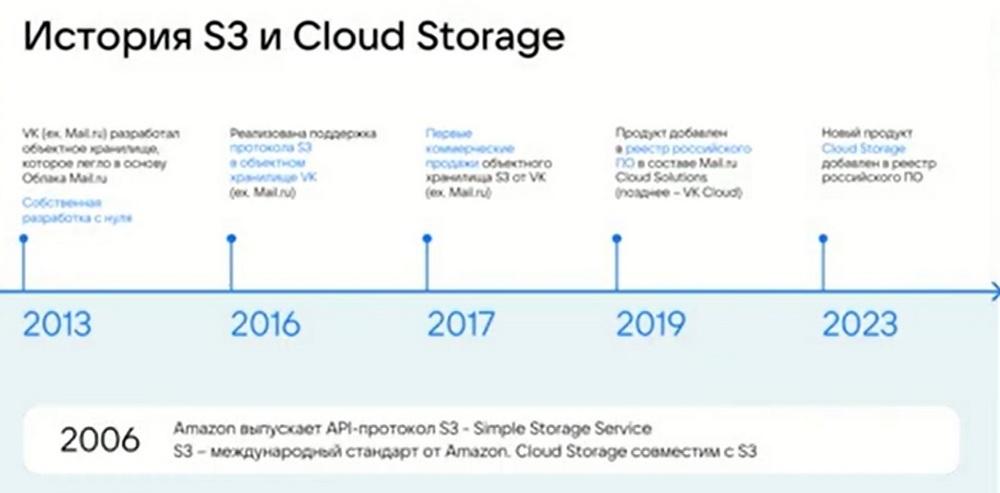
Немного истории. В 2006 году начался отчет по протоколу и технологии S3. Его придумал и выпустил Amazon для своих data-центров и облачных хранилищ. VK включилась в эту гонку в 2013 году, еще в составе Mail. И мы разработали первое объектное хранилище для собственного облака. Мы хранили контент для почтового агента. Нашу почту, наш облачный Mail.ru использовал полностью наше решение VK Cloud. В 2016 году реализована поддержка протокола S3 в полном объеме в объектном хранилище VK. В 2017 году мы начали первые коммерческие продажи объектного хранилища уже в формате отдельного продукта в составе платформ. В 2019 году мы добавили продукт в Реестр российского ПО в составе Mail.ru Cloud Solutions. И в 2023 году мы вывели данный продукт в отдельную боевую единицу. Это абсолютно независимое решение по хранению данных. Также мы дали ему новое реестровое имя и новую реестровую запись. Сейчас это совершенно самостоятельный проект с длинной, почти 10-летней историей развития. Мы за это время исправили кучу ошибок, как и все разработчики, которые проходят этот путь. И можно смело говорить, что мы максимально консистентны и отработаны с точки зрения функционала. Об этом говорят наши клиенты. Мы включены в Реестр, есть реестровая запись, вы можете ее найти на сайте соответствующего Госоргана. Это все в открытом доступе, и мы готовы делиться с вами этой информацией при необходимости.

Наше решение мощное и производительное. Аналогов по объему хранения данных в единой инсталляции на рынке нет. Мы на сегодняшний день храним более 350 Пбайт данных в наших 4-х ЦОДах. И ежедневно испытываем на себе работу данного решения. У нас были кейсы, когда ЦОДы отключались, были пожары в ЦОДах в России. Один из ЦОДов был арендован нами в тот самый момент. И наше решение абсолютно бесшовно переключалось и продолжало работу даже в случае аварийной ситуации. У нас хранится в горячем доступе более 30 млрд объектов. И 90 млрд объектов находятся в холодном общем доступе. Это вовсе не означает, что должны продавать именно такие же большие инсталляции. Это говорит лишь о том, что наше решение максимально проработано и способно к идеальным условиям эксплуатации с точки зрения как рисков потери данных, так и работоспособности по масштабированию системы.

