Hoy, las compañías OCS y VK Tech celebran una reunión dedicada a Cloud Storage, un almacenamiento de objetos ruso de nivel corporativo con protocolo de acceso API S3. Cloud Storage permite organizar un almacenamiento de archivos de alto rendimiento, fiable y escalable de cualquier tipo y tamaño: copias de seguridad, documentos, contenido multimedia, etc.

Hoy se hablará de lo siguiente:
- Problemas de los sistemas clásicos de almacenamiento de grandes volúmenes de datos.
- Cómo organizar el almacenamiento de datos en empresas con altos requisitos de seguridad interna.
- Cómo realizar fácilmente la migración a una solución nacional.
- Ventajas del almacenamiento de objetos Cloud Storage de VK.
En el programa del evento:
- Necesidades del cliente.
- Presentación del producto Cloud Storage de VK.
- Programa de socios del producto.
- Casos realizados.
Ponentes: Janetsky Dmitry, jefe del grupo de ventas de Cloud Storage, y Sorokin Georgy, arquitecto de Cloud Storage.

El perfil de nuestro cliente es el segmento empresarial, es decir, grandes empresas, absolutamente cualquier industria, todas aquellas compañías que tienen la tarea de almacenar contenido no estructurado, que se entiende como diferentes formatos de datos: archivos, vídeos, escaneos, audio, etc. El segundo punto son los requisitos de SLA. Aquí debe haber alta disponibilidad, alto SLA, generalmente es el sector público o el sector bancario, donde existen requisitos para la infraestructura crítica. Nuestra solución está diseñada para SLA de alta criticidad en cuanto a disponibilidad y seguridad del almacenamiento.
En cuanto al perímetro de seguridad del almacenamiento, se garantiza el almacenamiento en más de un centro de datos (en dos o tres), la compañía VK tiene cuatro. Prestamos mayor atención a los requisitos de los reguladores, esto es lo que se refiere a la directiva №12-36, la transición a la sustitución de importaciones y ciertos requisitos para que el software pertenezca a la clase "ruso".

¿Qué necesidades tienen nuestros clientes? Es el almacenamiento a largo plazo de archivos de varios tipos, el volumen mínimo de almacenamiento es de 50 TB. Son datos útiles, no capacidad de almacenamiento bruta, por debajo de este umbral nuestras soluciones no son tan interesantes desde el punto de vista de los precios y funcionalmente son redundantes.
Otro punto es el acceso constante e intensivo para leer y escribir objetos. Si se cumplen estos tres criterios, entonces está en el camino correcto en términos de nuestra cartera.

¿Qué suelen almacenar los clientes? En primer lugar, copias de seguridad, archivos tanto calientes como fríos con diferentes tipos de datos, esto es gestión de documentos, pero hay casos con Big Data, aprendizaje automático y contenido multimedia.

¿Qué puntos debe aclarar con el cliente cuando comience a hablar sobre la venta de productos VK? En primer lugar, es la disposición a utilizar el protocolo estándar S3. Este es un estándar internacional que fue creado por la compañía Amazon en 2006. Cumplimos estrictamente con este estándar, nos movemos dentro de las reglas estándar del protocolo S3. Hay muchos casos en los que nuestros clientes están al tanto y utilizan S3 como una dirección de protocolo estándar para el almacenamiento, pero hay casos en los que no lo utilizan. Por lo tanto, vale la pena preguntar sobre esto y tener en cuenta sus deseos en la fase inicial de la creación del proyecto.
El segundo punto es la disposición a implementar la solución en el circuito interno, no en la nube. En este caso, estamos hablando de una solución "on-premise". Esta instalación está en el circuito del cliente, es completamente independiente de Internet desde el punto de vista del acceso externo. No almacenamos ninguna clave externamente en caso de tal instalación, no tenemos restricciones en términos de acceso. Es decir, es una solución completamente aislada que se puede extender a uno, dos o más centros de datos en el cliente.
El tercer punto es la posibilidad de colocar las capacidades de hardware del centro de datos, porque a menudo nos encontramos con la situación en la que el cliente no tiene suficiente capacidad en el centro de datos, o algunas capacidades y recursos internos para colocar el equipo en sus instalaciones. Si las respuestas a estas tres preguntas son positivas, entonces seguimos adelante.
