В сегодняшнем мероприятии участвуют Иван Макаров, начальник отдела по работе с DLP в финансовой организации. Таким образом мы пригласили на встречу, где о своем опыте использования DLP-системы Traffic Monitor расскажет клиент InfoWatch — начальник отдела и эксперт ИБ, работающий с DLP в крупной территориально распределенной финансовой организации, в которой DLP-система отрабатывает 2 млн событий в неделю.

Представитель клиента Иван Макаров поделится кейсами работы с DLP-системой Traffic Monitor из собственной практики и расскажет, как регулярно работает с группами риска, расследует инциденты и что находит в «серой зоне» инфопотоков.
Сегодня будут рассмотрены следующие вопросы:
- Как выявить аномальный вывод информации, если документы не размечены политиками безопасности. И как разобраться — это инцидент ИБ или особенность служебных обязанностей?
- Как DLP-система Traffic Monitor помогла пользователю детектировать аномальный вывод на печать документов, неразмеченных политиками безопасности, и разобрать несколько тысяч документов за 1 час вместо 60 человеко-часов ручного труда.
- Как часто и зачем рекомендуется разбирать «серую зону» инфопотоков и возвращаться к настройке политик DLP-системы.
- Как уникальные возможности автоматизированной обработки данных и технологии искусственного интеллекта Traffic Monitor помогают в работе на больших объемах информации и событий.
Начал свое выступление Иван Макаров с того, что рассказал, что они продукцию InfoWatch начали использовать примерно с 2015 года. А активное использование они начали проводить в компании примерно с 2020 года. Было выделено под это отдельные ресурсы и потихоньку они начали более подробно смотреть, что у них в компании происходит.
На данный момент численность нашей компании составляет порядка 3500 человек. При этом по регионам России у нас имеется около 200 отделений разного масштаба. Есть крупные офисы, есть совсем маленькие, где сидит 1-2 человека. А есть офисы, где работает по 100-200 человек. Все они удалены друг от друга.

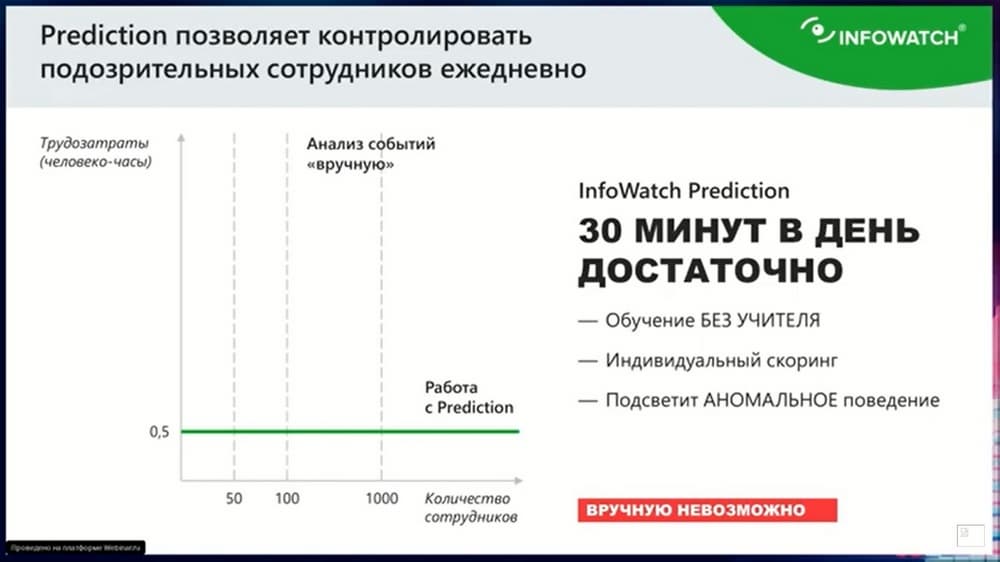
И бизнес-процессы в компании очень разнообразные и местами даже бывают хаотичными. Некоторым специалистам иногда приходится на лету изучать новый бизнес-процесс, который даже не задокументирован. Многие специалисты в области ИБ сталкиваются с такими моментами, когда во время работы внезапно случайно обнаруживается некий бизнес-процесс, который не согласован с ИБ. В среднем в неделю генерируется до 2 млн событий. В эту статистику попадают события печати, вся почта, в том числе внутренние мессенджеры, которые работают только на внутреннем контуре. Надо отметить, что примерно 70% событий это события с вложениями, с какими-то файлами, документами, т.е. не просто переписка (если говорить о почте). И зачастую надо понять, что там происходит, для чего письмо куда-то ушло и желательно это понять еще до того, как ты созвонишься с пользователем и узнаешь его мотивы. На этапе получения события надо это попробовать узнать, что это и зачем. И один из новых инструментов, который нам предлагает компания InfoWatch, когда мы это установили и попробовали, позволило исполнить некую процедуру без созвона с пользователем. Мы смогли сами примерно понять, какой процесс он инициировал и зачем он сделал то, что сделал. И как с этим дальше быть. Нам оставалось только позвонить и узнать мотив.

