Мероприятие OCS и «ДАКОМ М», российского разработчика импортозамещающей экосистемы виртуализации Space. Мероприятие посвящено обзору платформы Space VDI: ключевым нововведениям в релизах 5.3 и 5.4, а также вопросам адаптивности Space VDI к изменяющимся требованиям и оптимальному использованию ресурсов. Space VDI ждут серьёзные изменения, направленные на повышение отказоустойчивости решения, реализацию новых функций и увеличение общей производительности системы.
Программа мероприятия: кластерная архитектура, отказоустойчивая схема, масштабирование, Space Agent PC (VDA) и Space Gateway.
Сегодняшний спикер: Руслан Белов, директор по продукту Space VDI.
Сегодня речь пойдет о том, что вышло в последних релизах Space VDI 5.3, который появился после 4-го квартала 2023 годы и Space VDI 5.4, который вышел буквально месяц назад.

Экосистема VDI представляет собой набор, в который входит следующие компоненты:
- облачная платформа Space VM для централизованного управления инфраструктурой,
- ПО Space Dispatcher (Space Disp) – диспетчер подключений виртуальных рабочих столов, отвечающий за подключение пользователей к назначенным виртуальным столам,
- собственный клиент подключения Space Client к инфраструктуре VDI с поддержкой ОС Windows, Linux и macOS.
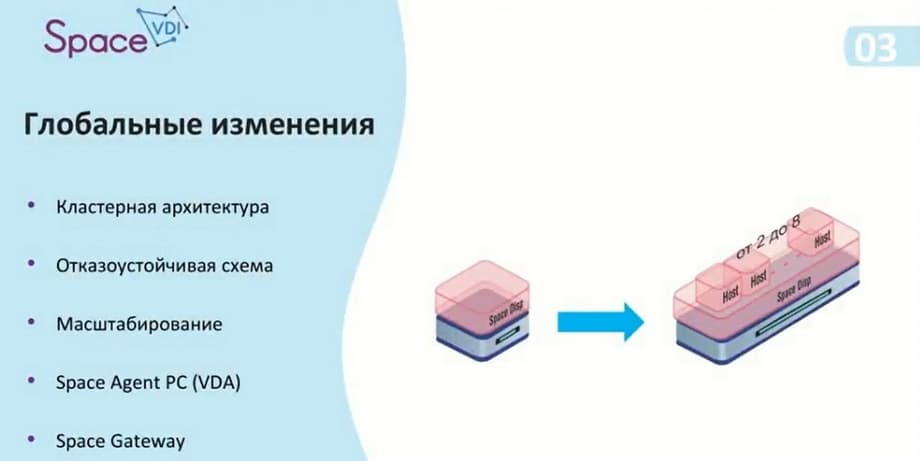
Сегодня мы будем говорить о Space Disp. Произошедшие изменения мы разделили на 5 категорий: это кластерная архитектура, отказоустойчивая схема, использование масштабирования, Space Agent PC (VDA) и Space Gateway. Мы решили отказаться от единого экземпляра диспетчера и перейти к мультидиспетчеру. Это позволило создать отказоустойчивую схему и расширить варианты масштабирования самой инфраструктуры. Кроме того, мы добавили возможность подключать физические машины и добавили такой функционал, как Space Agent PC, это утилита, которая ставится на физические машины и позволяет передавать информацию об их состоянии. В дальнейшем через этот агент можно будет управлять самой машиной и настраивать ее конфигурацию. Для безопасности мы улучшили наш ИБ-шлюз.
Перейдем к теме кластерной архитектуры, определимся с сущностями, которые тут будут использоваться.
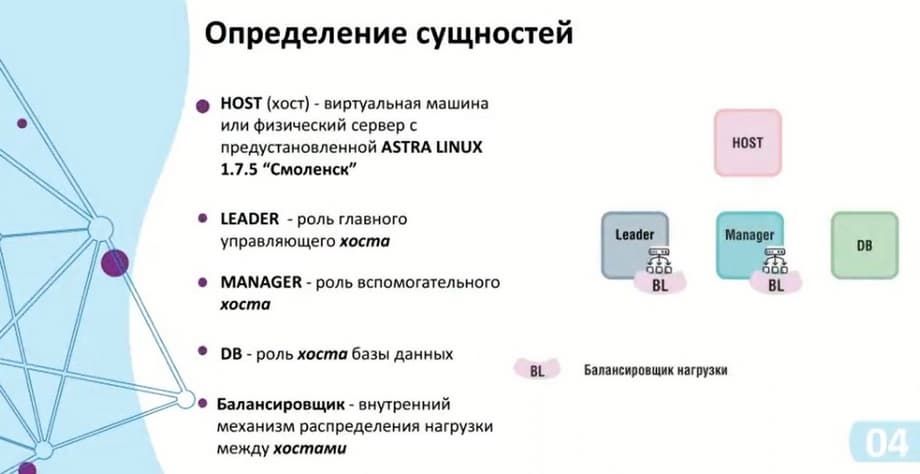
Первая сущность – это HOST – виртуальная машина или физический сервер с предустановленной ASTRA Linux 1.7.5 – «Смоленск», других операционных систем мы пока не поддерживаем. На сам хост с ОС можно поставить конкретную роль: Leader, Manager и DB (база данных). Leader и Manager будут участвовать в распределении нагрузки в кластере управления, а база данных будет находиться в кластере данных. Есть здесь и такой элемент как балансировщик (BL), который распределяет нагрузку между хостами.
