Если посмотреть на процесс развития ИТ-средств, то можно отметить как постепенно осуществлялся переход от клиент-серверной архитектуры к виртуализации, которая позволила управлять нагрузками, управлять серверами внутри ЦОДов. Затем появились сервисы, позволившие получать виртуальные машины через облака, либо временно размещать нагрузку на облачных платформах. Следующим этапам стал перенос этих нагрузок из виртуальных машин в контейнеры. Эта тенденция постепенно проникает в корпоративную среду, первыми в это направление погрузились разработчики, но очевидно постепенно будет происходить замена процесса виртуализации на контейнеры.
Сегодняшнее мероприятие ведет Александр Шумилин, менеджер по серверным продуктам, Hewlett Packard Enterprise в России.


По словам Александра Шумилина, не все серверы одинаково хорошо и быстро решают задачи заказчиков, грамотный выбор платформ и серверов поможет сэкономить значительные суммы и даст работать долго и надежно.


На этом слайде приведена линейка серверов Hewlett Packard Enterprise, здесь достаточно большой выбор вариантов.
Сервер для виртуализации
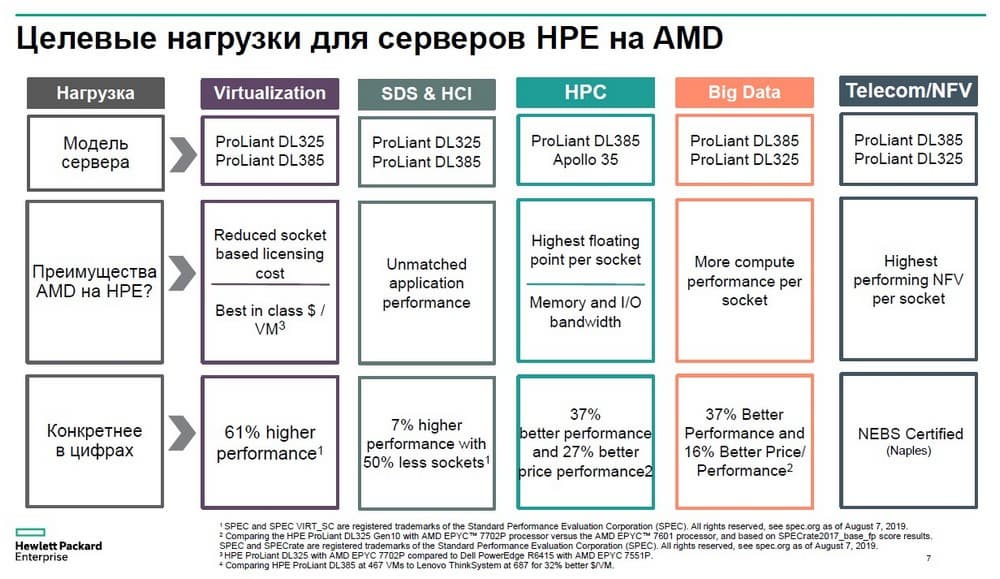
Сервер для виртуализации - это наиболее распространенный формат нагрузки, здесь обычно заказчики используют серверы DL360, DL380, блейды и при этом в основном используют платформы Intel. Некоторые из заказчиков мало знают об альтернативных вариантах, например, серверах на базе процессоров AMD.

Следует обратить серьезное внимание на эту платформу, если перед вами стоит задача дополнительно сэкономить средства на железе. У этого вендора был некоторый перерыв в плане доступности своих серверных процессоров, но теперь на протяжении пары лет они достаточно интенсивно наращивают свое присутствие на серверном рынке. Динамика их взаимодействия с производителями серверов показывает, что это действительно так.
У HPE есть два наиболее массовых сервера – это двухсокетный двухюнитовый сервер в двух вариантах: HPE ProLiant DL385 Gen 10 и относительно недавно вышло обновление, которое получило новые процессоры и более быструю память - HPE ProLiant DL385 Gen 10 Plus. Параллельно с этими серверами продается односокетный одноюнитовый сервер
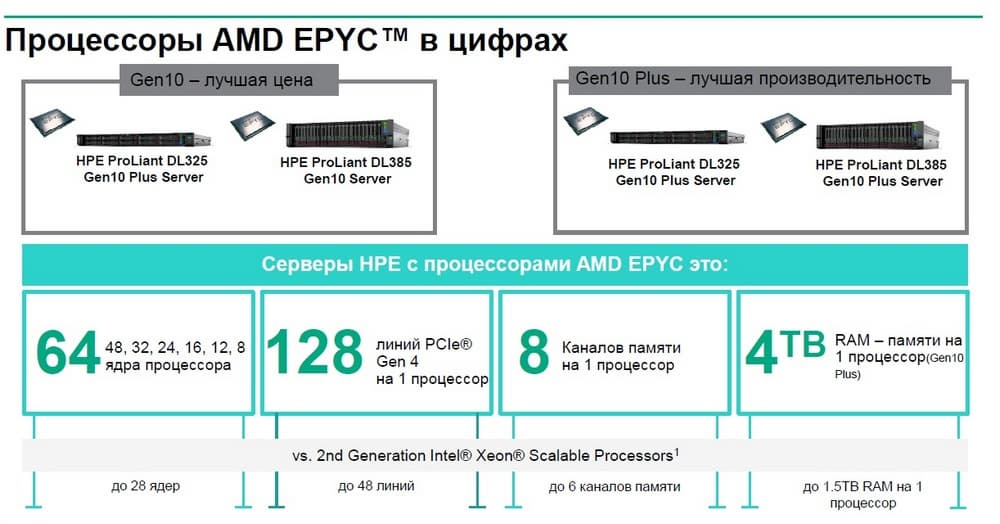
HPE ProLiant DL325 Gen 10 Plus. В чем их выгода по сравнению с серверами на базе процессоров Intel? У Intel в настоящее время из массовых продуктов, которые охлаждаются с помощью воздуха, т.е. не требуют специфичных систем охлаждения, например, на воде, максимальное число ядер, приходящихся на один сокет, составляет 28 штук, при этом у AMD есть 48 и 64 ядер. Кроме этого у AMD значительно более мощная PCI-шина, здесь также можно получить 128 линий 4-го поколения, в то время как у Intel только 48, а количество каналов памяти у Intel – 6 на один процессор, а у AMD - 8. У AMD кроме того больше объем памяти на один сокет, чем у Intel.