Теперь поговорим о вариантах поставки. Первый вариант - это ПО. В этом случае мы продаем бессрочные лицензии, непередаваемые, т.е. они у нас не ограничены по сроку действия, это не подписка, это полноценная лицензия, которая приобретается один раз и предается на баланс заказчика и полностью находится в его владении без ограничения по времени. Лицензируемся мы по полезным терабайтным данным. Т.е., грубо говоря, заказчику нужно хранить 100 Тбайт данных, мы предлагаем лицензию на ПО на 100 Тбайт независимо от того, какая платформенная конфигурация с каким фактором репликации присутствует и т.д. Поддержка у нас как у большинства вендоров. Продается на определенные периоды: год, два, три и пять лет. Максимальный срок пять лет. Мы можем продавать поддержку вам как сертификат, так и как услугу. В зависимости от того, какой бюджет у заказчика, и от того, на основании какой статьи расходов он готов это покупать.
ПАК мы продаем в разных вариациях. Есть ситуации, когда заказчику безразлично, какой тип оборудования стоит в рамках этого ПАКа. Оборудование может быть как реестровое, так и не реестровое. По умолчанию мы не предлагаем реестровое железо для того, чтобы удешевить конфигурацию и обеспечить более конкурентную цену на рынке для нашего ПАКа. Но, если заказчик говорит о том, что у них есть определенные требования регулятора, либо внутреннее распоряжение о соблюдении требований регулятора о наличии реестровых компонентов аппаратного комплекса, то мы можем поставить и реестровые компоненты в наш ПАК. Т.е. возможны любые варианты. Мы сотрудничаем со всеми основными вендорами на российском рынке, и можем поставлять самые разные конфигурации на базе нашего ПАК. При этом, если ПАК поставляется от нас, независимо от того, какие компоненты находятся в его составе, мы оказываем централизованную поддержку для вас и для наших заказчиков как по аппаратной части, так и программной части. И как в случае с ПО, так и в случае с ПАК, мы оказываем услуги по пуску-наладке и по внедрению ПО, пуску-наладке ПАК и сопровождению. Еще мы можем предложить услуги по обучению персонала. Мы можем обучить как вас, так и сотрудников заказчика работе с нашей системой.
Третий вариант реализации - это публичное облако для кейсов, когда мы понимаем, что заказчику очень надо, но у него нет готовности поставить комплекс в свой ЦОД, нет требований к собственному изолированному контуру и объем хранения ниже 50 Тбайт. В этом случае мы можем предложить Public Cloud. И вы тоже можете его перепродать на ваших бумагах для заказчика и заработать на этом деньги.
Затем слово взял Георгий Сорокин, архитектор Cloud Storage. Он начал рассказ о том, как Cloud Storage устроен. Он условно разделен на три функциональные уровня, каждый из которых отвечает за свою функцию. Это уровень Фронт серверов, уровень Метаданных и уровень Storage серверов. На больших решениях мы эти уровни разделяем, в том числе и физически. Каждый из этих уровней состоит из абсолютно отдельных серверов.
Фронт Серверы - это серверы, которые обрабатывают все поступающие запросы, обрабатывают нагрузку, считают хэши и раскидывают поступающую информацию на Storage серверы. Это те серверы, на которых хранятся сами объекты.
Уровень Метасерверов - это уровень, на котором хранится метаинформация обо всех объектах. Она записывается и масштабируется отдельно. Этот уровень работает на платформе in-memory Tarantool. Именно благодаря ему у нас 350 Пбайт данных, которые мы можем масштабировать. Потому что даже на этих больших объемах у нас нисколько не падает время отклика.
По поводу масштабирования. Мы можем по-разному масштабироваться. Если, допустим, изначально был некий объем, например, 5000 IOPS. Нагрузка была на систему. И вдруг у заказчика возникает необходимость в увеличении этой нагрузки. Становится больше клиентов или система стала более нагруженной. Мы просто можем увеличить количество Фронт серверов, которые отвечают за обработку входящих запросов. А если у нас увеличивается объем данных, то мы обычно просто добавляем Storage серверы. Обычно вместе со Storage серверами, которые отвечают за сохранение объектов, если они увеличиваются, вполне логично, что у нас происходит и увеличение количества объектов, за что у нас отвечают Метасерверы. Мы соответственно добавляем Метасерверы. Каждый из этих слоев можно масштабировать отдельно, что очень важно. Там не нужно, как в случае, если эти функции были на одном сервере, добавлять сразу все слои. Мы выбираем тот параметр, который нам необходимо активизировать, и добавляем серверы в соответствии с этой необходимостью.
