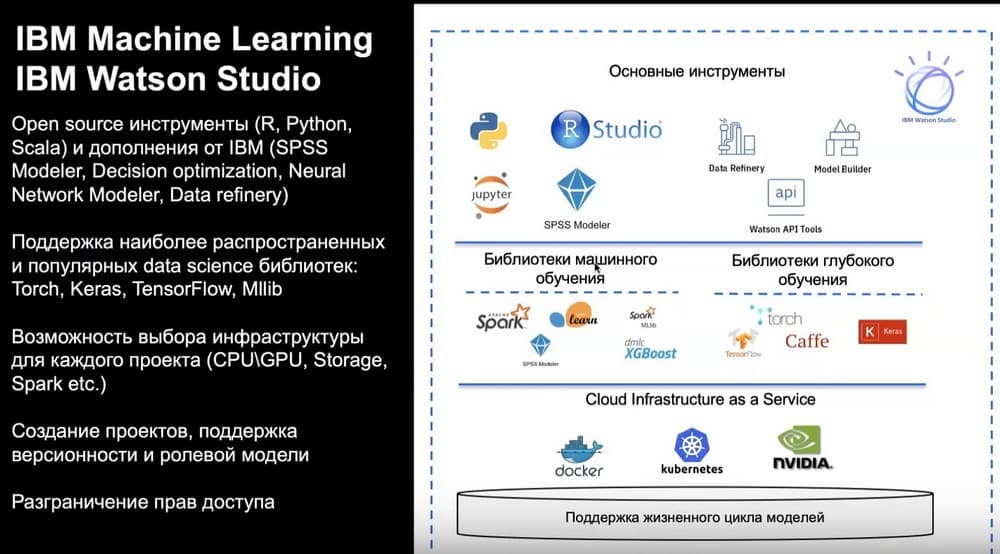
Сегодня речь пойдет об IBM Cloud Pak for Data, который закрывает всю функциональность работы с данными аналитики, состоящих из продуктов раздела продуктового портфолио IBM. А там внутри располагается Red Hat Open Shift, который связывает все во единое и работать с Kubernetes для оркестрации контейнеров и вызовов между ними, чтобы эта платформа стала уровня Enterprise. IBM Cloud Pak for Data – это все то что связано с аналитикой данных, обработкой и хранением данных, конвертацией и их управлением.
На этом мероприятии вы узнаете тонкости работы с комплексным решением IBM, которое объединяет данные, инструменты и специалистов. IBM Cloud Pak for Data упрощает и автоматизирует сбор, организацию и анализ данных и внедрение искусственного интеллекта в масштабе всего предприятия. Решение органично сочетает в себе богатый комплекс программного обеспечения для работы с данными и ИИ, современные средства управления и обеспечения безопасности, а также предоставляет унифицированный интерфейс для эффективной совместной работы.

Сегодняшнее мероприятие ведет Роман Шемпель, Partner Sales Manager из компании IBM.
По словам Романа, IBM конвертировал продуктовое предложение в портфолио продуктовых решений в области ПО, конвертировал в понятные технологические доменные продукты и назвал их Cloud Pak. В этом термине слово Cloud не означает SaaS, не означает публичного облака, оно в этом контексте – имя собственное (название продуктовой линейки), здесь не говорится о какой-то технологии или инструменте, здесь скорее говорится о потенциальной возможности развертывания решения там, где заказчику удобно, потому что решение контейнеризовано и реализовано с использованием микросервисной архитектуры.

Если заказчик хочет его развернуть на другом сервере, в другом контуре, в другой инфраструктуре, в партнерском контуре или переместить его в публичное облако, то это будет значительно легче сделать, поскольку, повторимся, решение контейнеризовано и разработано с использованием микросервисной архитектуры. Именно поэтому Cloud – это потенциал переноса этого решения в другую среду.
Это продуктовое портфолио включает в себя пять десятков продуктов, они разбиты на функциональные домены: домены интеграции, домены автоматизации бизнес-процессов, домены аналитики и работы с данными. И все это множество продуктов объединили в один пакет – Pak.
Сегодня речь пойдет об IBM Cloud Pak for Data, который закрывает всю функциональность работы с данными аналитики, состоящих из продуктов раздела продуктового портфолио IBM. А там внутри располагается Red Hat Open Shift, который связывает все во единое и работать с Kubernetes для оркестрации контейнеров и вызовов между ними, чтобы эта платформа стала уровня Enterprise.