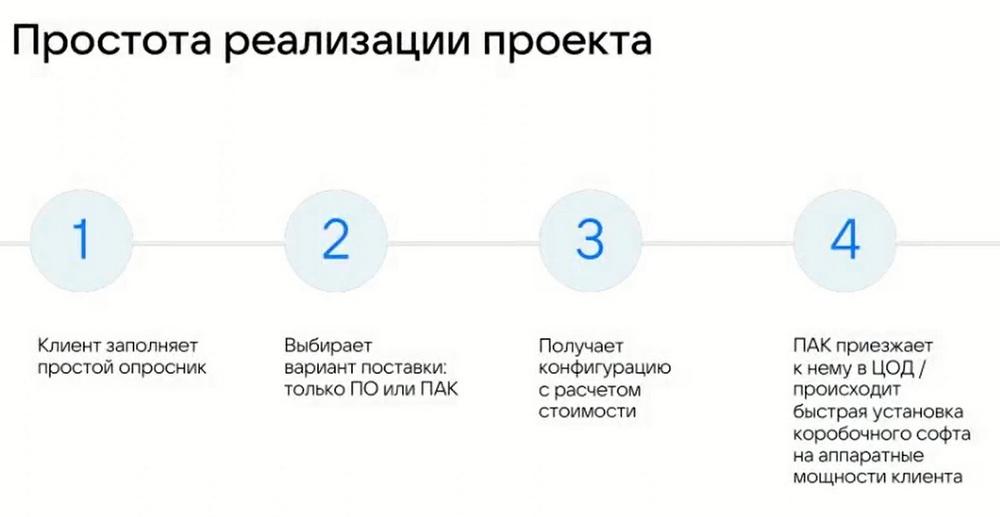
Quiero llamar su atención sobre la simplicidad de la implementación de nuestro caso. Tenemos un formulario estándar en forma de cuestionario. Incluye alrededor de 15 preguntas. El perfil básico que elaboramos en base a estas respuestas, da una imagen del perfil de carga, del volumen para calcular la especificación del costo del proyecto.
El primer punto es la elección del formato de entrega. En nuestro caso, hay varias opciones disponibles en el mercado. Esto es simplemente software, se lo transferimos para que lo venda al cliente. Luego, puede complementar esta solución usted mismo con equipos, configuración de hardware, plataforma de hardware (también adjuntamos a la configuración).
El segundo punto es la venta de un complejo de hardware y software (PAK). Nosotros, como proveedor, también ofrecemos PAK, que nosotros mismos ensamblamos en nuestra base, probamos, preconfiguramos y transferimos al cliente como un producto de hardware listo para usar. Incluye tanto el soporte, como la parte de hardware y la parte de software. Esta es una solución de proveedor completa y lista para usar, como estamos acostumbrados a ver en el mercado.
También hay una tercera opción de implementación. Es precisamente ese caso excepcional para una configuración de menos de 50 TB. Esta es la venta dentro de la nube pública de VK.
El cuarto paso que damos, antes de la venta, antes de cerrar el proyecto, obtenemos esa configuración que es necesario obtener, ya sea en la variante PAK, o en la variante de software. Se la vendemos con los precios y la documentación necesarios para la venta y la transferencia al cliente. En última instancia, simplemente, si es un PAK, lo traemos directamente al centro de datos, realizamos la configuración por nuestra cuenta, y, si desea participar usted mismo en este proceso, podemos transferirle las riendas de la gestión, pero, por regla general, tratamos de realizar las implementaciones iniciales nosotros mismos para evitar los riesgos de un ensamblaje de plataforma de baja calidad. O bien, podemos auditar su trabajo, si obtiene las competencias suficientes, está dispuesto a capacitarse en esta dirección, también brindamos tales servicios y estamos listos para desarrollar a nuestros socios. Bajo ciertas condiciones, podemos transferirle la implementación. Ya tenemos varios socios que tienen las competencias y los certificados necesarios para implementar nuestras soluciones y lo hacen con éxito en el mercado no por primera vez.
Estos son los cuatro pasos principales que definimos para una venta exitosa. Quiero enfatizar una vez más el hecho de que tratamos de simplificar al máximo el proceso de venta y la configuración de la solución. Este es el enfoque básico. No queremos introducir ninguna complicación ni adición aquí, tratamos de facilitar el trabajo de nuestros socios para un trabajo más productivo con los clientes. Para que esto no lleve semanas, sino uno o dos días.