Если взять два аналогичных сервера, один на базе процессоров AMD - HPE ProLiant DL385 и сервер другого вендора с процессорами Intel, мы увидим, что удельная стоимость размещения виртуальных машин фактически в два раза ниже на серверах, изготовленных на процессорах AMD. Однако, тут стоит учитывать недавние изменения, которые внесла компания VMware, она ограничила количество ядер на одну лицензию и теперь для того чтобы в полной мере пользоваться техническим преимуществом AMD, необходимо покупать больше лицензий VMware, но даже в этом случае преимущество по стоимости остается.
Что касается конфигурации серверов, то тут много интересных моментов, например, HPE ProLiant DL325 Gen 10 Plus – это односокетная машина, которая по количеству ядер и производительности может соревноваться с двухпроцессорными моделями, созданными на базе процессоров Intel. На следующем слайде изображены комбинации, которые можно получить с точки зрения дискового пространства.
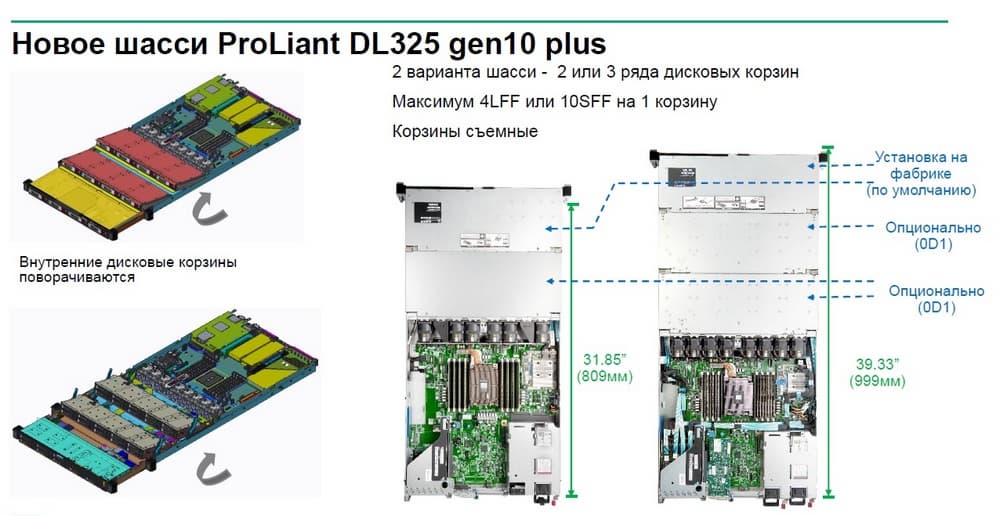

Одно шасси имеет две дисковых корзины, опционально можно добавить еще одну корзину, таким образом получится не просто сервер, а компактная платформа для более интересных нагрузок, чем обычная виртуализация. За счет такой плотности дискового пространства можно строить программно-определяемые системы хранения данных, процессорная мощность и объем памяти говорят, что данные серверы хорошо подойдут для построения вычислительных кластеров, анализа данных, для Big Data, для телеком операторов тоже можно получить преимущества с точки зрения реализации виртуализированного функционала. На AMD можно получить еще больше сервисов на одном сервере.

Процессоры AMD получили большое количество рекордов по различным тестам, их количество превышает 50, причем большая часть рекордов поставлена на серверах HPE.
Расширение применимости контейнерных средств
Если посмотреть на процесс развития ИТ-средств, то можно отметить как постепенно осуществлялся переход от клиент-серверной архитектуры к виртуализации, которая позволила управлять нагрузками, управлять серверами внутри ЦОДов. Затем появились сервисы, позволившие быстро получать такие же виртуальные машины через облака, либо временно размещать свою нагрузку на облачных платформах.
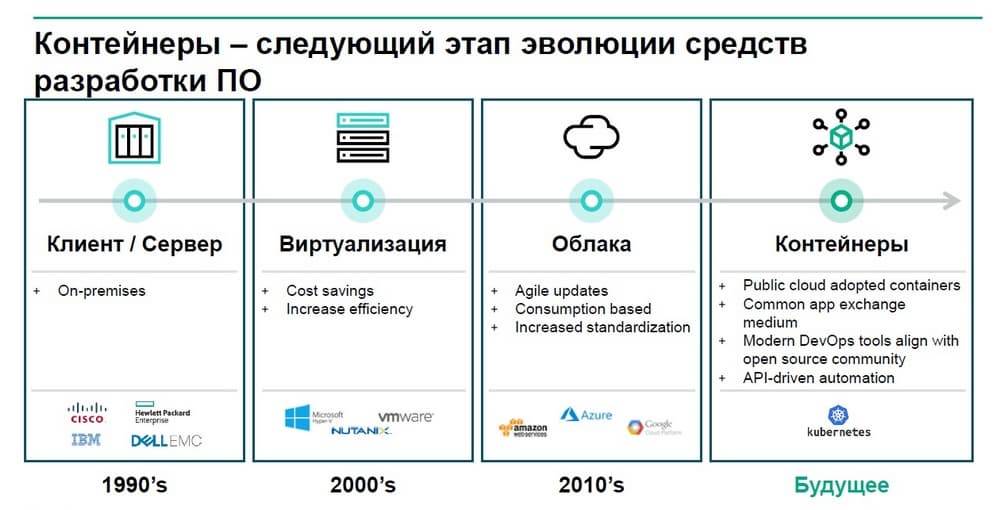