Если мы берем статистику почтовых сообщений, неделю у нас трафик копируется, он не находится в разрыве. Ввиду особенностей бизнеса нам нельзя его прерывать. А большое количество событий не позволяет обрабатывать все это в онлайн режиме. Поэтому мы пошли на своеобразный риск – копирование и постфактум выявление событий. Пока это себя оправдывает. Мы умудряемся на мелких оплошностях дисциплинировать народ так, чтобы они не выходили за рамки минимально приемлемых рисков. Разбивка у нас приблизительно такая. Именно почтовые события, которые мы стараемся посмотреть за неделю. Т.е. это FTE двух человек, которые работают без перерыва по 8 часов в день. Берем два человека на DLP с наличием такого инструмента, как InfoWatch Vision, они обрабатывают такое количество событий за неделю. Остается резонный вопрос, а куда девать остальные события? Что делать с печатью, генерируется под 100 000 событий в день, на флешки запись идет по 600-700 в день. Это тоже надо кому-то все это разгребать. Можно попробовать это ужать, а вот как быть с печатью – вопрос отдельный.

В итоге, когда мы начали сотрудничать с InfoWatch более плотно, мы начали потихоньку тестировать новые продукты, предлагаемые InfoWatch. И один из первых продуктов, который попал к нам «на пилот» еще в ранней стадии, был InfoWatch Prediction. Я с ним работал с самых первых версий и понимаю его возможности. Считаю его очень полезным инструментом, он позволяет создать некий процесс в компании, при котором офицеры ИБ, работающие с DLP, будут постоянно в работе. Не в бездумной работе все подряд перекапывая, а более целенаправленно пытаться найти то существенное, что произошло за или может произойти за неделю. Т.е. InfoWatch Prediction это аномальный вывод информации, так у нас и произошло. Сотрудник просматривал InfoWatch Prediction. Увидел прежде всего – вывод информации. У человека аномалия. Смотрим, что за аномалия. Подключаемся через досье, начинаем смотреть, когда пики этой аномалии происходят. Видим, что аномалия происходит нерегулярно, а в какие-то промежуточные дни. Он за 3 месяца нам посчитал, и показал, что в какие-то определенные дни у него 20 аномалий. И все это выводится на флешку. Хорошо. Смотрим, что говорит нам InfoWatch Vision. Какое количество событий происходит в эти пики. В среднем за один раз человек 600 каких-то документов, которые на тот момент нам были неизвестны, грузит на флешку. Для чего и что это за документы? Мы делаем выборку в Traffic Monitor и видим, что там непонятно, что это, надо или не надо, по работе или нет. Вроде по работе, но при этом нет никакого упоминания о нашей компании. Т.е. это не про нас. И не понятно, что с этим делать. И при этом объем огромный. Мы просмотрели 10 или 20 штук. Допустим, мы потратим целый день на одну такую аномалию. А у него таких аномалий было за 3 месяца штук 5 или 6. Допустим, мы посмотрим одну такую аномалию, попытаемся понять, что происходит. Но это же не серьезно! Получается просто убитый FTE, а если результат будет никакой? Т.е. если все действия сотрудника были связаны с его работой, и все нормально. С одной стороны, мы, как информационная безопасность, понимаем, что честно отработали, но что мы ответим руководству? Что мы угробили целый день на то, чтобы посмотреть, какой тип документов Петров скидывает на флэшку? Возникнет много вопросов, в том числе и у руководства.