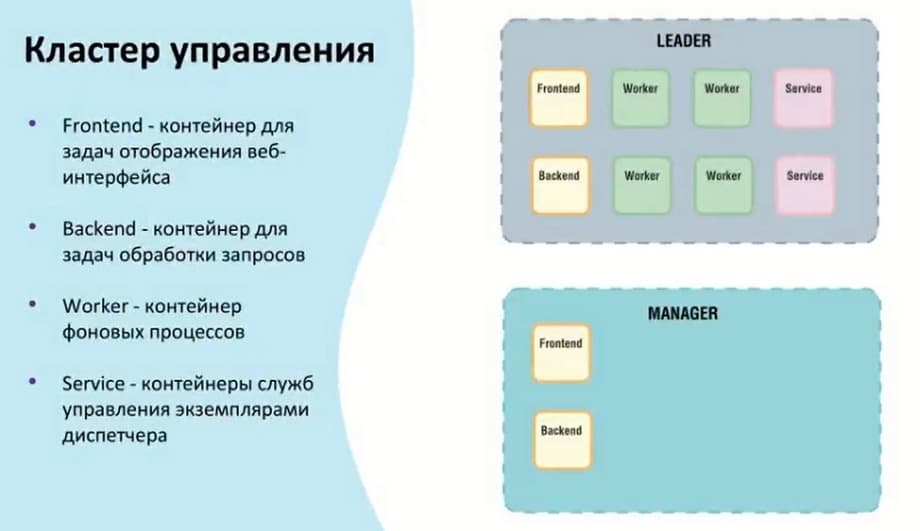
Кластер управления может выступать как Leader и Manager. Leader – это основной хост, который принимает на себя задачи по подключениям и проводке внутренних фоновых служб. Manager объединяет все контейнеры Frontend и Backend. Сделано это для того, чтобы в случае отказа Leader была возможность получить информацию о состоянии контейнеров и других данных. В случае отказа Leader есть возможность достучаться до самого вэб-интерфейса через Manager.
По поводу кластера данных. Изначально он состоял только из самой базы данных, но после его расширения с возможностью репликации. С релиза 5.4 при репликации использовались стандартные средства баз данных. Нет ограничений по настройке реплицируемой базы данных и самих вариантов репликации. Обеспечена доступность к данным обеих DB.
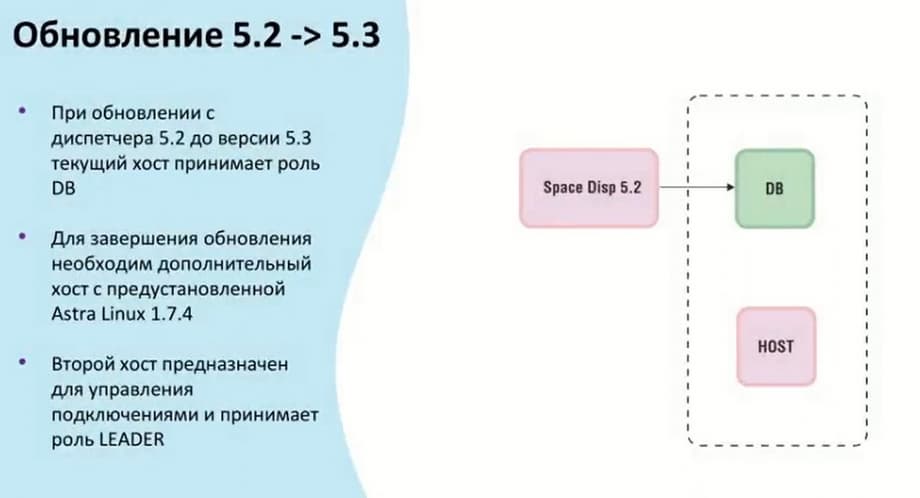
Так как появилось два кластера, под них будет необходимо как минимум два хоста, чтобы они появились при обновлении диспетчера с 5.2 на 5.3 текущий хост принимает роль DB. А второй хост, который был настроен на конкретный кластер управления, будет принимать роль Leader. Если их будет несколько, то остальные возьмут роль Manager. Роли Leader и Manager устанавливаются вручную. Сначала обновляется база дынных, после уже сами хосты в кластере управления.
