Мероприятие OCS и «Шаркс Датацентр», российского производителя гиперконвергентных решений, реализующего задачи по переводу ИТ-инфраструктуры ЦОД на отечественное ПО. Ключевая специализация компании – разработка системного ПО виртуализации, NFV/SDN решений, распределенных отказоустойчивых СХД. Продукты под брендом SharxDC: • SharxBase – масштабируемая программно-аппаратная платформа виртуализации; • SharxDesk – централизованная платформа виртуализации рабочих столов и приложений; • SharxStorage – распределённая, параллельная, линейно масштабируемая файловая система.
Сегодняшнее мероприятие ведет Бычков Роман, директор по развитию компании «Шаркс Датацентр».
«Шаркс Датацентр» - это российский разработчик ПО в части виртуализации и гиперконвергенции, компания на рынке с 2015 года.

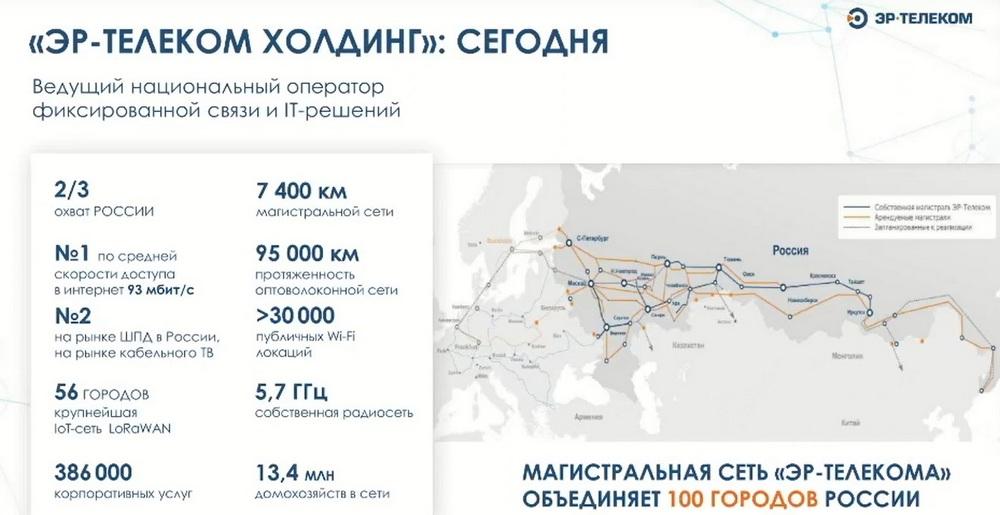
С 2022 года компания «Шаркс Датацентр» стала частью холдинга «ЭР-ТЕЛЕКОМ». Наличие такого стратегического партнера для нас является хорошим знаком и подспорьем.
Ключевой деятельностью «Шаркс Датацентр» является разработка программного обеспечения и выпуск продуктов на базе данных решений. Основным решением компании является платформа виртуализации – SharxBase и дополнительно на базе данной платформы мы можем предоставлять решение по организации виртуальных рабочих столов – SharxDesk.

С самого начала своей деятельности мы достаточно большое внимание уделяем информационной безопасности и у нас есть все необходимые лицензии на разработку от ФСТЭКа и ФСБ.

Все наши разрабатываемые продукты мы стараемся внести в реестр. SharxBase, SharxDesk и SharxStorage внесены в реестр отечественного ПО, а на решение SharxBase получен сертификат ФСТЭК на 4-й уровень доверия.

Сейчас запущен процесс сертификации по новым правилам, выпущенным ФСТЭК в конце прошлого года. Наши решения позволяют закрыть и новые требования к ИТ-инфраструктуре и соответствовать требованиям нашего законодательства.
Что касается импортозамещения, то при продаже ПАКов мы предлагаем решения как на базе именно ПО, а чтобы закрыть аппаратную составляющую мы достаточно плотно сотрудничаем с различными российским вендорами аппаратного обеспечения для того чтобы выпускать законченное решение. При этом сервисная поддержка таких ПАКов осуществляется нашей компанией с 24/7 с критическим временем реакции 4 часа для важных критических систем.