Функциональные домены

IBM Cloud Pak for Data – это все то что связано с аналитикой данных, обработкой и хранением данных, конвертацией и их управлением. Все что связано с автоматизацией и цифровизацией предприятий, начиная от сканирования и распознавания, создания электронного архива, автоматизацией бизнес-процессов, дополнения сотрудников на рутинных операциях, внедрения автоматизированных бизнес-правил.
Все что является прямым наследником Tivoli и Netcool, мониторингом приложений, все это сегодня агрегировано в Cloud Pak for Watson AIOps.
Все что связано с интеграцией, когда одну сущность нужно подружить с другой сущностью или множеством сущностей, при этом не важно где они находятся, внутри вашего контура или же во вне – это все Cloud Pak for Integration. Тут и внешний API, оркестрация передачи транзакционных данных по различным протоколам. Cloud Pak for Network Automation – он специфичен для мониторинга сети операторов связи.
Все что связано с портфолио кибербезопасности - это Cloud Pak for Security. Роман Шемпель в компании IBM отвечает за все, кроме Security.
IBM Cloud Pak for Data
Сегодня речь пойдет о Cloud Pak for Data. Это физически реально один интерфейс пользователей вне зависимости от того, какую роль этот пользователь выполняет. Начиная от базового администрирования источника хранения данных до бизнес-приложений.

Работа с данными и последующая аналитика – это всегда процесс поступательный, который можно визуализировать в виде иерархии, ступеней data-driven, когда компания от того чтобы хранить приходит к тому чтобы организовывать хранение, а потом и анализировать. Ступень Infuse – это более практичная плоскость применения бизнес-приложений.
Если есть желание на практике применять инструменты ИИ, анализ данных, все равно нужно организовывать весь ландшафт систем хранения данных, операционный уровень работы с данными, который связан с Organize и Collect.
Если более сфокусированно подойти к каждому из элементов этой лестницы, то Collect – это все что связано с работой с источниками, здесь подразумевается виртуализация данных в смысле присоединения к источникам данных. Если вы не можете ими управлять потому что у вас инструмент управления данными от одного производителя, а источник – это гетерогенная инфраструктура от другого производителя, тогда для того чтобы вам агрегировать это на каком-то уровне, чтобы иметь единое представление, то виртуализация данных – это для вас связь с источниками сторонних производителей. Присоединение осуществляется посредством плагина на стороне источника, откуда можно из единого окна прозрачно видеть какие данные хранятся, как они организованы, в какой модели, как называются колонки, строчки и т.д. Все это предоставляет возможности из единого пользовательского интерфейса иметь доступ к источнику данных, не зависимо от роли, которую исполняет тот или иной сотрудник в компании.
Предоставление собственных баз данных, работа с партнерскими базами данных, возможность работать с инструментами Apache Spark и аналитика в режиме реального времени. Для этого у вендора есть собственные инструменты, когда по определенным правилам из потока данных нужно выдернуть те или иные данные для онлайн аналитики.
Вторая ступень или второе звено в этой цепи – это возможность организации работы с данными или управление ими. Мы отслеживаем трансформацию, профилирование данных, когда задаются параметры качества данных, мы смотрим за тем как из одной точки в другую точку данные мигрируют и задаем определенные правила миграции. Смотрим какие данные нужны, с какими параметрами, мы задаем единые правила и политики работы с данными внутри организации, каталогизируем данные. Также здесь есть Self-service инструменты по поиску и исследованию данных.
Конечный результат хранения данных – это анализ, за которым стоят управленческие решения, влияющие на бизнес и его развитие. Это отчетность, которая выполняется с помощью собственных инструментов Cognos BI (IBM Cognos Business Intelligence – комплексное решение для создания информационно-аналитической системы в масштабах всей компании. IBM Cognos BI дает возможность построения аналитических отчетов, сводных информационных панелей и карт показателей с использованием всех бизнес-данных компании). Здесь же инструменты различного оптимизационного моделирования, модели машинного обучения.
Здесь нельзя не сказать и про общие сервисы, которые помогают оркестрировать работу всей платформы и с точки зрения управления доступом пользователей, диагностики, бэкапа и миграции, мониторинга, логирования, это все то, что обеспечивает Red Hat Open Shift. Причем Red Hat Open Shift лицензионно включен в IBM Cloud Pak for Data и отдельно лицензировать его в Red Hat не нужно, но это накладывает определенную специфику на аппаратную часть, аппаратная инфраструктура потребует дополнительный мощностей именно для Red Hat Open Shift. И поддержку этого продукта осуществляет компания IBM.