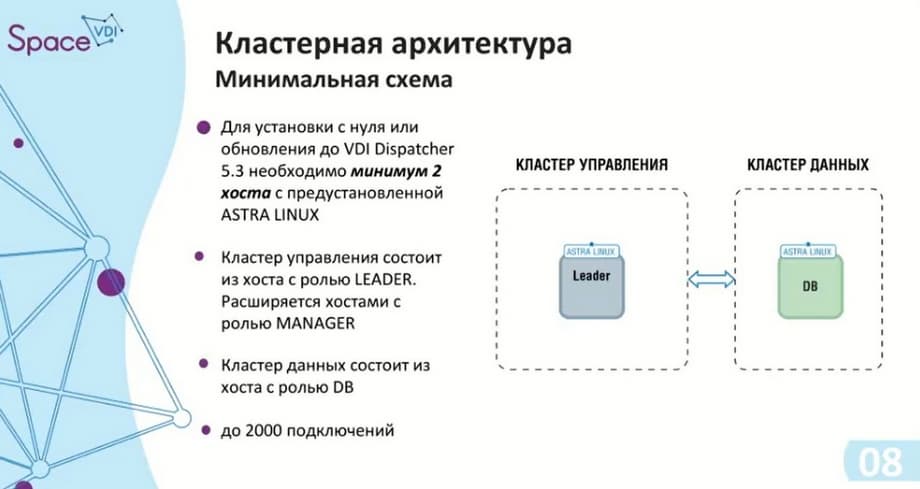
Про кластерную архитектуру. Из-за того, что есть два кластера, то есть и минимальная схема: два хоста с ОС ASTRA Linux, поэтому нужно иметь две лицензии. Под релиз 5.3 используется ASTRA Linux 1.7.4. Кластер управления, как и в случае с единым экземпляром, умеет поддерживать до 2000 подключений. Сейчас у нас минимальная отказоустойчивая схема - три элемента в кластере управления: сам Leader и два Manager.
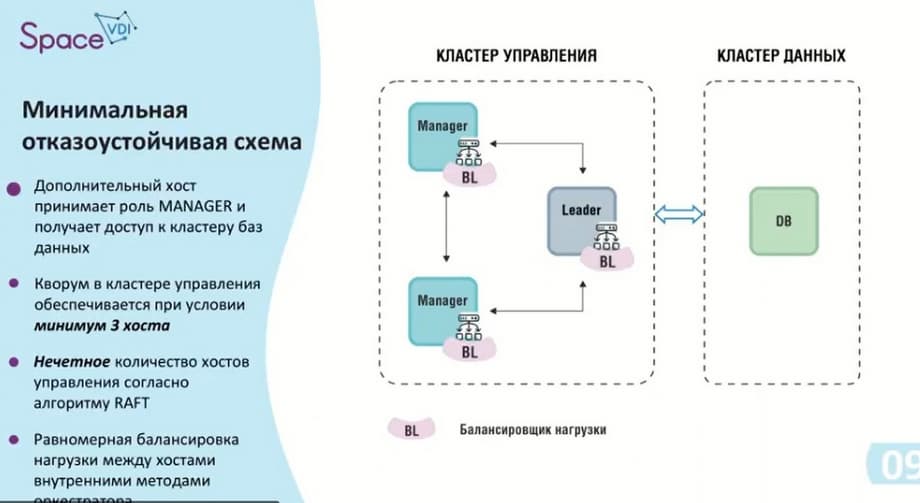
Согласно используемому алгоритму RAFT для обеспечения отказоустойчивости обязательно должно быть нечетное количество хостов. В данном случае начинает работать балансировщик, он распределяет нагрузку между хостами. Эту минимальную схему можно назвать первым контуром, она предоставляет до 6000 подключений. Если нужно меньше подключений, но отказоустойчивая схема, то подходит только такой вариант.
Если лидер и менеджер находятся в одном кластере и лидер не справляется с нагрузкой, он будет передавать оставшиеся подключения на сам менеджер.
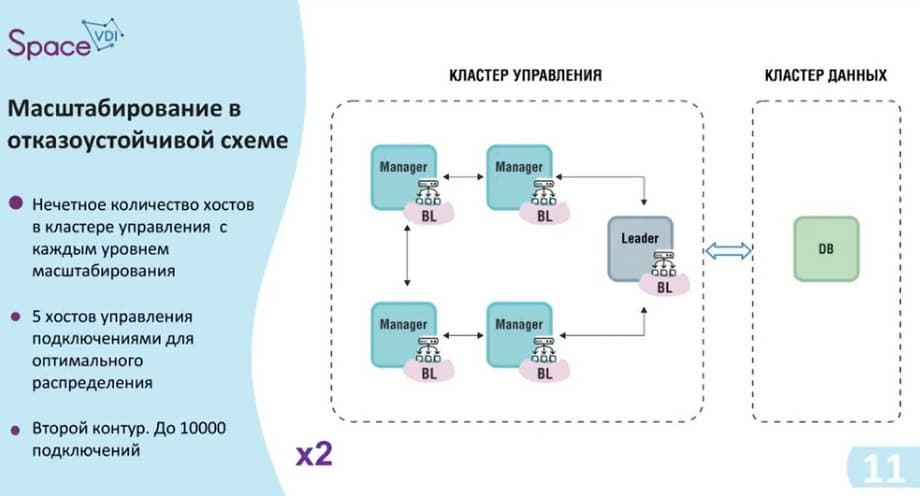
Также мы подходим ко второму контуру. Как я уже говорил, у нас нечетное количество самих хостов в кластере управления. Мы добавляем два дополнительных хоста, тем самым у нас получается кластер управления с возможностью до 10 тысяч подключений и, естественно, мы не забываем, что на каждый хост необходимо поставить ASTRA Linux, то есть в данном случае нам необходимо 6 лицензий ASTRA Linux.