Среди партнеров по аппаратным средствам можно выделить 3 компании: «Ядро», «Аквариус» и «Крафтвей». С ними пройден полноценный цикл тестирования их аппаратных платформ и имеем достаточно плотный контакт с их группами разработки.

SharxBase – это гиперконвергентное решение, которое объединяет в себе виртуализацию вычислительных ресурсов, так и ресурсов хранения. За счет архитектурных особенностей система не имеет единой точки отказа и предназначена для создания различных инфраструктур, которые должны обеспечивать высокопроизводительное и высокодоступное инфраструктурное решение для запуска различного рода информационных систем.
Основными кейсами являются решения по созданию инфраструктуры виртуализации, которая может позволять создавать различные виртуальные ЦОДы или виртуальные платформы. С учетом создания виртуальных ЦОДов мы можем реализовывать эту платформу в мультитент варианте, когда для различных отделов, департаментов или структур в рамках большой компании мы можем выделять пулы ресурсов, к которым доступ будет предоставлен только ограниченной части лиц. За счет того, что система построена на базе современного оборудования с использованием SSD-накопителей, мы можем говорить о том, что данные архитектуры замечательно позволяют обеспечивать функциональные возможности для запуска различных кластеров аналитики и высоконагруженных баз данных.
Следующим кейсом является использование мультитент, что позволяет реализовывать частные либо публичные облака. И такие кейсы в нашем портфеле тоже есть. За счет использования средств SharxBase на платформе можно реализовывать полноценную инфраструктуру VDI со всеми преимуществами в виде использования «золотых образов» и оркестрации всего этого процесса. И наличие ФСТЭКовских сертификатов позволяет создавать необходимую инфраструктуру для объектов критической информационной инфраструктуры.
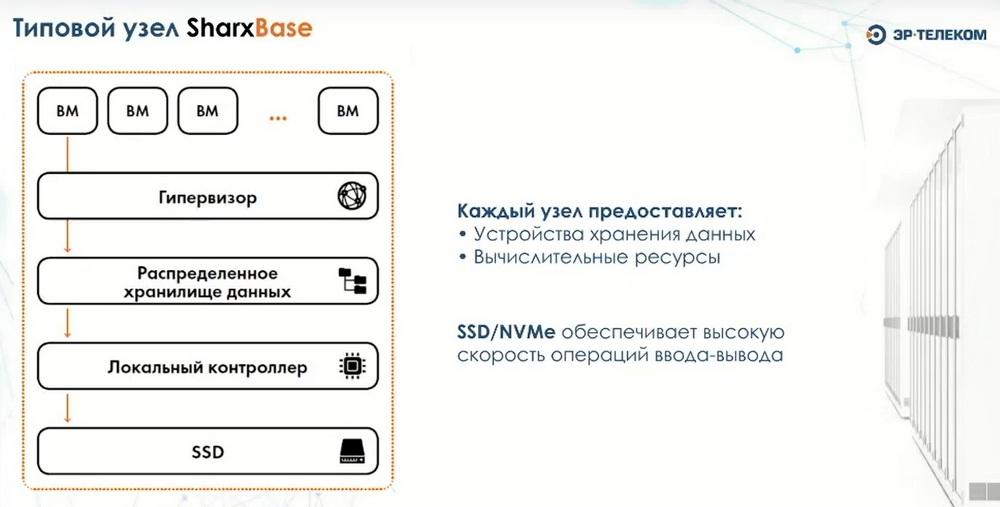
У нас есть три продукта: SharxBase, SharxDesk и SharxStorage. Ключевым нашим продуктом является SharxBase. SharxBase это серверная платформа. Здесь используются серверы х86 архитектуры. Причем предпочтение на текущий момент отдается серверам российского производства, которые входят в Реестр. Но, при необходимости, могут использоваться и другие решения. У нас есть партнеры, с помощью которых мы реализуем это на серверах китайского производства. И, если у заказчика нет потребности в использовании ресурсов, входящих в Реестр отечественного ПО. Платформа используется X-86 с поддержкой процессоров как Intel, так и AMD. Архитектура сделана так, что в каждом узле у нас установлены SSD-накопители для организации распределенного хранилища путем объединения в единый кластер. Отдельно устанавливаются загрузочные устройства, на которых устанавливается сам гипервизор, и который используется для хранения различных служебных данных. Далее устанавливаются ОС и наше ПО, и затем реализуется весь функционал платформы управления. Архитектура является легко масштабируемой и минимальный блок, с которого мы рекомендуем начинать, включает в себя 4 узла.