Тут нам на помощь приходит пилот, который мы получили сравнительно недавно. Мы сделали выборку в Traffic Monitor, создали специальные события, где можно создавать выборки. Эти выборки сделали по этому человеку, указали промежуток времени, который мы хотим посмотреть и только то, что он скидывает на флэшку. Потом в Data Explorer эту выборку скормили. Сказали, разбирайтесь!
Забыл упомянуть, мы рассчитывали FTE и, если посчитать все аномалии, то 5 или 6 раз по 600- 800 документов. Мы приблизительно прикинули, двум сотрудникам потребуется 30 трудочасов, чтобы это разобрать. По сути дела нужно 2-3 дня на то, чтобы разобрать все эти аномалии. Причем это будет около 4000 документов. А если их больше? Вышло так, что он нам нашел все эти выборки за 1,5 часа. Начали смотреть, что за кластеры. И увидели, что кластеры расписаны (в нашем случае для человека все хорошо закончилось) по его работе. Нам он дал Data Explorer по сути дела исходя из того, какие темы и слова упоминаются в документах, он смог нам сформировать где-то 12 категорий, которые были связаны с деятельностью этого человека в рамках нашей компании.

Плюс поток документов, который показывала выборка, позволял сделать вывод о том, что там, где большое количество документов, которое попало под этот кластер, то там все нормально. Остался вопрос про узкие кластеры по 2-3 документа. Но, когда мы туда провалились, мы увидели, что это частные случаи из разряда, попал случайно какой-то текстовичок, где человек копировал ссылки на контрагентов. Ничего серьезного.
Затем мы посмотрели, насколько это связано с его рабочей деятельностью. И пришли к выводу, что все нормально. Просто в чем тут момент? Нам это позволило создать, во-первых, около 12 категорий. Но для того, чтобы мы эти документы в дальнейшем улавливали, мы поняли, что этот процесс для этого сотрудника является рабочим процессом. Это хорошо. Но если вдруг каким-то образом эти документы будут оказываться у других людей, или как-то по-другому присылаться от нашей организации, т.е. каким-то образом выйдут за пределы того, где они должны находиться, то мы должны на это реагировать. Чтобы именно эти документы мы могли точнее улавливать, нам Data Explorer позволил сформировать 12 новых объектов защиты с помощью autolingva. Также Data Explorer нам помог сэкономить около 4 сотрудников, что с точки зрения загруженности работой для компании очень хорошо. И на данный момент мы продолжаем регулярно исследовать с помощью Data Explorer разные направления. Например, автоматическую рассылку. Скажу сразу, мы исследуем большие блоки, в которые может попасть что-то не то. Можно на одном ящике «сидеть», при этом мы создаем роботизированный какой-нибудь ящик, который постоянно отправляет новостную рассылку.

И никто не мешает администратору в одну из таких рассылок запихнуть постороннюю информацию. И таким образом ее увести. Одним из преимуществ Data Explorer является то, что после того, как вы первично прошлись по какому-то разделу серой зоны, после того, как вы разобрали какой-то пул документов, в дальнейшем вам будет проще создать новую выгрузку, новый запрос в базу сделать, где как раз уже размеченные документы не будут учитываться. И вы таким образом сможете более точно находить более узкие каналы, где может что-то утекать.