Следующим этапам стал перенос этих нагрузок из формы виртуальных машин в контейнеры. Эта тенденция постепенно из облачных платформ проникает в корпоративную среду, первыми в это направление погрузились разработчики, но очевидно постепенно будет происходить замена процесса виртуализации на контейнеры.
Тем не менее нужно решить много технических вопросов. Заказчиков, естественно, волнует вопрос безопасности, что приводит к тому, что многие активно используя контейнеры, между тем размещают их в виртуальной среде. Тем не менее в любом случае количество внедряемых контейнеров постепенно будем расти.
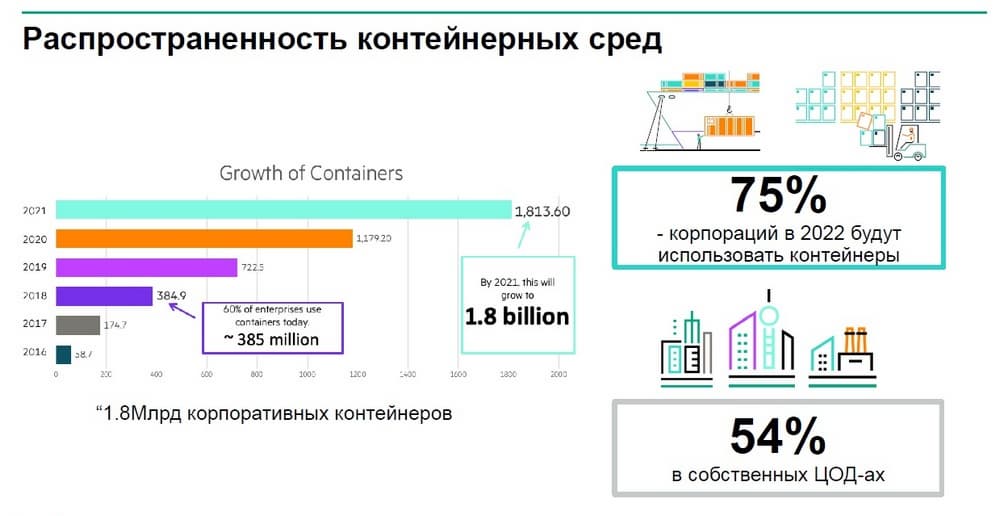

Предполагается что ¾ корпоративных заказчиков через два года будут активно использовать контейнеры, при этом более половины из них будут пользоваться не облачными ресурсами таких монстров как Amazon и Microsoft, а будут разворачиваться в собственных ЦОДах. Можно было бы ожидать, что основная часть этих новых контейнеров будет использоваться для нового софта, для новых сервисов, но если посмотреть на данные аналитиков, то окажется: более половины новых контейнеров разворачивается не для создания новых сервисов и новых услуг, а для модернизации существующих приложений, поскольку управлять монолитными приложениями становится все сложнее.
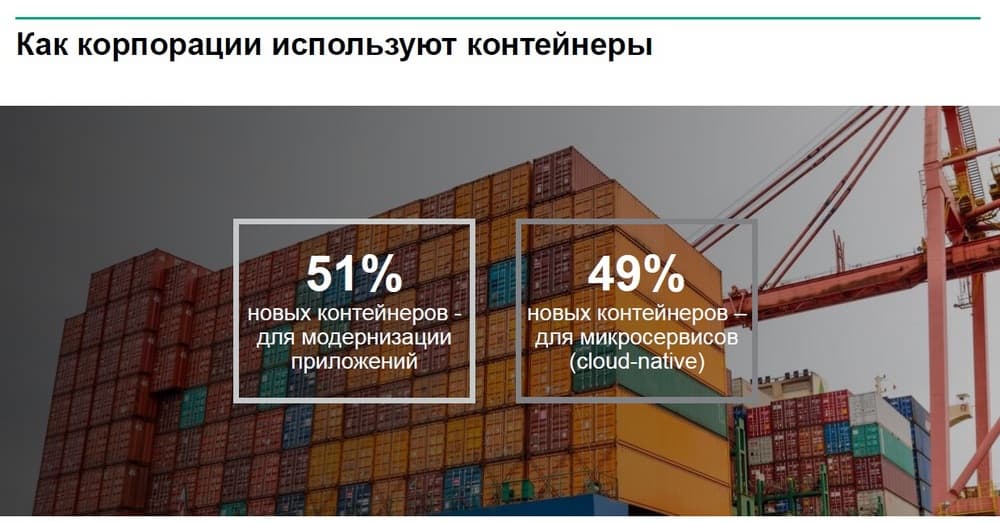

Многие будут развивать свои монолитные приложения используя микросервисы и как раз для этого использовать контейнеры. Основная стратегическая выгода от использования контейнеров – это упрощение обслуживания приложений и адаптация их под меняющиеся внешние условия, нагрузки и т.д.