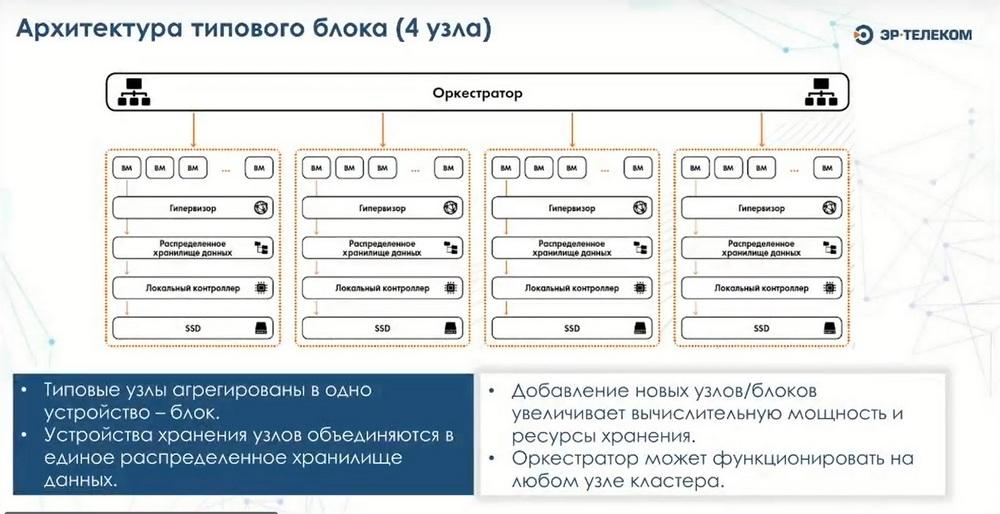
В этом случае мы имеем 4 абсолютно идентичных узла, имеющих одинаковую аппаратную конфигурацию для того, чтобы обеспечить отсутствие единой точки отказа. У нас написано кластерное ПО, которое позволяет обеспечивать отслеживание живучести всех узлов, состояние всех критически важных сервисов. В свое время мы активно смотрели в сторону различных open sourсe продуктов, но в результате мы отказались от их использования по причине наличия большого количества кластерных компонент. И все это сильно утяжеляло конструкцию и делало ее ненадежной. Написанное нами ядро исключает все узкие места, которые имеются у этих продуктов за счет того, что оно написано на языках функционального программирования, которые в своей основе имеют все необходимые функции кластеризации. И тем самым мы на уровне архитектуры исключили проблему, связанную с поддержкой кластеров.
Для расширения функциональности у нас есть распределенное хранилище, которое запускается в виде сервиса и представляет блочное устройство внутри виртуальных машин, которые могут запускаться на самих физических узлах. Для этого мы внутрь этого распределенного хранилища отдаем все SSD-накопители, которые установлены в серверах, и на их базе осуществляется единая логическая сущность. Для защиты данных у нас используется механизм тройной репликации. И механизм записи идет на все узлы. Т.е. каждый блок данных записывается на три произвольных узла, на три произвольных жестких диска. Это нам позволяет исключить вариант, когда может выйти из строя один любой сервер или даже два, любой жесткий диск, и при этом данные пользователя всегда будут оставаться доступными и виртуальные машины будут функционировать.
Для оркестрации запускается отдельный сервисный контейнер, в котором есть интерфейс управления, и он имеет определенное состояние, т.е. внутри самого сервер-контейнера с оркестратором у нас нет никаких служебных данных. Они сохраняются тем же методом, что и пользовательские данные на распределенном хранилище. В этом случае при выходе из строя любого из узлов, сервисный контейнер может быть перезапущен на абсолютно любом узле. И функциональность среды управления будет восстановлена в кратчайшие сроки. За счет того, что система является горизонтально масштабируемой, мы можем на лету как добавлять узлы, так и исключать узлы из состава кластера. Это позволяет добиться легкой масштабируемости и расти по мере возникновения потребностей. Поэтому я утверждаю, что минимальной рекомендуемой конфигурацией являются 4 узла, из которых можно будет вырастить большую инсталляцию.