У нас часто фигурирует слово «может». Но тут это все-таки инструмент, он за вас работу не сделает, он вам только помогает. В общем преимущества комплексного подхода у двух инструментов InfoWatch Prediction и Data Explorer, они позволяют в первую очередь экономить, а я сужу с точки зрения работника, начальника подразделения, а не бизнеса, я смотрю на то, чтобы сократить работу моих сотрудников, чтобы это было рационально, и при этом меньше получать нагоняй, если вдруг что-то мы пропустим. И вся эта история позволяет сократить как минимум один процесс до час-двух в неделю, когда вам придется перерабатывать большие объемы документов. Например, в понедельник вы берете данные за прошлую неделю и создаете какую-то выборку, скармливаете это Data Explorer и смотрите, что получилось. Пока он разбирает часть серой зоны, вы идете в InfoWatch Prediction, смотрите аномальные выводы. Хорошо, если это будут 1-2 случая. Это легко разобрать и вручную. Но, если это окажутся большие объемы информации, то точно также по ним создаете выборку и скармливаете Data Explorer. В принципе, за неделю по нашей практике мы смогли через него протащить от 60 до 80 тысяч событий. При средней загруженности. Можно через него протаскивать большое количество событий. Другой вопрос, насколько они однотипны, и насколько там получится из них что-то вытащить, местами присутствует вопрос некоторого везения. Однажды он создал мне за один раз 40 кластеров и все они были довольно плотно заполнены. Я посмотрел, что не совсем корректно был создан запрос для того, чтобы Data Explorer его корректно проанализировал. Но в целом мне, как администратору систем DLP, очень сильно упрощает жизнь и в создании правил, и в выискивании сложных моментов, которые требуют глубокого долгосрочного анализа. В этом плане мне Data Explorer очень нравится. Он помог за полтора часа разобраться в сложной ситуации.

И это не преувеличение. И это с учетом того, что мне надо было доложить руководству об этой ситуации, объяснить все эти графики, все черточки и рисочки, которые сделал, напечатав скриншоты, для того, чтобы был предмет разговора с руководством. Потом я сделал кластеры, объяснил, что это значит, и почему, и еще изучал должностную инструкцию сотрудника и созванивался с ним на предмет, для чего он это делает. Как оказалось, человек работает на выезде, и он эти документы себе копирует на рабочий ноутбук с помощью рабочей флэшки. Т.е. он планирует на одну-две недели график, с кем он будет работать, и, для того, чтобы у него под рукой всегда были материалы, с которыми он будет работать, он копирует их на флэшку, с нее на ноутбук, а ненужные он либо копирует обратно, либо затирает. Потому что у нас по требованиям компании ноутбук не позволяет подключаться к сетям общего доступа, только по шифрованному каналу. И возникает проблема с тем, что не всегда может быть интернет и все в таком духе. Поэтому он таким образом обезопасился.
Вопрос ведущей. Посмотрим, какие возможности позволили эту новую практику ввести в методологию работы вашего отдела. Хочу уточнить один момент, я правильно поняла, что по факту актуализация политик у вас сейчас происходит гораздо чаще, чем традиционная то, о чем мы слышим на рынке, то есть один раз в год или раз в полгода?
Конечно, гораздо чаще. Потому что я не упомянул о такой замечательной вещи, как автолингвист. Связка работы в актуализации политик у нас теперь происходит почти каждый месяц, а подчас и еженедельно. В зависимости от категорий и направлений. Есть некоторые направления, которые мы можем раз в неделю поправлять, но это когда выявляются небольшие косяки. Нам надо накопить подборку информации, чтобы понять, что с этим делать. Но в целом какие-то новые объекты защиты, которые мы потом добавляем в те или иные политики, это раз в одну-две недели.