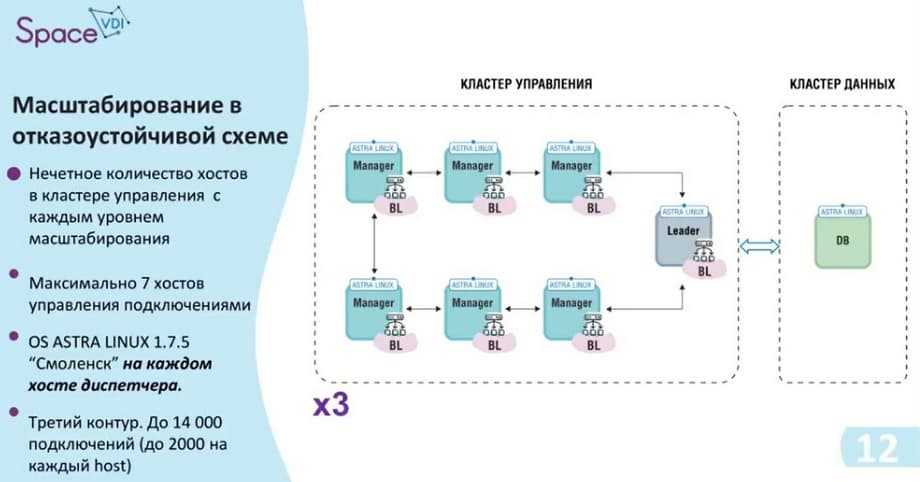
Этот контур был последним для релиза 5.3. Как я уже сказал, у нас улучшение было сделано в сторону кластера данных. То есть здесь мы добавляем еще два хоста на кластер управления, тем самым обеспечиваем 14 тысяч подключений, 2 тысячи на каждый хост и 8 хостов. И соответственно, если нам необходима репликация, максимальная схема с возможностью отказоустойчивости, показана на следующем слайде.
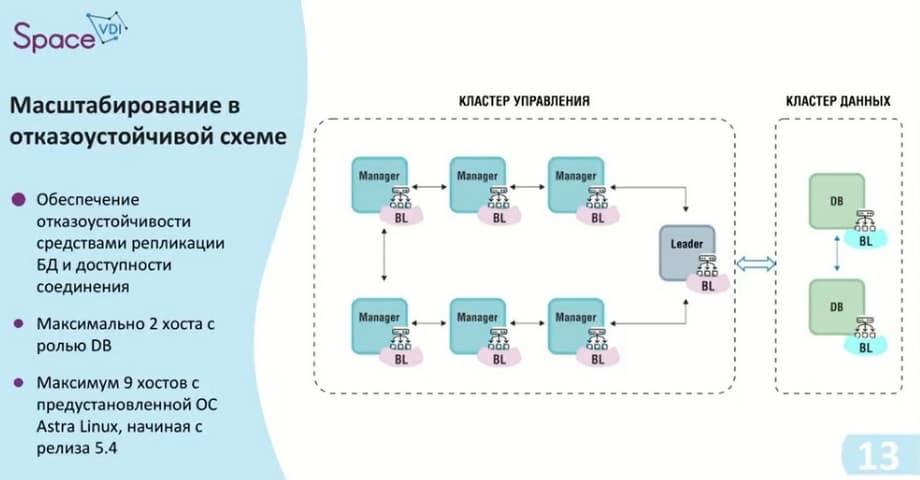
То есть, опять же, нечётное количество хостов в кластере управления, их семь, и это максимальное количество, т.е. больше диспетчер не поддерживает. Если необходимо больше 14000 подключений, то, что делать в этом случае, мы оценим на следующих слайдах.
Здесь между кластером управления и кластером данных используется Virtual IP, и тем самым мы имеем доступ к каждой базе данных. Т.е. мы видим на данном слайде, что на базе данных появился балансировщик. Т.е. в случае, если в какой-то момент потребуется доступ к реплике, то она может стать основной. И с нее будем считывать и записывать данные.
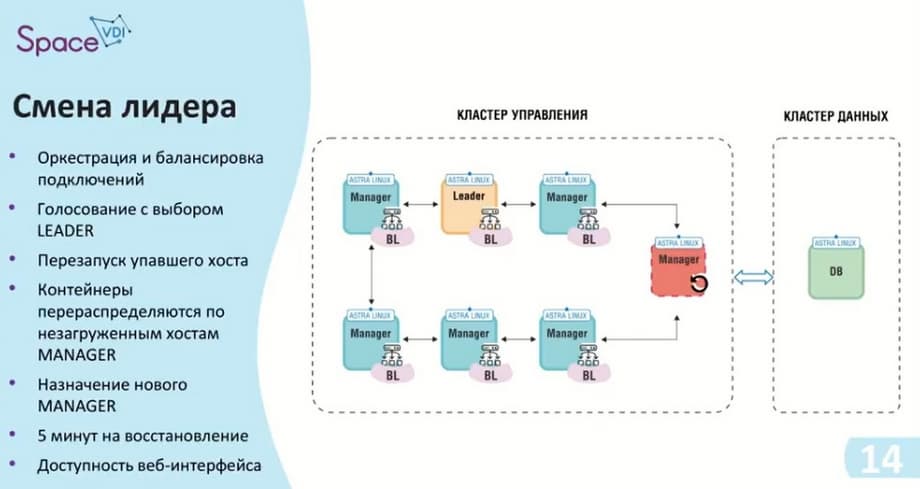
В случае, если отказывает один из хостов, в данном случае отказал лидер. Лидер принимает роль менеджера после его перезагрузки. Сама роль лидера передается дальше по цепочке. Здесь уже используется алгоритм, какой был указан - RAFT, идет голосование свободного лидера, и следующий, по списку самих хостов кто свободен, и может принять эту роль, он его занимает. Сама балансировка циклична, и также передает свои подключения на другие хосты. В момент, когда отключился лидер, происходит некая пауза, которая длится примерно 5 минут. В это время работают средства оркестрации и контейнеры, которые находятся на лидере, ну, либо на том хосте, который отказал, начинают переходить именно на тот хост, который принял роль лидера.