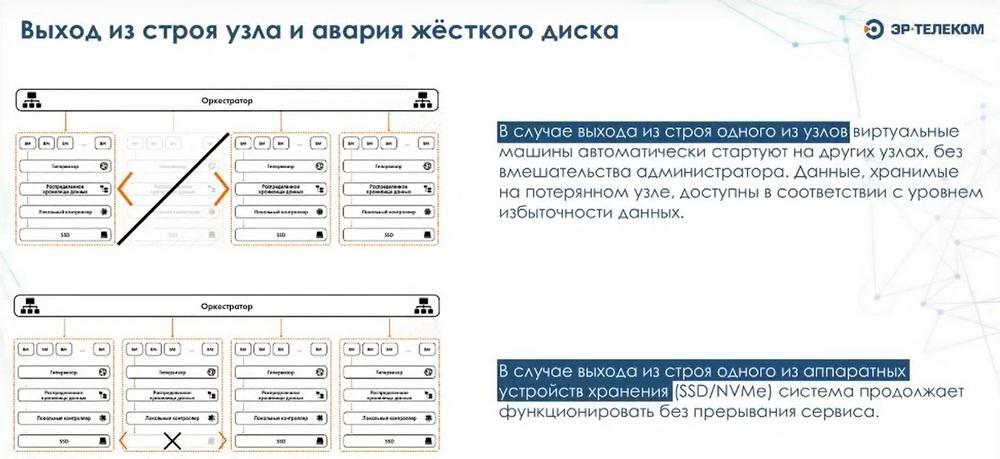
Мы используем механизм трехкратной репликации данных. Это позволяет исключить такой вариант, когда выход из строя любого узла приведет к недоступности какой-либо функциональности. Функциональность в любом случае сразу будет восстановлена, и у нас нет никаких сервисов, которые запущены в единственном экземпляре на каком-либо узле, и являются прикрепленными к ним. Для подключения жестких дисков нам не нужен RAID-контроллер, мы можем использовать FBA, и они пробрасываются напрямую. Нам не нужна организация RAID на уровне аппаратного контроллера.
Четыре сервера являются рекомендуемой конфигурацией для того, чтобы начать строить кластер. Но минимальной доступной конфигурацией является конфигурация из трех узлов. И тут есть единственное ограничение, что в случае выхода из строя одного из узлов, система будет продолжать работать, но мы не сможем создавать новые виртуальные машины до тех пор, пока мы не введем в эксплуатацию третий узел. Потому что мы не сможем обеспечить тройную запись на три различных сервера. Для существующих виртуальных машин функционирование будет обеспечено и данные будут записываться. После ввода в эксплуатацию третьего узла после аварии, данные будут синхронизированы и функциональность будет восстановлена в полном объеме.
Контейнерные сервисы запускаются автоматически в случае выхода одного из узлов, и это как раз является функцией кластерного ПО. В случае выхода из строя одного из серверов, система отслеживания живучесть физических узлов определяет что физический сервер является недоступным, пытается его реанимировать. Если же нет возможности его реанимировать, то в этом случае все виртуальные машины, которые были запущены на этом сервере, будут в автоматическом режиме перезапущены на других узлах. Весь перезапуск осуществляется тоже в автоматическом режиме.
В случае выхода из строя жесткого диска, мы его заменяем и запускаем процедуру ребалансировки данных для того, чтобы восстановить четность для тех данных, которые были на вышедшем из строя диске. В случае добавления нового узла в кластер, диски добавляются и в пул хранения и сразу же становятся доступны для размещения на них пользовательских данных. В случае вывода из строя узла, предварительно выполняются сервисные процедуры, которые говорят о том, что данный узел будет выведен из строя, данные с него релоцируются, и делается третья копия данных на других узлах. И после завершения этой процедуры, этот узел спокойно удаляется из состава кластера.