Если же посмотреть на тактические преимущества, но ИТ избавится от лицензий на виртуализацию, соответственно снизятся требования к оборудованию, поскольку на гипервизор не нужно будет закладывать большие ресурсы процессоров и памяти. Имена каких компаний ассоциируются с контейнерными средами? Это непосредственно docker, который оперирует контейнерами на уровне отдельных узлов, но если речь идет о более глобальной системе кластерного управления, то здесь безусловным лидером, занимающим большую часть рынка, является компания kubenetes.

Имеющиеся встроенные инструменты этого вендора хороши, пока работа осуществляется в рамках среды разработчиков, лабораторий, но как только начинается адаптация контейнеров для внутрикорпоративного применения, то оказывается что еще нужно достаточно большое количество дополнительных инструментов, которые многие заказчики разрабатывают самостоятельно.
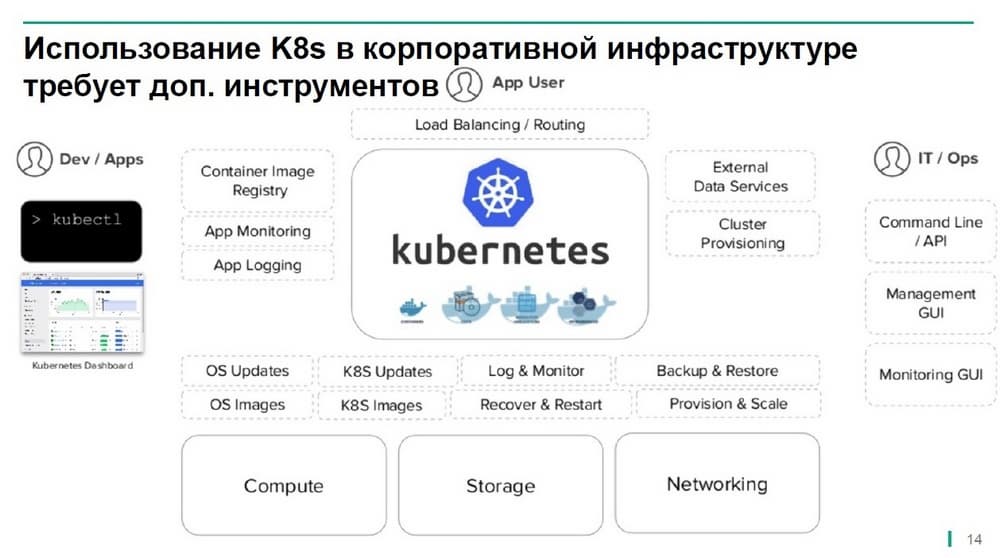

Для этого требуется достаточно большой объем ресурсов и поддерживать эти инструменты достаточно сложно. Для упрощения решения этой задачи компания HPE анонсировала выпуск платформы HPE Container Platform, которая предоставляет собой адаптированную для корпоративного применения оболочку, которую заказчики могут вставить в дополнение к существующей стандартной инсталляции kubenetes.
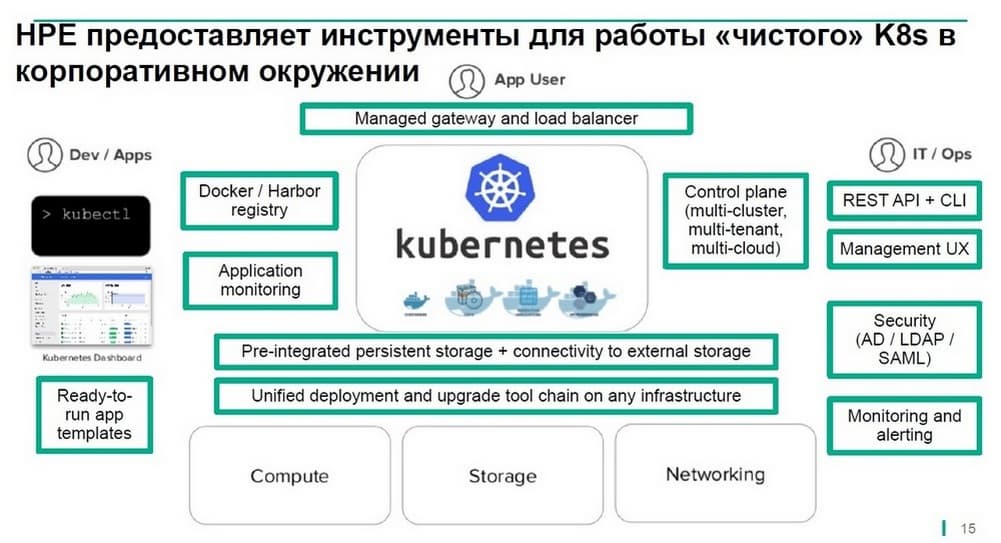

Таким образом в сердце данного решения остается продукт компании kubenetes. В качестве дополнительных ресурсов для управления контейнерами и для обеспечения возможности переносить контейнеры без потери данных с одного физического ресурса на другой, мы используем платформу MAPR. Дополнительные инструменты используются и для обеспечения балансировки нагрузки.
Экономное хранилище
В настоящее время продолжает меняться ландшафт СХД, в итоге все более активно будет реализовываться схема построения двухуровневых систем хранения данных.