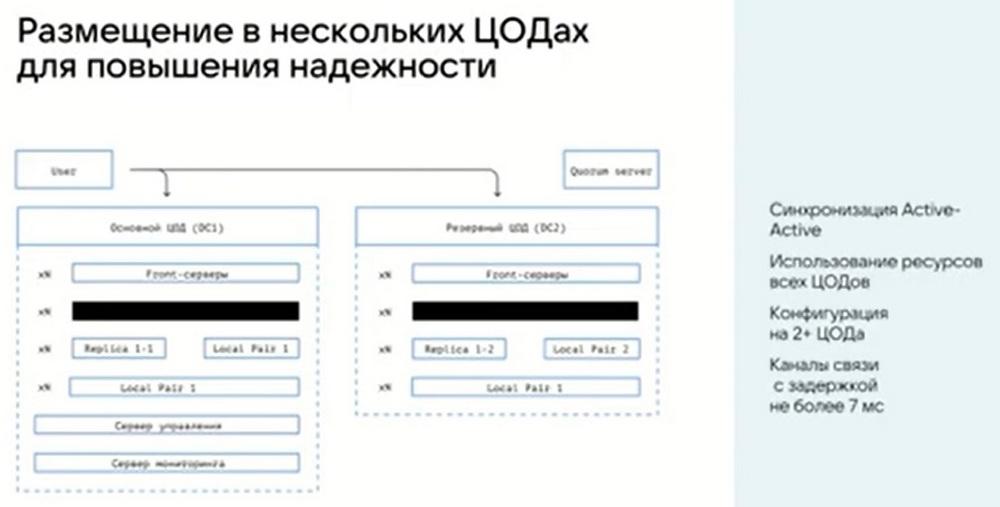
Теперь по поводу нескольких ЦОД. Здесь у нас решение работает в распределенном режиме. Это значит, что мы не делаем один ЦОД активным, а второй пассивным и не настраиваем между ними репликацию. У нас решение работает распределенно между несколькими ЦОДами. Два, три, четыре и больше, это не важно. И работа ведется сразу со всеми серверами, со всеми объектами, которые расположены в этих ЦОДах.
По поводу уровня репликации. У нас есть Storage серверы. Они обычно добавляются парами. Это обусловлено тем, что по умолчанию коэффициент репликаций равен 2. У нас каждый объект храниться в двух копиях, причем каждая из этих двух копий абсолютно всегда хранится на отдельном сервере и на отдельном диске. Это все у нас вшито архитектурой системы и по-другому располагаться объекты не могут. Ситуации, когда у нас обе копии одного объекта будут находиться или на одном сервере, или на одном диске исключена. Если говорить о многоцодовой конфигурации, то они всегда автоматически будут находиться в разных ЦОДах.
Про Метаинформацию. Благодаря Tarantool мы можем настраивать фактор репликации, т.е. количество копий, которые у нас хранится метаинформация. По умолчанию мы используем 3 копии. Для нескольких (двух, четырех) ЦОДов мы этот фактор увеличиваем до 4. Чтобы можно было симметрично расположить ЦОДы. Благодаря Tarantool у нас есть шердирование, когда мы одну большую базу данных разбиваем на несколько и располагаем на отдельных машинах, как раз из-за этого у нас есть возможность наращивать огромный объем информации и огромное количество объектов без деградации производительности. Поскольку все данные о них хранятся на отдельных машинах в отдельной памяти и этим занимается отдельный экземпляр Tarantool.
По поводу репликаций и задержек, стандартная задержка между ЦОДами у нас рекомендуется не более 7 миллисекунд. Но это не означает, что мы не поддерживаем большую задержку. Мы можем спокойно работать и на 20-ти, и на 30-ти миллисекундах. Но нужно понимать, что у нас система распределенная, запись идет синхронная, и для того, чтобы объект считался записанным, мы должны получить подтверждение с каждого ЦОДа.