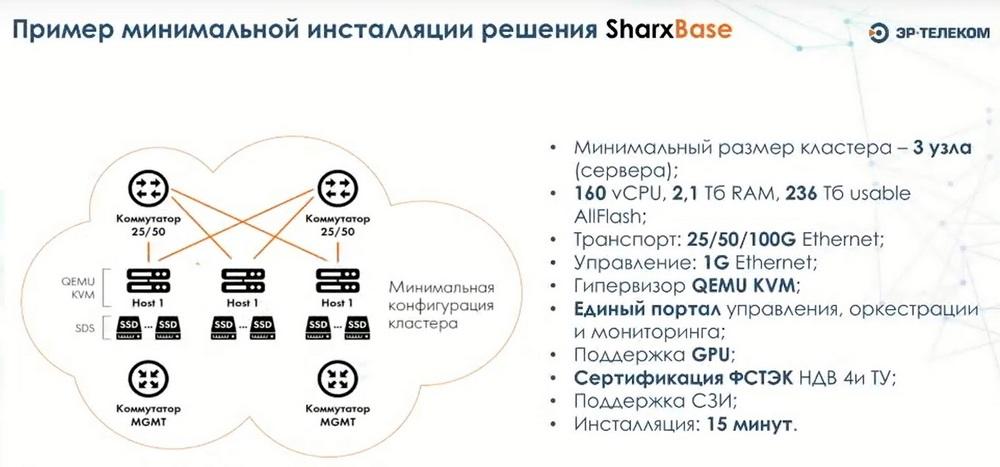
На примере минимальной инсталляции, видно, что конфигурация должна включать в себя три узла, три сервера. В этом случае, в зависимости от аппаратной конфигурации можем получить до 160 виртуальных ЦПУ, 2 Тбайта оперативной памяти и 23 Тбайта доступного дискового пространства.
Для обеспечения сетевого интерконнекта используются две сети. Первая сеть передач данных построена на базе коммутаторов 25 Гбайт/с и выше. Это рекомендуемая конфигурация. В том случае каждый из узлов подключается линками в каждый из коммутаторов. Далее есть выделенная сеть управления, к которой подключены все IBI интерфейсы и которая используется для отслеживания корректности функционирования хостов и их живучести. Потому что мы можем выводить узлы в обслуживание, либо узел может по каким-либо причинам перезапуститься, но после этого он самостоятельно автоматически поднимается и становится доступным. Если узел вышел из строя и он недоступен в течение определенного периода времени, который является настраиваемым (по умолчанию это 3 минуты), то после этого машины начинают запускаться на других узлах кластера. Т.к. у нас хранилище является распределенным, то все данные вне зависимости от того, вышел из строя узел, доступен ли он или нет, все данные являются доступными, и машина может быть запущена на любом физическом узле, на котором для этого будут доступны ресурсы.
Если на этом узле был запущен управляющий сервис, т.е. имел VIP-адрес для управления, то этот сервисный контейнер будет кластерным софтом перезапущен на другом узле с сохранением своего VIP-адреса, и функциональность кластера с точки зрения управления будет обеспечена достаточно оперативно.
ГПУ нами тоже поддерживается. Мы тестировали это дело с акселераторами от MIDI. Единственный вопрос, который остался, это то, каким образом нам получить и активировать лицензию. Есть возможность использования различных обходных путей, но с точки зрения конфигурации все это поддерживается, работает, и мы проводили тесты совместно с продуктом «Компас-3D» по созданию инфраструктуры для удаленной работы конструкторов. Мы запускали машину через VDI, в которую были проброшены видеокарты. С помощью драйвера они сплетились на определенное количество виртуальных карт, и конструкторы спокойно работали в режиме виртуальных рабочих мест, удаленного подключения к ним. И выполняли при этом все необходимые функциональности.
Даже в самом минимальном решении от трех узлов вы сможете получить сертифицированное решение. Для сертифицированного решения при продаже мы отдельно специфицируем сертифицированный дистрибутив со всеми комплектами необходимой сопроводительной нормативной документации и отдельно сертифицируется поддержка для сертифицированной версии.
Как заявлено, мы работаем с различными средствами защиты информации. Для того, чтобы корректно работать и можно было бы полностью создавать конечную информационную систему, потребуется установка модуля загрузки. На текущий момент - это «Соболь».
С точки зрения СЗИ мы активно работаем с различными производителями средств ИБ, т.е. это «Код безопасности», это «Инфотекс», это Positive Technology. Также протестированы продукты и выпущены соответствующие сертификаты совместимости.