Как мы видели на первых слайдах, доступность интерфейса в любом случае будет, и мы можем отследить его состояние. Единственное, что у нас не доступно, это некоторые фоновые службы и какие-то процессы, которые происходили на лидере.
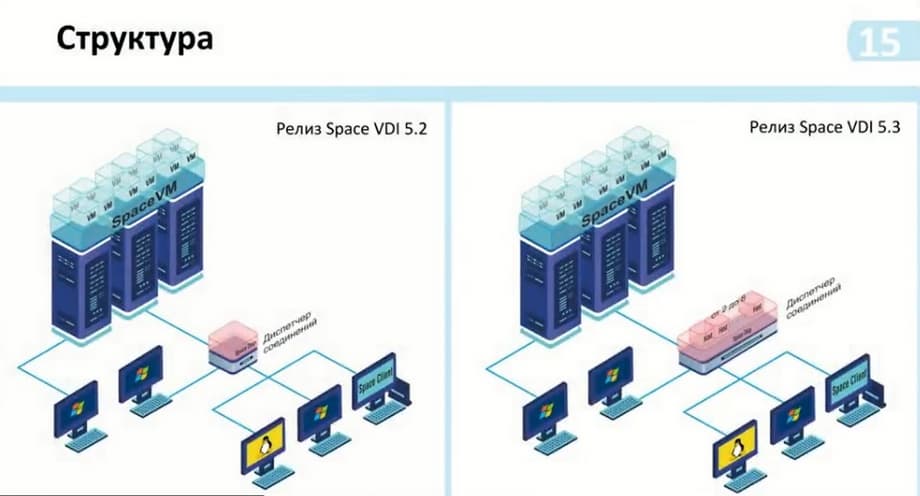
Как раз такие изменения в самом масштабировании с релизом VDI 5.2 и VDI 5.3 отображены на слайде. Т.е. в целом они изменились не сильно. Мы видим, что сам диспетчер соединений стал больше. Появилось от 2 до 8 хостов на самом диспетчере. Здесь мы указываем - без репликации. Реплика стала основной частью схемы. Она устанавливается по желанию и в зависимости от необходимости использования.
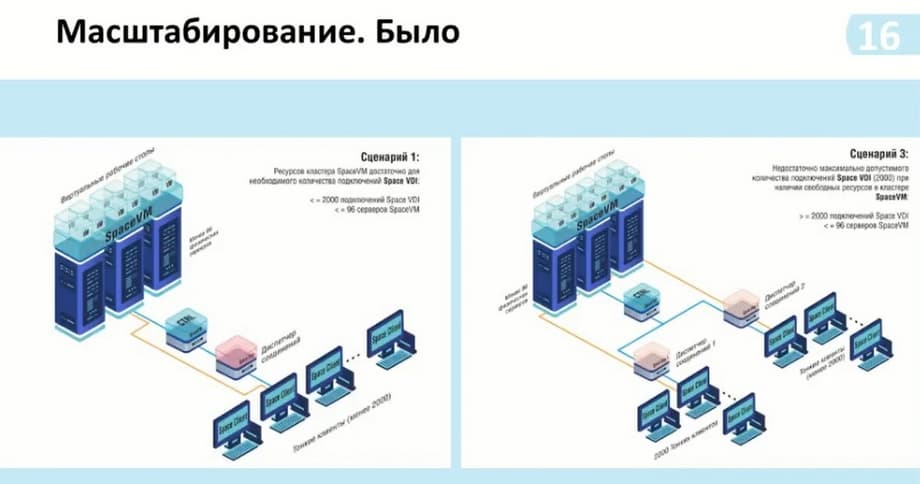
И по этой схеме мы также могли видеть возможность подключения от двух и более тысяч пользователей. И до этого у нас, чтобы это сделать, необходимо было поставить еще один диспетчер соединений и подключить его к тому же контроллеру, то есть серверам виртуализации SpaceVM. Таким образом, у нас было больше двух тысяч подключений, но не было взаимосвязи между этими диспетчерами. То есть на каждый диспетчер необходимо было устанавливать на клиенте список, к которому мы подключаемся. И тем самым первый свободный у нас был доступен. Нужно каким-то образом регулировать уже внутренними средствами группировки данных виртуальных рабочих столов. Т.е. в этот диспетчер у нас эта группа входит, а в этот диспетчер – контейнеризации - другая группа.