Hay un pequeño segmento que nos gustaría destacar en la parte de los SJD clásicos. Durante más de un año nos encontramos en una situación en la que han surgido problemas en el mercado, relacionados con las dificultades de suministro de los clásicos extranjeros y la transición a algo ruso, pero en formato de bloques. Hay proveedores que producen estos SJD, pero hay clientes que están pasando de soluciones occidentales a tecnologías alternativas locales.
Por regla general, toda esta construcción idealmente está en el soporte de los proveedores, y cualquier manipulación es ante todo tiempo perdido y más costos. Desde el punto de vista de la extensión del almacenamiento a más de un centro de datos, también hay ciertos matices que se refieren a la implementación de la extensión arquitectónica del almacenamiento, y, como comprenderá, estas restricciones no desaparecen. También para los SJD de bloques es necesario crear un circuito de acceso adicional para el contenido estructurado. Todos estos desafíos son todas aquellas cosas básicas con las que los clientes se encuentran antes de la transición a la tecnología alternativa S3.

Ahora les contaré cómo luchamos contra estos desafíos, qué ventajas tenemos para nuestros clientes frente a nuestros colegas en términos de enfoque y tecnologías. Lo primero que me gustaría destacar es la escalabilidad ilimitada. Esta es la arquitectura x86, servidores comunes, y horizontalmente no tenemos una barra, al menos, aún no hemos llegado a ella en la solución arquitectónica. Tenemos instalaciones de más de 350 PB de datos. Nadie en Rusia tiene tales instalaciones, excepto en VK en nuestros centros de datos. Por lo tanto, afirmamos que no tenemos restricciones de escalabilidad. Todo esto ocurre dentro de una gran instalación única, y logramos la escalabilidad entregando ciertos servidores o estantes de discos simplemente al sistema, sin detener el proceso. Es decir, el cliente, o usted, si lo va a atender, puede traer equipo adicional al centro de datos del cliente y simplemente conectarlo en modo on-line a la arquitectura ya lista. Todo esto se hace de forma rápida y, lo más importante, accesible. Los servidores x86 están disponibles en el mercado. Y también quiero destacar que no nos atamos a los fabricantes de estos servidores. Si usted suministra software, y nosotros con usted lo vendemos al cliente, entonces los servidores solo tienen ciertos requisitos de configuración que debemos tener en cuenta. Desde el punto de vista del fabricante del proveedor de este hardware, su disponibilidad y otros factores, no hay restricciones.
El segundo punto es la reducción del TCO (Costo Total de Propiedad). Podemos suministrar la solución como software, algo que prácticamente nadie hace en el mercado; la mayoría son soluciones integradas (PAKs), lo que implica una dependencia del hardware, el equipo propio y el proveedor. O bien, pueden ser PAKs de nosotros, si el cliente quiere tener todo desde una sola fuente, con soporte completo y reemplazo en caliente. En el caso del suministro de un PAK, el cliente recibe una solución integral completa. De esta manera, reducimos el TCO en comparación con las soluciones modulares, ya que arquitectónicamente somos más económicos. El software y los componentes con arquitectura x86 son menos costosos que las soluciones modulares. Así que somos libres de hacer lo que queramos, y ustedes también tienen las manos libres para configurar soluciones. Es decir, como una de las opciones de negocio, apoyaremos que ustedes, como socios, propongan configurar ciertos PAKs para los clientes por su cuenta.
La flexibilidad en la configuración del almacenamiento es otro aspecto que ofrecemos. Podemos, dependiendo de la tarea que el cliente necesite resolver, por ejemplo, si hay grandes bloques de datos que deben ser escritos, pero no se hace hincapié en el almacenamiento en sí, sino en la entrada/salida de datos activos. Esta es una opción de configuración. La segunda opción es el almacenamiento en frío de datos, cuando, por ejemplo, el cliente tiene muchos objetos diferentes, pequeños, medianos y grandes, que se almacenan a largo plazo según ciertos criterios. En este caso, podemos reconfigurar nuestra solución y agregar nodos de un formato de rendimiento específico para el almacenamiento, etc. Nuestra solución se configura de manera muy flexible en términos de componentes de disco, capacidad de los discos, potencia de los procesadores, etc. No estamos limitados en cuanto a las opciones de parámetros de configuración del hardware. Esto también es muy importante para el cliente.