Инсталляция является автоматизированной, и при правильной начальной конфигурации сети занимает непродолжительное время. Она не очень зависит от количества узлов в кластере, потому что процедура запускается одновременно на всех узлах. Минимальное время, которое у нас было от выхода на площадку до получения готовой системы, включая монтаж, инсталляцию и прочие вещи, занимало 2 дня.
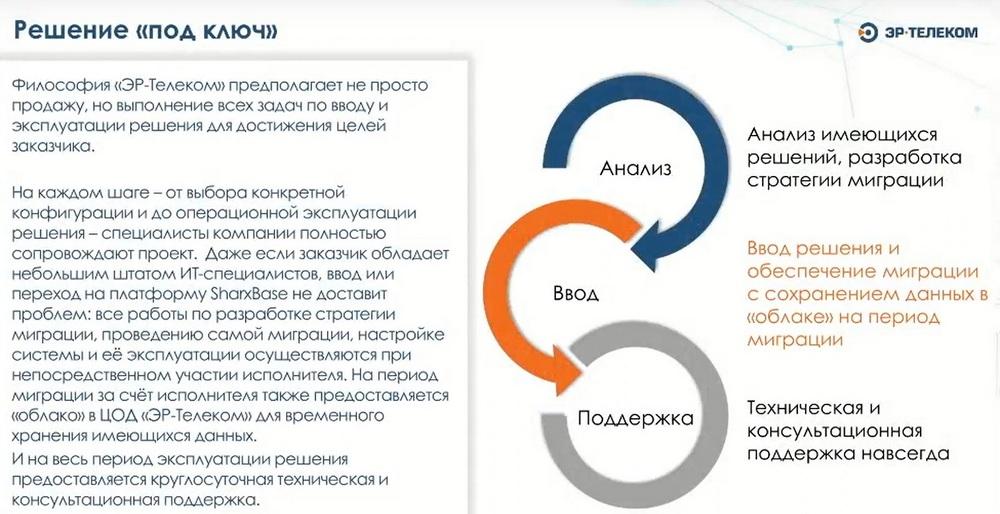
Мы, с помощью нашего ПО и ПАКов, выпускаемых на базе нашего ПО, готовы предложить клиентам и интеграторам решение «под ключ», мы им готовы оказывать консультации и услуги по проектированию инфраструктуры на базе наших решений и помогать в имплементации этих решений. Мы можем дополнительно предлагать решения по подготовке документации и по процедурам инсталляции. Процедуру инсталляции мы всегда включаем в базовый пакет при продаже. Далее клиент сам решает, либо они будут делать инсталляцию сами, но мы рекомендуем делать инсталляцию силам наших инженеров. В большинстве случаев она производится удаленно, и никаких вопросов не вызывает.
Техническая поддержка, которую мы предлагаем, может быть вплоть до 24/7. Но самый минимальный пакет регистрации обращений в режиме 9/5 в рабочие дни, в дальнейшем это может быть поднято до уровня 24/7 со временем реакции 4 часа. Стандартный пакет - это реакция 24/7 на приоритеты 1-2 уровня, т.е. когда система либо полностью недоступна, либо наблюдается сильная просадка производительности. Во всех остальных случаях вопросы консультационного характера или какие-то небольшие проблемы и изменения регистрируются 24/7, но реакция на них осуществляется в режиме 9/5.
О файловой системе. Мы предоставляем блочное хранилище, а файловая система это та, которая поддерживается вашей ОС.
С точки зрения поддержки различных ОС, мы верифицировали и инсталлировали практически все российские Linux. С большинством из них мы получили сертификаты совместимости, они присутствуют на нашем портале.
С точки зрения корректности функционирования Windows тоже все хорошо. Внутрь всех виртуальных машин мы для корректности работы с ними устанавливаем тему Gestogen для более плотной интеграции с системой управления и возможностью управления для виртуальных машин.
Процесс обновления ПО осуществляется достаточно просто, т.е. в процессе обновления не производится прерывание сервисов. Обновление происходит постепенно по узлу, и в этом случае машины мигрируют на другой узел, узел обновляется, машины на него возвращаются, и происходит периодичный upgrade по узлу. Это обеспечивается как на уровне системы хранения, так и на уровне ПО управления.