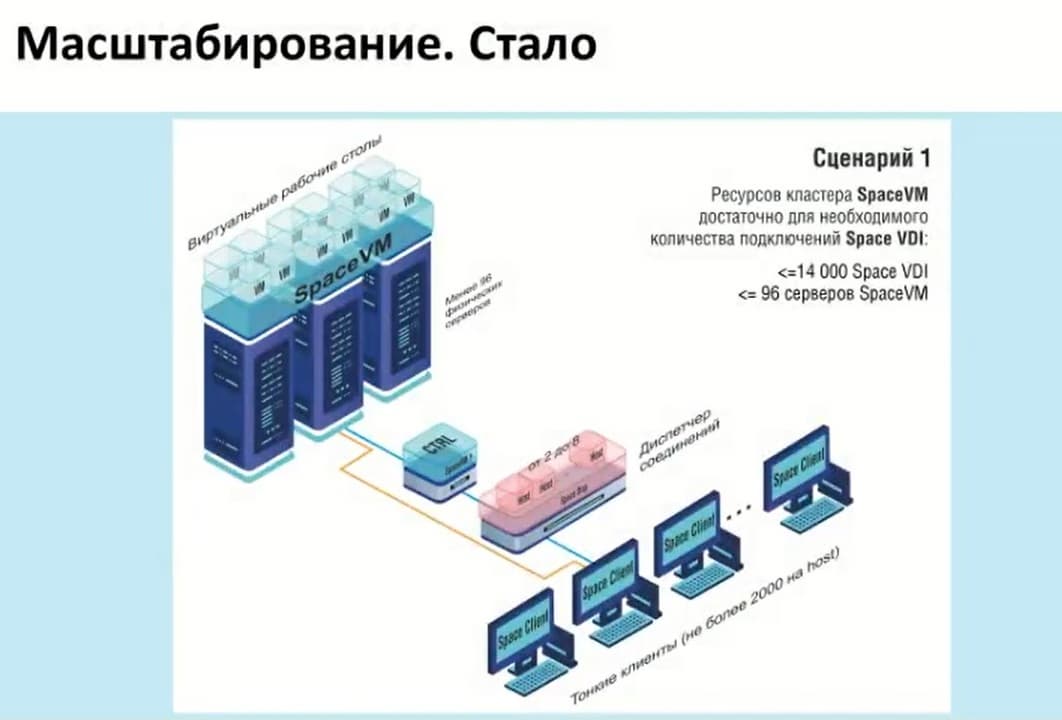
Теперь с добавлением контейнеризации, то есть мы можем предоставить до 14 тысяч подключений, и данное количество подключений достаточно для стандартного использования, мы можем уже оперировать самими пулами и группами этих пулов в зависимости от того, сколько нам необходим подключений.
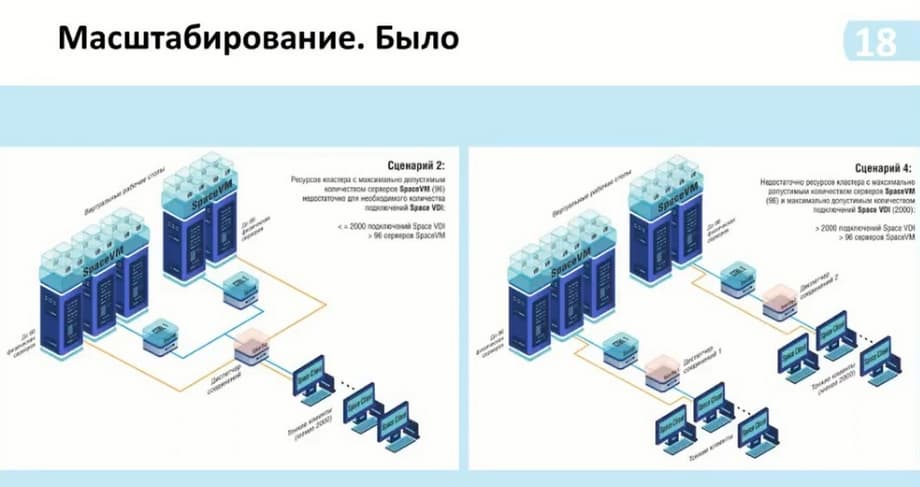
Также, в случае, если необходимо было использовать больше мощностей, если не хватало мощности одного кластера Space VM для обработки рабочих столов, или у нас были высоконагруженные моменты обработки, такие, например, как моделирование, то мы могли использовать два кластера. И тем самым под каждый кластер нам необходим был дополнительный диспетчер в случае увеличения того же самого количества подключений. Теперь мы используем также один диспетчер и можем добавлять к нему несколько кластеров. Т.е. не обязательно их должно быть два, три тоже возможно.
Далее дополнительные варианты масштабирования. Как и было ранее, диспетчер, который был в едином экземпляре, когда нужно было увеличить подключения, которые неспособно поддерживать сама часть диспетчера - брокер, мы добавляли еще дополнительный брокер.