Ofrecemos una configuración multi-datacenter, y no se trata de configuraciones aisladas, sino de una gran configuración extendida a múltiples centros de datos. Es decir, es un sistema que cubre completamente la solución con un clúster, con almacenamiento multi-datacenter. Y tenemos ejemplos de varias ubicaciones. En VK tenemos 4 ubicaciones en las que almacenamos nuestros datos. Y todo es una gran instalación.
Y el último punto, también importante, es que es un desarrollo propio desde el ciclo cero.
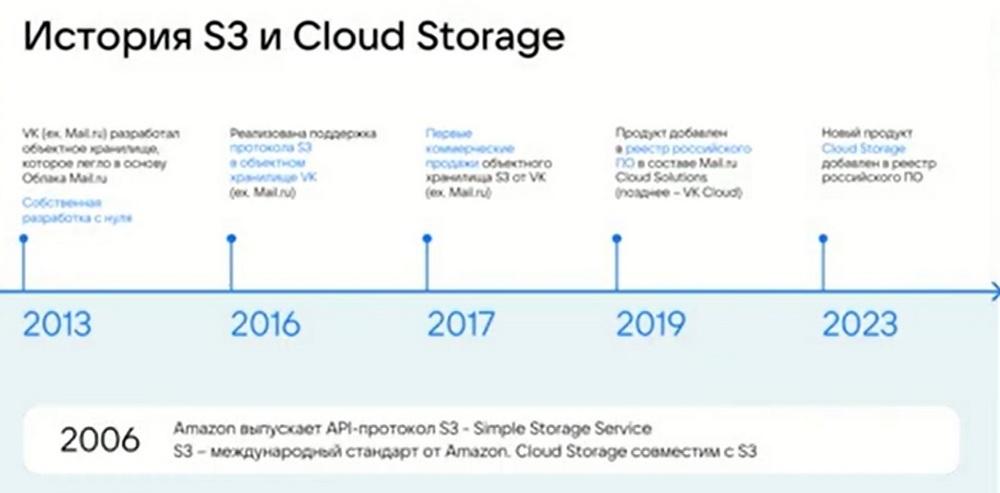
Un poco de historia. En 2006 comenzó el informe sobre el protocolo y la tecnología S3. Fue ideado y lanzado por Amazon para sus centros de datos y almacenamiento en la nube. VK se unió a esta carrera en 2013, todavía como parte de Mail. Y desarrollamos el primer almacenamiento de objetos para nuestra propia nube. Almacenábamos contenido para el agente de correo. Nuestro correo, nuestra nube Mail.ru, utilizaba completamente nuestra solución VK Cloud. En 2016 se implementó el soporte completo del protocolo S3 en el almacenamiento de objetos de VK. En 2017 comenzamos las primeras ventas comerciales de almacenamiento de objetos ya como un producto independiente dentro de las plataformas. En 2019 agregamos el producto al Registro de software ruso como parte de Mail.ru Cloud Solutions. Y en 2023 convertimos este producto en una unidad de combate separada. Es una solución de almacenamiento de datos absolutamente independiente. También le dimos un nuevo nombre de registro y un nuevo registro. Ahora es un proyecto completamente independiente con una larga historia de desarrollo de casi 10 años. Durante este tiempo, hemos corregido muchos errores, como todos los desarrolladores que recorren este camino. Y podemos decir con seguridad que somos lo más consistentes y perfeccionados posible en términos de funcionalidad. Esto es lo que dicen nuestros clientes. Estamos incluidos en el Registro, hay un registro, puede encontrarlo en el sitio web del organismo estatal correspondiente. Todo esto es de acceso público, y estamos dispuestos a compartir esta información con ustedes si es necesario.

Nuestra solución es potente y de alto rendimiento. No hay análogos en el mercado en cuanto al volumen de almacenamiento de datos en una sola instalación. Actualmente almacenamos más de 350 PBytes de datos en nuestros 4 centros de datos. Y experimentamos diariamente el funcionamiento de esta solución. Hemos tenido casos en los que los centros de datos se han desconectado, ha habido incendios en centros de datos en Rusia. Uno de los centros de datos fue alquilado por nosotros en ese mismo momento. Y nuestra solución cambió sin problemas y continuó funcionando incluso en caso de emergencia. Almacenamos más de 30 mil millones de objetos en acceso activo. Y 90 mil millones de objetos están en acceso general frío. Esto no significa en absoluto que debamos vender exactamente las mismas instalaciones grandes. Esto solo indica que nuestra solución está lo más perfeccionada posible y es capaz de ofrecer condiciones de funcionamiento ideales en términos de riesgos de pérdida de datos y rendimiento en la escalabilidad del sistema.