Сейчас у заказчиков большая часть приложений работает с использованием уровня Primary Storage, в линейке HPE – это системы Nimble, 3PAR, Primera. И порядка 40% данных хранятся в относительно медленных системах хранения - Secondary Storage.
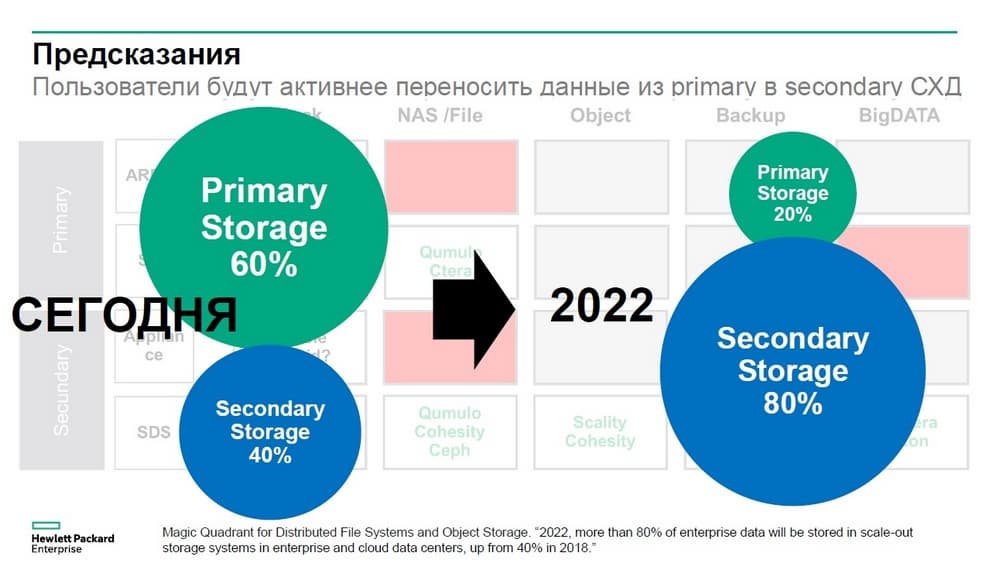

Предполагается, буквально через два года это соотношение изменится и перейдет с 60% к 40% и мы увидим, что классические корпоративные системы хранения данных займут только 20% от хранимого объема данных, в то время как Secondary Storage – это СХД для приложений не чувствительных к задержкам будут занимать 80%. К чему это приведет?
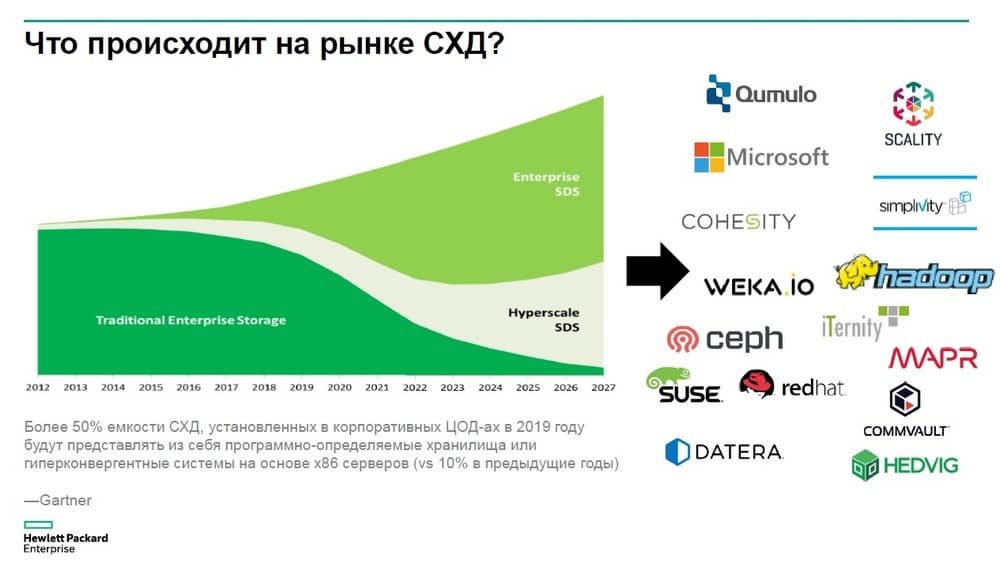

Мы увидим, что на рынке все более активно будут появляться новые решения по построению программно-определяемых системы хранения данных, которые в качестве железа будут использовать относительно дешевые серверы на базе также относительно дешевых SAS-дисков. Если посмотреть на портфель HPE, то такой софт у вендора есть - это Scality, Cohesity и другое программное обеспечение, указанное на предыдущем слайде, решения, доступные в портфеле HPE, среди них и собственные продукты вендора – MAPR, Simplivity.
Какое железо необходимо для программно-определяемых СХД