Теперь имеет смысл пройтись по каждому из компонентов. Начнем с Organize. Этот продукт очень востребован на рынке.

История с IBM Data Governance или Data Operation переживает своеобразный ренессанс. Если лет 5 назад этот класс решений был доступен скорее только крупным и финансовым организациям, потому что они жестко зарегулированы, к ним могли прийти фискальные органы и найти несоответствие в каких-то параметрах данных, которые касаются финансовой отчетности, это было бы чревато для них семизначными суммами в долларах, то понятно почему они внедряли такие решения, тратили на это семизначные суммы, чтобы просто купировать эти риски.
Сейчас Data Governance опускается до уровня средних компаний. Если есть желание заниматься продвинутой аналитикой, оседлать энтропию данных, когда источников много, они от разных производителей, вам нужно из одного окна ими управлять и не тратить большие операционные средства на огромную команду, потому что это не целесообразно. Или ограничивать себя в выполнении тех или иных задач, потому что нет возможности позволить такую команду и решать такие операционные задачи. Именно здесь инструменты Data Governance помогают даже средним компаниям. Да и цена внедрения и стоимость решения по сравнению с тем, что было несколько лет назад, становятся подъемными даже для средних компаний.
Это дает возможность управления разными данными, с точки зрения их модели, структуры данных, источников, колен трансформации, уровней агрегации, мест хранения. Получать единый взгляд на данные, как они правильно называются, кто задает эти названия, где соответствие буквенно-цифровому значению, которое присвоено этой табличке IT-администратором. Ему все равно что там внутри, ему главное назвать по каким-то параметрам и атрибутам и как все это называется с точки зрения бизнеса.
Это отчет по клиентам за определенный период времени, стандартизация данных, выстраивание иерархии хранения данных, выстраивание логической и физической модели. Для того чтобы в конце концов подготовить данные для отчетности, для прогнозного моделирования, оценки вероятности, чтобы принимать верные управленческие решения. Для того, чтоб вероятность совершения ошибки при принятии решения для бизнеса минимизировалась.
Смежные подразделения хранят у себя свои отчеты, потом их пытаются соединить и представить наверх недостоверную информацию, невозможно проследить происхождение данных, сделать анализ, как то или иное значение было сформировано в отчете. Для инструментов продвинутой аналитики невозможно сформировать такую витрину данных, в которой не будет пробелов, чтобы модель не «поехала», чтобы точность прогнозов увеличилась. Вот для этого как раз и нужен IBM Data Governance.
Если раньше это был инструмент специфичный для IT-подразделения, где работают люди, ответственные за организацию работы с данными, то сейчас весь бизнес хочет туда «ходить», сотни сотрудников хотят знать индексацию тех или иных терминов, сущностей внутри таблиц. IBM Data Governance это обеспечивает.

Теперь эта концепция называется DataOps, здесь осуществляется связка от хранения, управления данными через их очистку и работу с данными по определенным параметрам, в частности посредством Master Data Management, т.е. интеграции и репликации данных. И в конце концов приходит Self-Service Iteration для подготовки и тестирования данных, когда самим пользователям, при создании отчетов не нужно заказывать те или иные данные, они это делают самостоятельно.
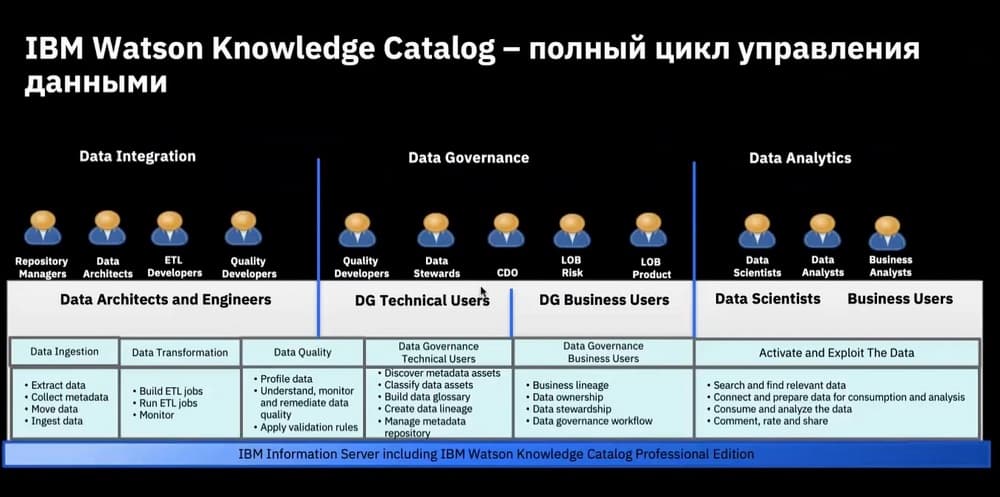
Здесь образуется единый интерфейс, в котором сотрудники работают на одной платформе, где все реализовано на базе контейнеров.