Ahora hablemos de las opciones de suministro. La primera opción es el software. En este caso, vendemos licencias perpetuas, no transferibles, es decir, no están limitadas en el tiempo, no es una suscripción, es una licencia completa que se adquiere una vez y se transfiere al balance del cliente y es de su propiedad total sin límite de tiempo. La licencia se basa en los terabytes de datos útiles. Es decir, básicamente, si el cliente necesita almacenar 100 TBytes de datos, ofrecemos una licencia de software para 100 TBytes, independientemente de la configuración de la plataforma con el factor de replicación que esté presente, etc. El soporte, como la mayoría de los proveedores, se vende por períodos determinados: uno, dos, tres y cinco años. El plazo máximo es de cinco años. Podemos venderles el soporte como un certificado o como un servicio. Dependiendo del presupuesto del cliente y de la partida de gastos con cargo a la que esté dispuesto a comprarlo.
Vendemos PAKs en diferentes variaciones. Hay situaciones en las que al cliente no le importa qué tipo de equipo se encuentra dentro de este PAK. El equipo puede estar registrado o no. Por defecto, no ofrecemos hardware registrado para reducir el costo de la configuración y ofrecer un precio más competitivo en el mercado para nuestro PAK. Pero, si el cliente dice que tiene ciertos requisitos del regulador, o una orden interna para cumplir con los requisitos del regulador sobre la disponibilidad de componentes registrados del complejo de hardware, entonces podemos suministrar componentes registrados en nuestro PAK. Es decir, son posibles todas las opciones. Cooperamos con todos los principales proveedores en el mercado ruso, y podemos suministrar una amplia variedad de configuraciones basadas en nuestro PAK. Al mismo tiempo, si el PAK es suministrado por nosotros, independientemente de los componentes que lo compongan, brindamos soporte centralizado para ustedes y para nuestros clientes, tanto para la parte de hardware como para la parte de software. Y tanto en el caso del software como en el caso del PAK, brindamos servicios de puesta en marcha y puesta en marcha del software, puesta en marcha del PAK y soporte. También podemos ofrecer servicios de capacitación del personal. Podemos capacitar tanto a ustedes como a los empleados del cliente para que trabajen con nuestro sistema.
La tercera opción de implementación es la nube pública para los casos en los que entendemos que el cliente realmente lo necesita, pero no está dispuesto a instalar un complejo en su centro de datos, no tiene requisitos para su propio circuito aislado y el volumen de almacenamiento es inferior a 50 TBytes. En este caso, podemos ofrecer Public Cloud. Y ustedes también pueden revenderlo en sus documentos para el cliente y ganar dinero con ello.
Luego tomó la palabra Georgy Sorokin, arquitecto de Cloud Storage. Comenzó a contar cómo está organizado Cloud Storage. Está dividido condicionalmente en tres niveles funcionales, cada uno de los cuales es responsable de su función. Este es el nivel de los servidores Front, el nivel de los metadatos y el nivel de los servidores de almacenamiento. En las grandes soluciones, separamos estos niveles, incluso físicamente. Cada uno de estos niveles consta de servidores absolutamente separados.
Los servidores Front son los servidores que procesan todas las solicitudes entrantes, procesan la carga, calculan los hashes y distribuyen la información entrante a los servidores de almacenamiento. Estos son los servidores en los que se almacenan los propios objetos.
El nivel de los Meta-servidores es el nivel en el que se almacena la metainformación sobre todos los objetos. Se registra y se escala por separado. Este nivel funciona en la plataforma in-memory Tarantool. Es gracias a él que tenemos 350 PBytes de datos que podemos escalar. Porque incluso en estos grandes volúmenes, nuestro tiempo de respuesta no disminuye en absoluto.
En cuanto a la escalabilidad. Podemos escalar de diferentes maneras. Si, por ejemplo, inicialmente había un cierto volumen, por ejemplo, 5000 IOPS. Había una carga en el sistema. Y de repente el cliente necesita aumentar esta carga. Hay más clientes o el sistema se ha vuelto más cargado. Simplemente podemos aumentar el número de servidores Front que son responsables de procesar las solicitudes entrantes. Y si aumenta nuestro volumen de datos, normalmente simplemente agregamos servidores de almacenamiento. Por lo general, junto con los servidores de almacenamiento que son responsables de guardar los objetos, si aumentan, es lógico que también aumente el número de objetos, de lo que son responsables nuestros Meta-servidores. En consecuencia, agregamos Meta-servidores. Cada una de estas capas se puede escalar por separado, lo cual es muy importante. No es necesario, como en el caso de que estas funciones estuvieran en un solo servidor, agregar todas las capas a la vez. Elegimos el parámetro que necesitamos activar y agregamos servidores de acuerdo con esta necesidad.