Здесь имеет смысл использовать серверы Apollo 4000. Конечно можно воспользоваться и DL380 с дисками LFF. В некоторых решениях это имеет смысл, но если оценить массовую инсталляцию на самые большие проекты, которые в этой области мы реализуем, то большинство из них построены на серверах линейки Apollo 4000.
Apollo 4200 – это привычный DL380 только у него есть два дисковых блока, есть вариант с дисками LFF - две корзины по 12 дисков, спереди доступны 24 диска LFF и несколько дисков можно установить в корзину с задней стороны сервера. Есть другой вариант с дисками SFА – две корзины по 24 диска, 48 дисков доступны спереди плюс пара дисков сзади для операционной системы. Помещаются они в стойку стандартной глубины, многие заказчики используют их для файловых хранилищ с не очень плотным хранением данных, но если данных много и нужно их разместить еще плотнее в одной стойке, то здесь подойдет сервер Apollo 4510 – это четырехюнитовое устройства, у которого есть возможность установки до 60 дисков формата LFF. Эта система хорошо подходит для активных архивов, для активного накопления медицинской информации, в том числе медицинских снимков.
Уменьшаем большие данные
Пример из аналитики Big Data. Классическая архитектура Hadoop представляет собой систему, в которой берутся десятки или сотни серверов идентичной конфигурации, чаще всего это двухюнитовые серверы типа DL380 с дисками LFF и на каждом из этих серверов выполняется функция хранения и вычисления, которые раздает управляющий узел.
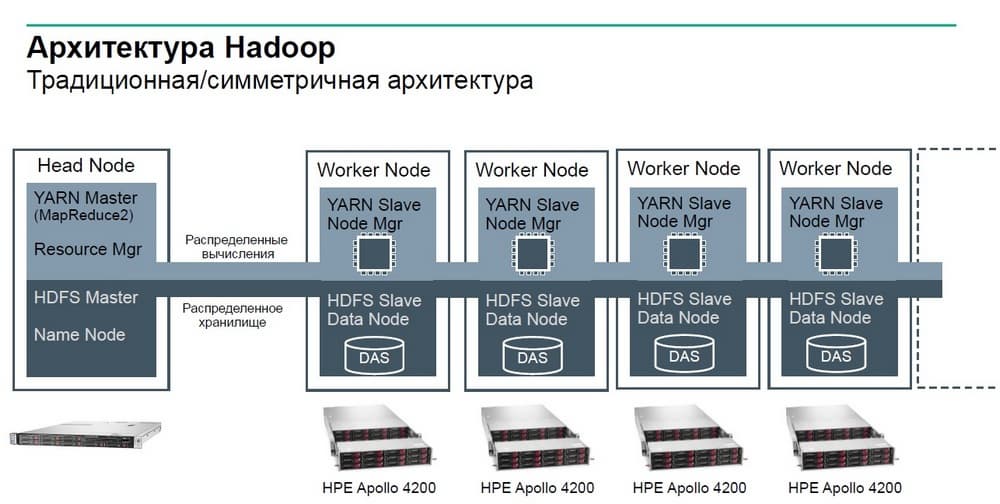

Эта архитектура с симметричным построением кластера для Big Data была актуальна более 10 лет назад. В современной действительности сеть перестала быть узким местом, когда скорости сетевых подключений выросли до десятков и сотен гигабит в секунду, становится достаточно эффективным следующая схема: мы можем разнести на отдельные физические устройства те задачи, которые мы ставили вместе на отдельные серверы.
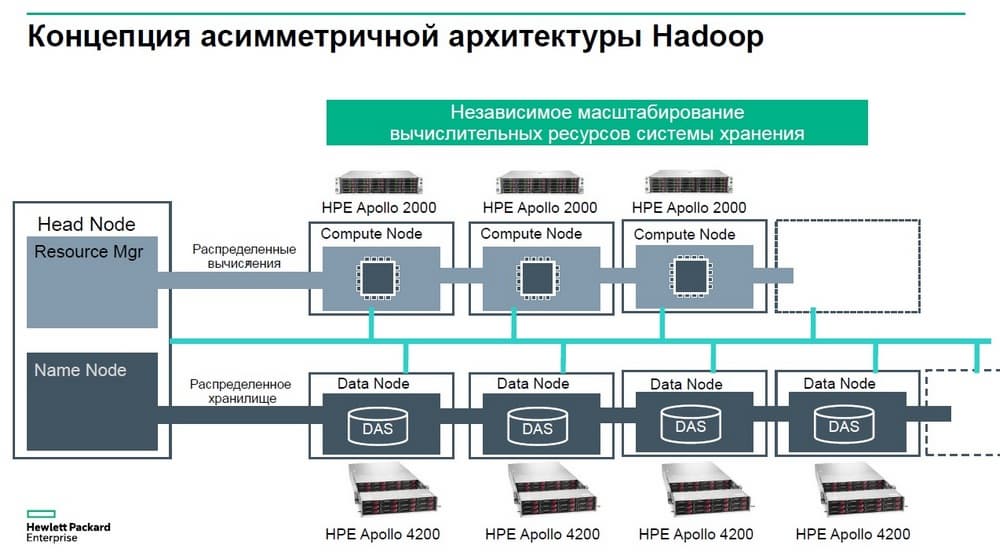