С точки зрения компрессии и дупликации на уровне хранилища этого функционала нет. Здесь поддерживается тонкое выделение всех дисковых домов с точки зрения компрессии, «дедупа» нету. Тип репликации может настраиваться. Мы все прекрасно понимаем, что выход оборудования из строя может происходить время от времени, а также у нас система требует с точки зрения грамотной эксплуатации периодического обслуживания сервера. Если мы в произвольный момент времени выведем сервер в обслуживание, а в этот момент что-то где-то сломается, то мы этого не хотим. Мы хотим гарантировать клиентам, что все их данные и все информационные системы будут продолжать работать и система будет стабильна. Поэтому мы для продажных систем используем фактор 3.
Для перевода в режим обслуживания есть соответствующие галочки в интерфейсе управления, которые позволяют переключить сервис в этот режим. Это нам позволит не размещать новые машины на этом хосте. И перенос машин, а функциональности этих существующих виртуальных машин существующие узлы зависит от размера и интенсивности работы с данными. Как правило это занимает 10-20 минут.
По поводу GPU. На текущий момент у нас нет динамического релоцирования. В любом случае, если мы видим наличие свободных ресурсов на карте, которые могут запустить данный профиль, то это может быть запущено.
160 виртуальных ЦПУ, все зависит от тех типов процессоров, которые есть. Если использовать процессор с большим количеством ядер и делать большую подписку, мы можем получить в принципе и большее количество ЦПУ. Но это приблизительная характеристика.
С точки зрения подключения к VDI мы используем соответствующие стандарты для подключения к машинам Windows и к машинам Linux. У нас нет своего разработанного протокола потому, что это сложная инженерная работа, она стоит у нас в планах, но пока не реализована.

Учитывая историю нашей компании, мы тесно были связаны с транспортной отраслью, здесь приведено несколько кейсов, которые были реализованы с использованием нашего ПО, и работают уже не первый год. Самый крупный реализованный проект - это «Создание инфраструктуры для создания центральной кольцевой автодороги». Все, что обеспечивает взимание платы, обеспечение функционирования информационных систем, отвечающих за безопасность дорожного движения, все функционирует на базе платформы. И за счет того, что инфраструктура должна работать непрерывно, и, в случае выхода из строя основного ЦОДа, обеспечивать перенос информационных систем на другую площадку, использование нашего решения позволило достичь всех этих целей.

Мы можем делать cкриншоты и относить их на вторую площадку, т.е. вместе со скриншотом у нас относится вся метаинформация, относящаяся к виртуальной машине и на второй площадке, в случае выхода из строя, оператор принимает решение о том, что необходимо запустить эти сервисы, они могут быть запущены на второй площадке. Т.е. эта цель намеренно сделана в не автоматическом режиме функционирования, потому что решение о переносе должен принимать оператор в соответствии с тем планом, который есть у него в рамках его организации. Это все-таки задача, которая связана с консалтингом, т.е. она не относится к инфраструктуре, но технологически мы это поддерживаем и можем обеспечить. За счет того, что мы можем обеспечить горизонтальное масштабирование в случае увеличения нагрузки на дорогу или подключения дополнительных участков кластеры могут быть расширены без прерывания функциональности и все будет обеспечиваться.
Один из заказчиков из органов госвласти Самарской области использовал инфраструктуру нашей платформы для создания защищенного контура информационных систем и переноса туда различных систем, требующих аттестации. Туда был поставлен минимальный парк из 4 узлов. Благо потребность в ресурсах была не слишком большая. Но со всеми необходимыми условиями по непрерывности процесса миграции и по минимизации недоступности информационных сервисов и последующей аттестацией этих информационных систем.
Есть еще истории, где используются наши решения. На базе Транстелекома была сформирована платформа транспортно-логистических сервисов, которая работает по облачной модели в режиме гибридного облака. Т.к. часть этой инфраструктуры Транстелеком использует для своих нужд, а часть использует для предоставления клиентам. Дополнительно был большой проект по созданию системы трансграничного отслеживания перевозок и грузов, все эти проекты работают уже более 5 лет, и система подходит к очередному циклу своих обновлений.