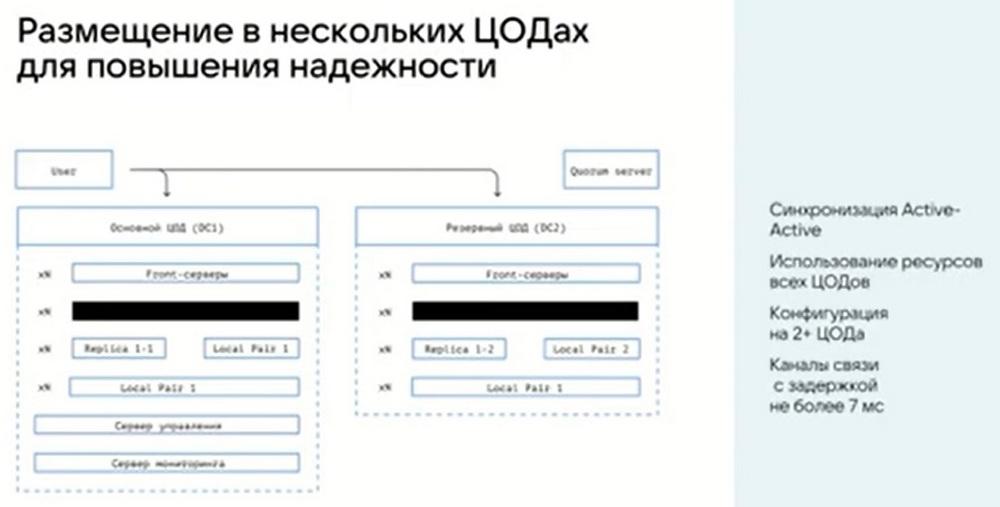
Ahora sobre varios centros de datos. Aquí nuestra solución funciona en modo distribuido. Esto significa que no hacemos que un centro de datos sea activo y el segundo pasivo y no configuramos la replicación entre ellos. Nuestra solución funciona de forma distribuida entre varios centros de datos. Dos, tres, cuatro o más, no importa. Y el trabajo se realiza inmediatamente con todos los servidores, con todos los objetos que se encuentran en estos centros de datos.
En cuanto al nivel de replicación. Tenemos servidores de almacenamiento. Por lo general, se agregan en pares. Esto se debe a que, por defecto, el factor de replicación es igual a 2. Cada uno de nuestros objetos se almacena en dos copias, y cada una de estas dos copias siempre se almacena en un servidor separado y en un disco separado. Todo esto está integrado en la arquitectura del sistema y los objetos no se pueden ubicar de otra manera. Se excluye la situación en la que ambas copias de un objeto se encuentren en el mismo servidor o en el mismo disco. Si hablamos de una configuración multi-datacenter, siempre se encontrarán automáticamente en diferentes centros de datos.
Sobre la metainformación. Gracias a Tarantool, podemos configurar el factor de replicación, es decir, el número de copias que almacenamos de la metainformación. Por defecto, utilizamos 3 copias. Para varios (dos, cuatro) centros de datos, aumentamos este factor a 4. Para que sea posible ubicar los centros de datos simétricamente. Gracias a Tarantool, tenemos sharding, cuando dividimos una gran base de datos en varias y las ubicamos en máquinas separadas, precisamente por eso tenemos la posibilidad de aumentar una enorme cantidad de información y una enorme cantidad de objetos sin degradar el rendimiento. Dado que todos los datos sobre ellos se almacenan en máquinas separadas en memoria separada y esto lo gestiona una instancia separada de Tarantool.
En cuanto a las replicaciones y los retrasos, el retraso estándar entre los centros de datos que recomendamos no es superior a 7 milisegundos. Pero esto no significa que no admitamos un retraso mayor. Podemos trabajar tranquilamente con 20 o 30 milisegundos. Pero hay que entender que nuestro sistema es distribuido, la escritura es síncrona, y para que un objeto se considere escrito, debemos recibir confirmación de cada centro de datos.