Вычисления может выполнять на специализированных серверах, которые лучше подходят для такого типа задач, а задачу хранения возложить на серверы, которые лучше подходят именно для хранения. Что дает такая архитектура?
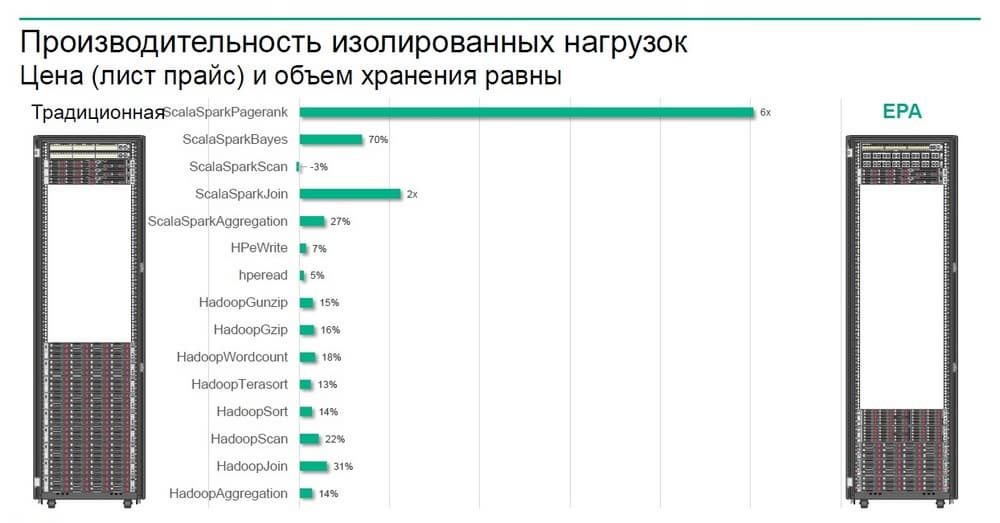

На примере, приведенном на слайде, слева изображен кластер, построенный по традиционной схеме с использованием симметричных узлов типа двухюнитовых серверов типа DL380, а с другой стороны – кластер, построенный по принципу разделения узлов по функциям: узлы вычислительные и узлы хранения. Для многих задач, для многих типов нагрузок по анализу данных мы видим прирост производительности за те же деньги – на 15-20%, а для некоторых задач в 2 или даже в 6 раз.
Далее идет слайд проекта, реализованного у одного из заказчиков HPE, с использованием специализированных платформ.


Здесь имеется в виду информационное обеспечение гонок «Формула-1». Во время гонок для каждой команды ограничивается подача электроэнергии, чтобы не превращать гонку в соревнование роботов и программистов. Таким образом у каждой команды ограничен вычислительный ресурс и для того чтобы наиболее эффективно выполнять задачи по управлению, по обработке информации во время гонки, команды вынуждены оптимизировать свои вычислительные платформы и использовать те серверы, которые хорошо справляются с нагрузкой, но при этом они и максимально энергоэффективны. У HPE такой платформой является система Moonshot m510, ее используют не менее 6 из 10 команд «Формула-1». Данная платформа решает задачи высокоплотных вычислений с низкими задержками для машинного обучения, для построения моделей искусственного интеллекта, поэтому здесь используются специализированные платформы Apollo 2000 с графическим ускорителями nVideo, а управление реализуется на базе привычных виртуальных машин, развернутых на блейдах. Для хранения данных используется Apollo 4200 для регулярно поступающих данных, а для остывающих данных используется более плотная дисковая система на Apollo 4510.
Повышение эффективности установленных у заказчиков систем
HPE InfoSight – это аналитическая система, которую HPE получилf за счет приобретения компании Nimble, ориентированной на системы хранения данных. Теперь же HPE распространяет аналитику InfoSight и на другие системы, в том числе на 3PAR и Primera.
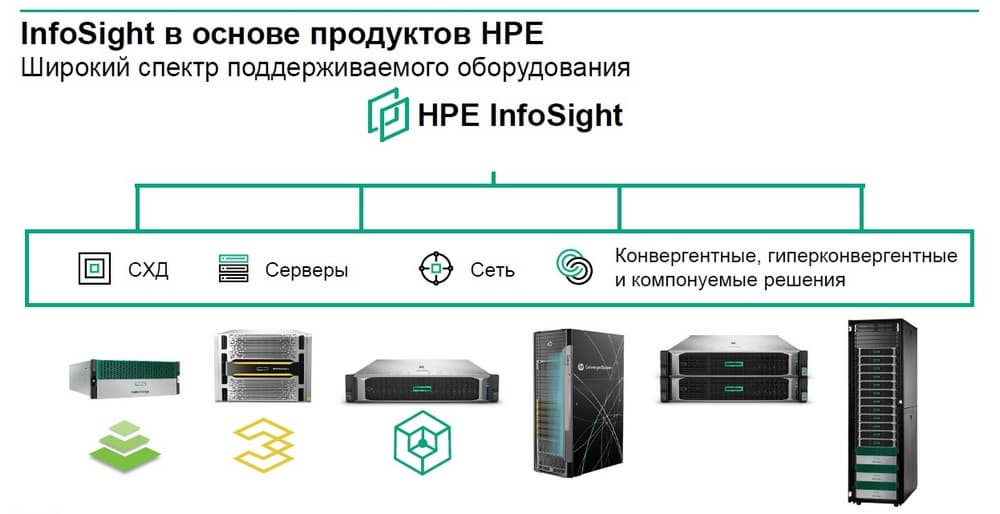