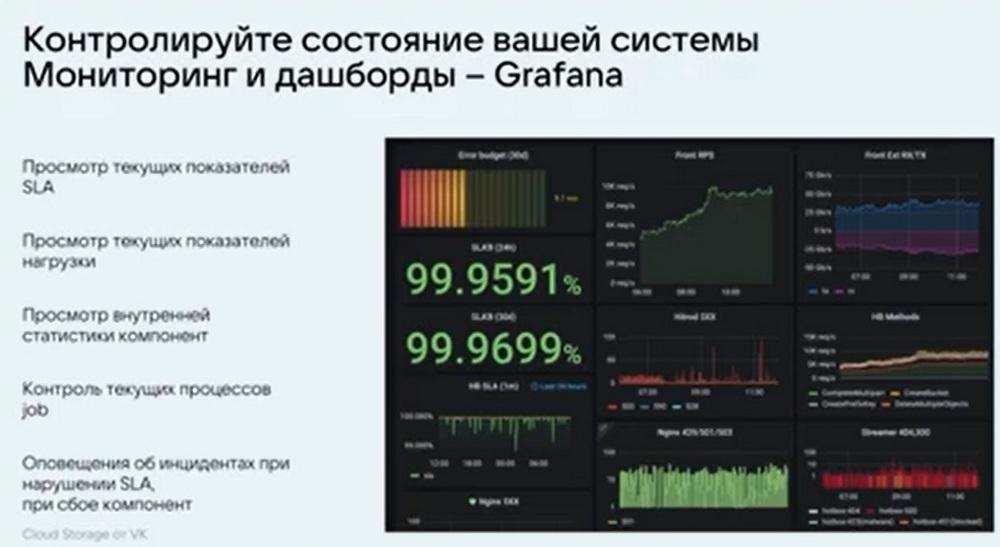
У нас есть своя система мониторинга, есть дашборды. Все работает на Grafana. Мы показываем всю основную информацию о работе системы, это и нагрузку, и РПС, и работа отдельных сервисов, пропускная способность, и это только маленькая часть дашбордов. Их на самом деле раз в 10 больше. И можно углубляться до самых мелочей, смотреть что и как работает, предупреждать ошибки и обрабатывать их заранее, не доводя их до критических событий.
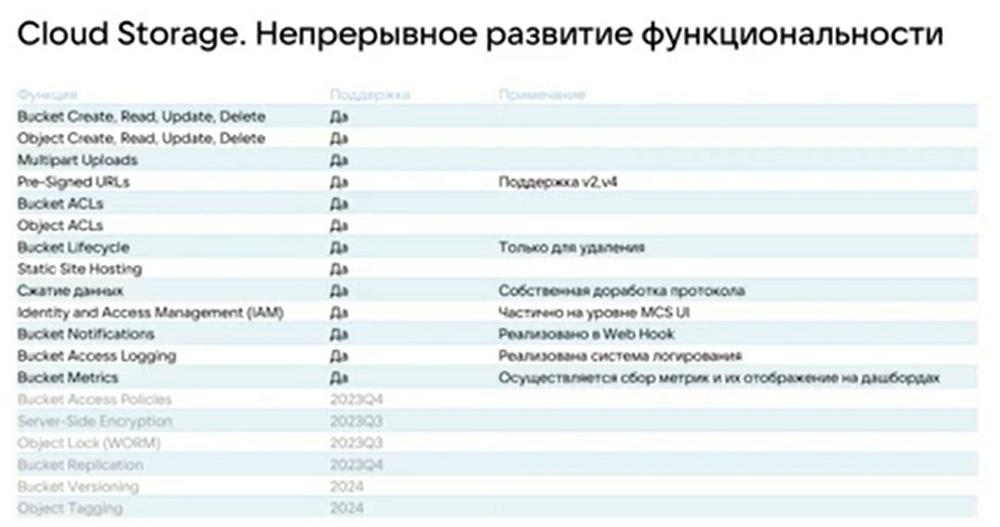
По функциональности мы держим стандартный протокол S5, разработанный Amazon. И основные функции, которые мы поддерживаем, в принципе, это все функции. Часть из них находится еще в разработке, те, которые менее критичны. На экране можете посмотреть то, что у нас поддерживается и небольшой клок по ближайшим кварталам, что у нас уже находится даже в тестировании.