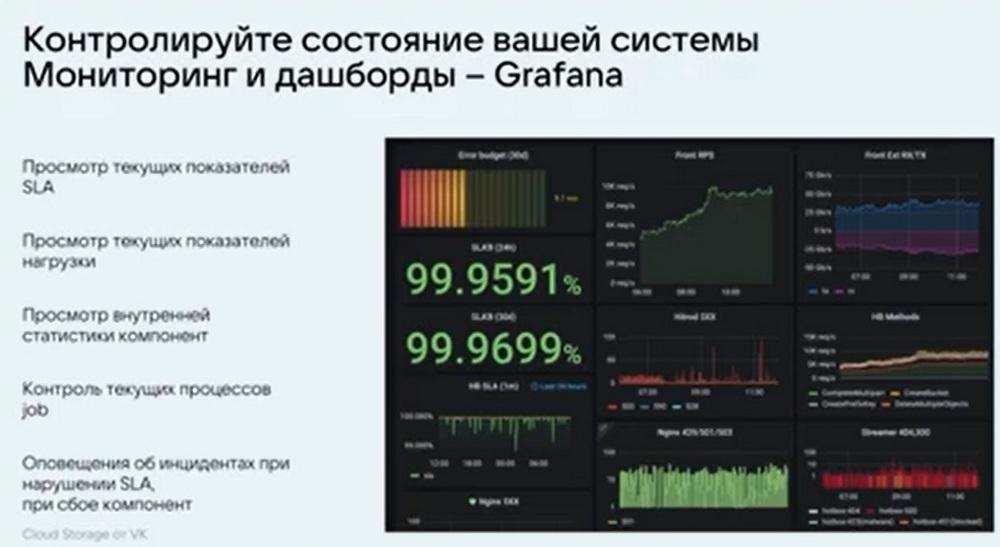
Tenemos nuestro propio sistema de monitoreo, hay paneles. Todo funciona en Grafana. Mostramos toda la información básica sobre el funcionamiento del sistema, esto es la carga, el RPS, el funcionamiento de los servicios individuales, el rendimiento, y esto es solo una pequeña parte de los paneles. En realidad, hay 10 veces más. Y se puede profundizar en los detalles más pequeños, ver qué y cómo funciona, prevenir errores y procesarlos con anticipación, sin llevarlos a eventos críticos.
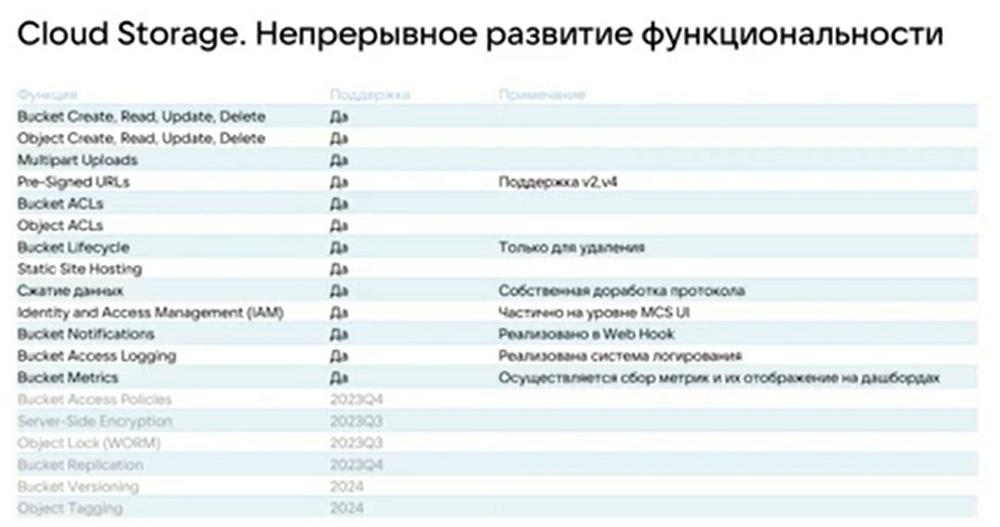
En cuanto a la funcionalidad, mantenemos el protocolo estándar S5, desarrollado por Amazon. Y las funciones básicas que admitimos, en principio, son todas las funciones. Algunas de ellas todavía están en desarrollo, las que son menos críticas. En la pantalla puede ver lo que admitimos y un pequeño reloj para los próximos trimestres, lo que ya está incluso en pruebas.