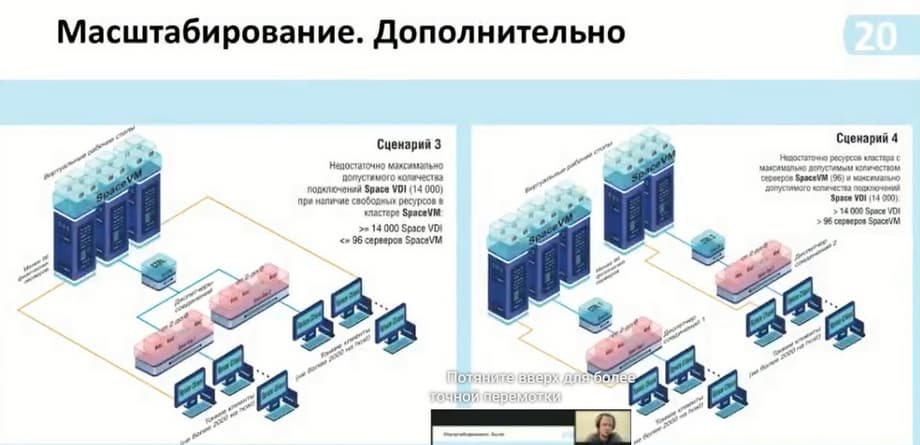
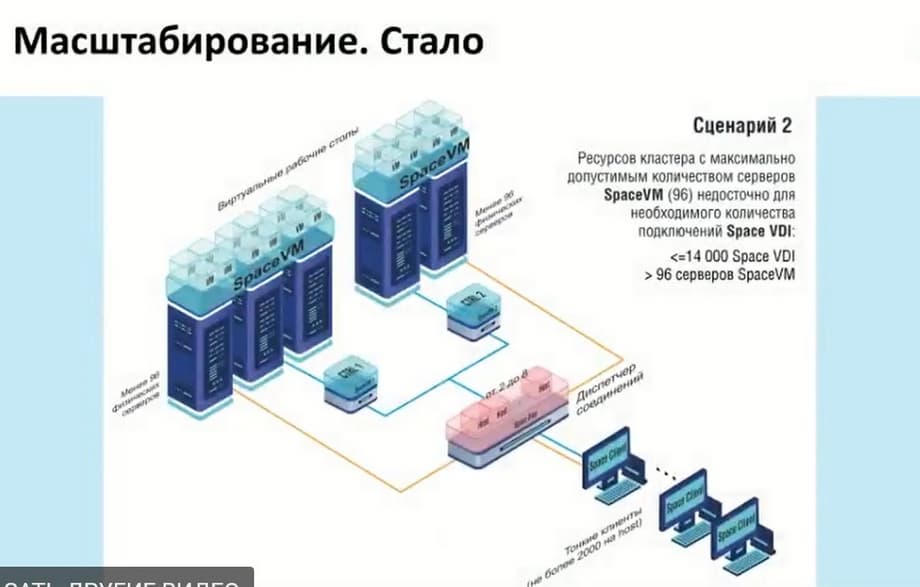
Здесь есть возможность использовать более 14 тысяч подключений, здесь подключены два мультидиспетчера к одному контроллеру. Если сам кластер позволяет поддерживать больше 14 тысяч подключений и соответственно есть возможность рассчитать данные возможности. Или, если нам нужно изолировать данные, то мы можем сделать так, как показано в сценарии 4.
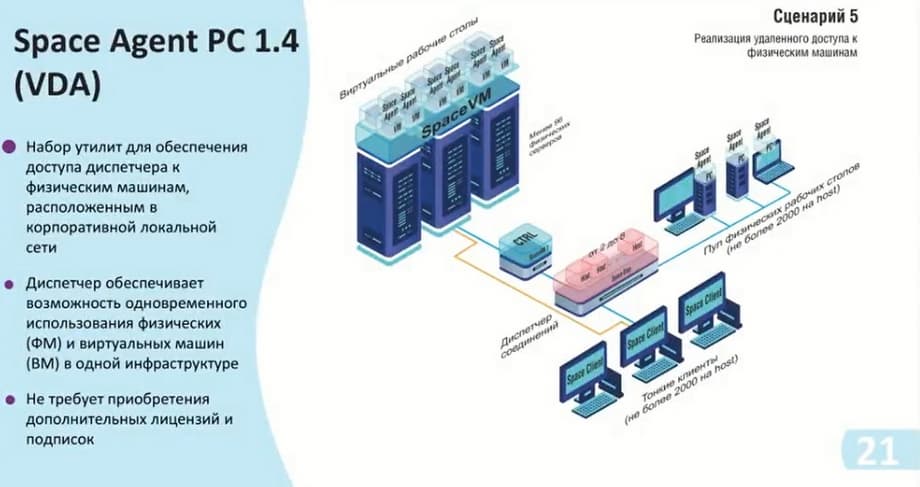
Эти сценарии у нас переработаны из сценариев релизов до 5.3. Теперь добавился дополнительный сценарий. Физический пул у нас позволяет рассчитать до 2000 клиентов на сам хост, и здесь вся прелесть состоит в том, что вы можете использовать данный диспетчер не только конкретно под какой-то функционал, т.е. виртуальные рабочие столы, либо физические рабочие столы, а именно все вместе. Например, у нас имеется 7 хостов с возможностью подключения до 14000. И мы можем их разделить либо поровну, либо как-то динамически. И тем самым у нас появляется возможность гибко настраивать саму инфраструктуру, так и экономить на самих ресурсах. То есть если нет самой мощности Space VM, которая может нам предоставить рабочие столы, но есть физические устройства, в которые мы можем предоставить доступ, то мы можем включить их в эту схему. К тому же, использование Space VM не требует дополнительной лицензий, и вы можете их использовать сразу же.