Для тех, кто управляет данными, т.е.CDO, им видны все эти отчетности, все для них прозрачно. Блок Master Data Management он пока не входит в IBM Cloud Pak for Data.
Последняя ступенька в иерархии данных – Collect. По этой «ступеньке» у IBM есть собственные инструменты для развертывания, есть возможность виртуализации данных, когда происходит подключение к источнику вне зависимости от их производителя и достаточно прозрачно видно, что у них есть.
Следующая ступенька Analyze. Рассмотрим модели машинного обучения, которые выявляют вероятности, ищут неочевидные взаимосвязи.
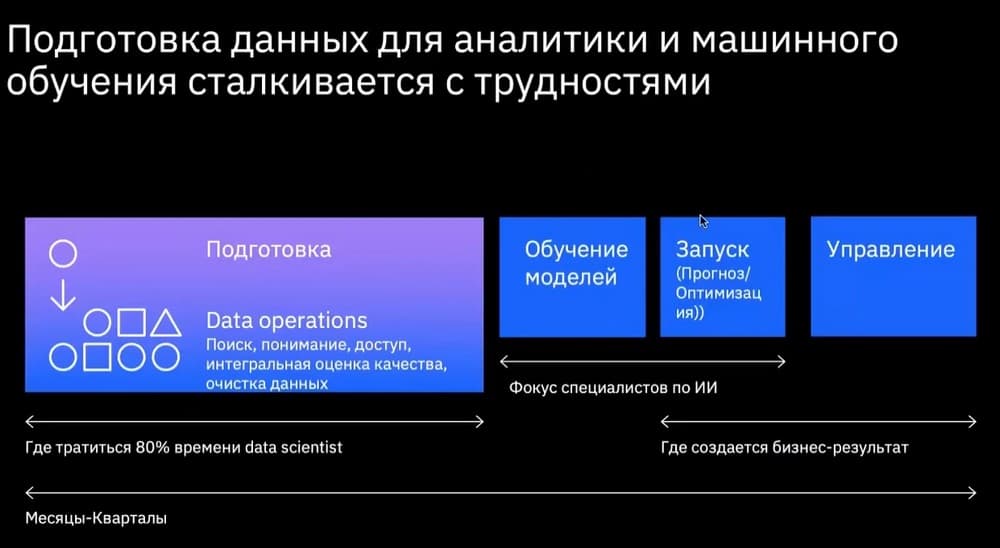
Проблема с моделями машинного обучения заключается в следующем. Те, кто пошел по этой стезе, научился делать эти модели, нанял программистов, платит им по 400 000 рублей в месяц. Множатся модели, множатся программисты и все с этим уже наигрались. А проблема в подготовке данных, чтобы данные не руками собирать, а было бы единое целостное решение, отвечающее требованиям рынка.
Приходит бизнес-сотрудник и говорит: «Хочу прогноз на вот эту маркетинговую кампанию». Аналитик трансформирует это в понятный язык для математика и специализированного программиста. Программист требует данные, на которые он хочет натравить такую-то модель с такими-то алгоритмами. Потом data-инженер идет и смотрит в каких источниках они хранятся, потом их собирает в витрину и отдал программисту, тот делает модель, ее опробует, отдает аналитику, тот интерпретирует полученные данные и хочет изменить определенные параметры поставленной им задачи, значит все пошло на второй круг, а два дня прошло... И вот этим всем надо управлять…
Таких задач – десятки, моделей – десятки, людей, которые этим занимаются – десятки, все это надо администрировать: подготавливать данные, изучать модели, запускать модели, писать отчеты по этим моделям, но эти сотрудники должны работать с понятным и прозрачным инструментом. Как раз это все обеспечивает IBM Cloud Pak for Data. Если есть желание с помощью этого инструмента управлять энтропией данных, пожалуйста, можно и так. Хотите работать не с программистами, а с математиками – пожалуйста.