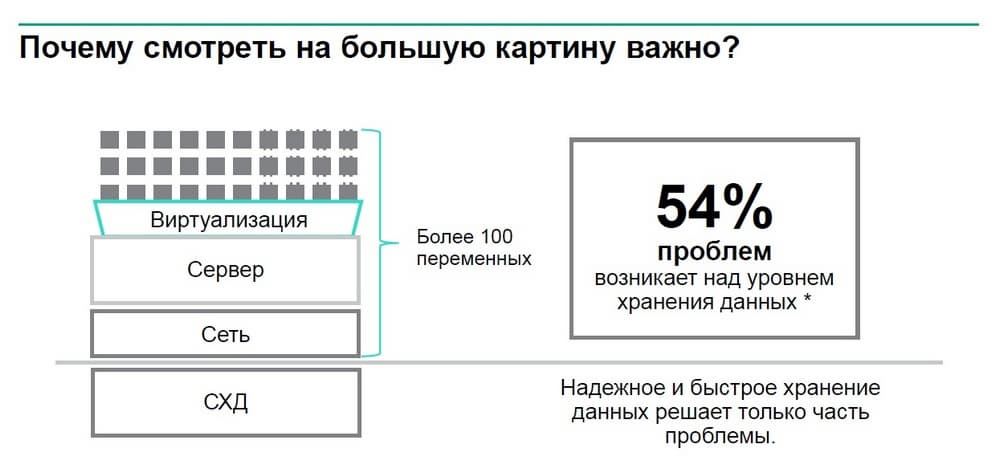
Использование InfoSight становится стандартным инструментом, повышающим эффективность решения сервисных задач. Когда строилось решение Nimble, оказалось что более половины проблем, влияющих на производительность СХД и на доступность данных, лежит вне самой системы хранения данных, эти проблемы привносят какие-то технические недостатки систем другого уровня, это может быть сеть, физический сервер и многое другое.

Почему HPE использует искусственный интеллект, а не применяет просто запрограммированную платформу? На следующем слайде представлены типы проблем и частота их появления.
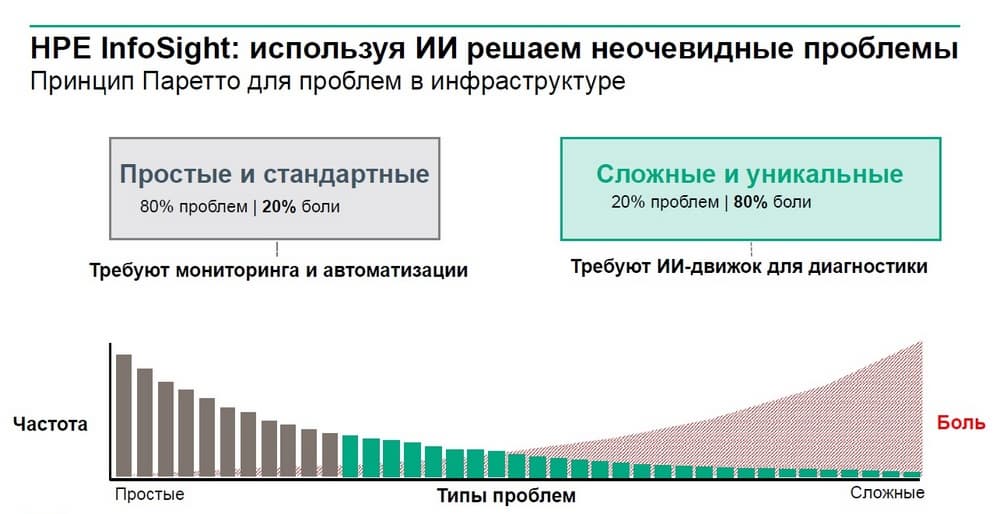

И оказывается, чем реже проблема проявляется, тем тяжелее ее диагностировать и тем более сложным будет процесс поиска решения данного типа кейса. Именно ИИ помогает быстро и проактивно решать такие проблемы.
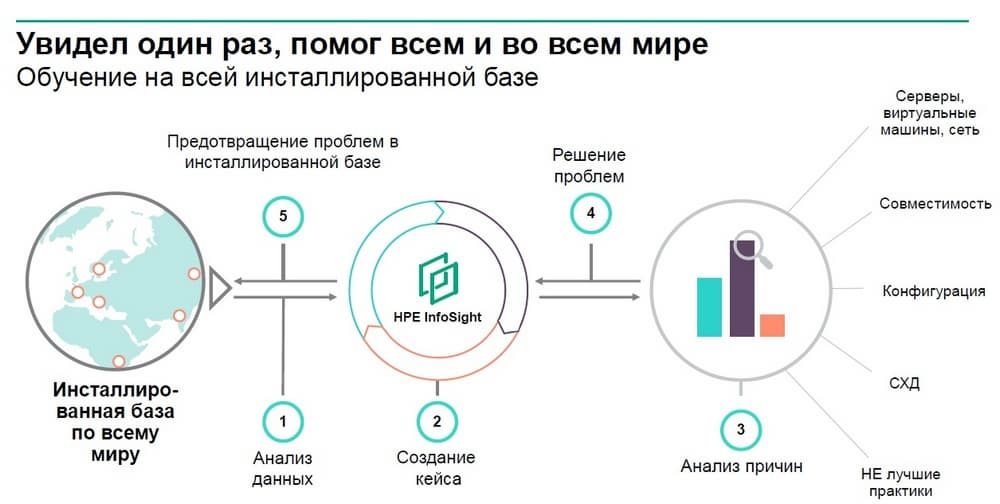

Есть инсталлированная база оборудования по всему миру, HPE InfoSight собирает аналитику от каждой установленной системы и регулярно проводится анализ на поиск паттернов похожих на те кейсы, которые уже были идентифицированы службой поддержки. Проводится анализ причин и если обнаруживается конфигурация либо сочетание технических характеристик у группы заказчиков, которое ранее приводило к проблемам, то таким заказчикам проактивно предлагается решение.
Скажем HPE InfoSight года 1,5 назад смог отловить проблему в драйверах VMware.


Оказалось, что EXS некорректно отвечал на SCSI-запросы, что увеличивало количество запросов на запись.
Система HPE InfoSight смогла отловить даже проблемы с кондиционером.