Мы сейчас используем исключительно ASRTA Linux в качестве гостевой операционной системы, и соответственно операционную систему самого стола. И для подключения рекомендуем использовать наш проект в данном случае, если необходимо использовать стандартные офисные решения. Но также оно позволяет обработать и графическую часть с трехмерным моделированием. Но если вам нужны какие-то высоконагруженные решения, с быстрыми динамическими сценами, и у вас есть хорошая полоса пропускания, то можно использовать протокол Loudplay.

Месяц назад мы выпустили решения для операционных систем именно Unix, то есть Linux систем, то есть такие как Demi, ASRTA Linux, Ubuntu, и тем самым мы уже можем использовать их и в наших решениях.
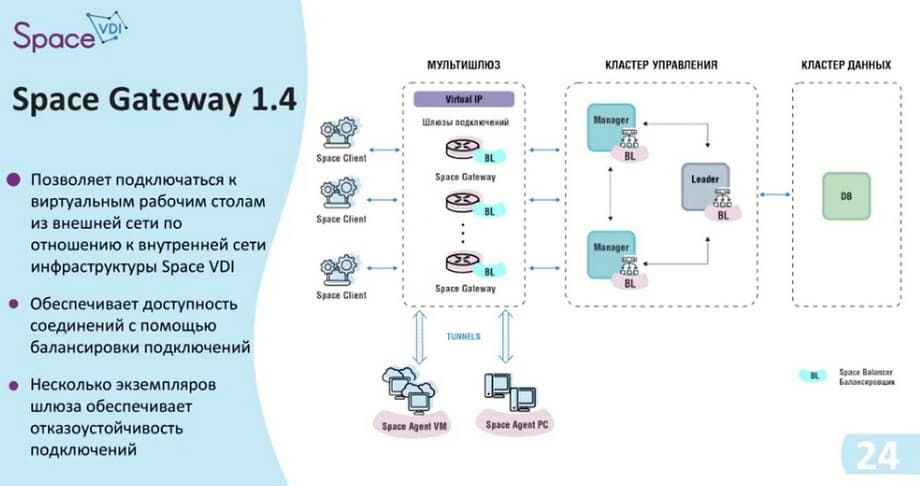
Для того чтобы мы могли безопасно выходить из Интернета, мы разработали шлюз Space Gateway. Этот шлюз ставится между самими клиентскими устройствами и диспетчером. Сам шлюз имеет возможность настраивать у себя публичный порт, и тем самым блокирует доступ к какой-то части инфраструктуры, т.е. виртуального рабочего стола или самого физического рабочего стола, создавая туннели. То есть при подключении к конкретному рабочему столу, диспетчер передает информацию о том, что требуется соединение, отправляется это соединение на шлюз, и шлюз поднимает туннель с настроенным диапазоном портов. Тем самым данные уже доходят от клиента до кластера управления.

Теперь про изменения, которые произошли при переходе от 5.3 к 5.4. Основное изменение состоит в том, что мы отказались от единственного экземпляра возможности использования самого диспетчера. Также добавили варианты логирования, такие, как интеграция с ArcSight и формат CEF. Сделана интеграция со службами каталогов сервисов таких, как ADFS, которая добавила возможности и двухфакторной аутентификации, и самоуправления со службами каталога и через данную службу. Главное изменение - это реализация по управлению пулом физических машин, оптимизация подсистем регистрации, средствами интеграции с сайта и остальными возможностями логирования. Оптимизация подсистем безопасности. Под этим подразумевается, что мы сейчас прорабатываем варианты с буферами обмена, подключением к внешним устройствам, т.е. подключением через USB таких как и сами носители, или же смарт-карты. То есть мы сейчас имеем возможность их только включать/ выключать. Доработка по поддержке различного функционала у нас будет в дальнейших релизах.
Также доработано управление парольными политиками. Здесь мы обязали пользователей сменять пароль в случае, когда администратор представляет пользователю свой временный пароль, пользователь при входе его должен поменять. Это позволяет сохранить конфиденциальность данных и, соответственно, усиливать безопасность.
Также переработали сам web-интерфейс. Улучшены читаемость и разборчивость. Были моменты, когда через протокол удаленного доступа не совсем корректно воспринимались цвета. Здесь мы тоже сделали переработку. Само количество виртуальных машин для статического пула увеличено. Было максимально возможное число 100 виртуальных машин в статическом пуле. И мы в основном рекомендовали использовать автоматический пул. Сейчас мы увеличили их до 1000 виртуальных машин. Ну и в целом с использованием мультидиспетчера мы рассмотрим вариант, увеличить его в зависимости от количества хостов.
Одно из изменений произошло именно по инверсионности. Теперь все компоненты, которые используются в диспетчере, мы будем нумеровать по минорной части. То есть, к примеру, сейчас будет версия для таких компонентов как Space Agent и Space Gateway, тоже соответственно 1.4 и 1.4. И также закончилась доработка графической части клиента Space Client.










